 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Behaviour Spaces
Apr 27, 2026Recent work in hierarchical reinforcement learning has shown success in scaling to billions of timesteps when learning over a set of predefined option reward functions. We show that, instead of using a single reward function per option, the reward functions can be effectively used to induce a space of behaviours, by letting the controller specify linear combinations over reward functions, allowing a more expressive set of policies to be represented. We call this method Hierarchical Behaviour Spaces (HBS). We evaluate HBS on the NetHack Learning Environment, demonstrating strong performance. We conduct a series of experiments and determine that, perhaps going against conventional wisdom, the benefits of hierarchy in our method come from increased exploration rather than long term reasoning.
DigiData: Training and Evaluating General-Purpose Mobile Control Agents
Nov 11, 2025AI agents capable of controlling user interfaces have the potential to transform human interaction with digital devices. To accelerate this transformation, two fundamental building blocks are essential: high-quality datasets that enable agents to achieve complex and human-relevant goals, and robust evaluation methods that allow researchers and practitioners to rapidly enhance agent performance. In this paper, we introduce DigiData, a large-scale, high-quality, diverse, multi-modal dataset designed for training mobile control agents. Unlike existing datasets, which derive goals from unstructured interactions, DigiData is meticulously constructed through comprehensive exploration of app features, resulting in greater diversity and higher goal complexity. Additionally, we present DigiData-Bench, a benchmark for evaluating mobile control agents on real-world complex tasks. We demonstrate that the commonly used step-accuracy metric falls short in reliably assessing mobile control agents and, to address this, we propose dynamic evaluation protocols and AI-powered evaluations as rigorous alternatives for agent assessment. Our contributions aim to significantly advance the development of mobile control agents, paving the way for more intuitive and effective human-device interactions.
Mol-MoE: Training Preference-Guided Routers for Molecule Generation
Feb 08, 2025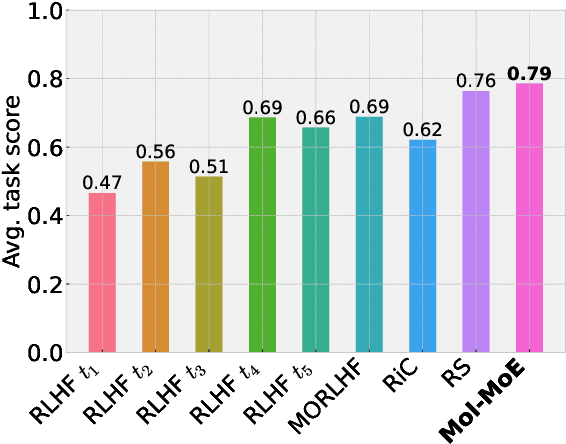
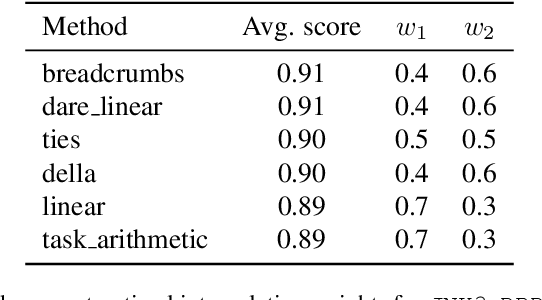
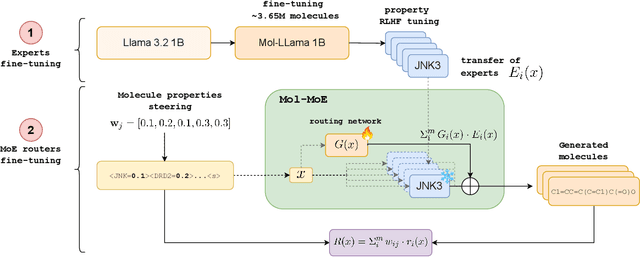

Recent advances in language models have enabled framing molecule generation as sequence modeling. However, existing approaches often rely on single-objective reinforcement learning, limiting their applicability to real-world drug design, where multiple competing properties must be optimized. Traditional multi-objective reinforcement learning (MORL) methods require costly retraining for each new objective combination, making rapid exploration of trade-offs impractical. To overcome these limitations, we introduce Mol-MoE, a mixture-of-experts (MoE) architecture that enables efficient test-time steering of molecule generation without retraining. Central to our approach is a preference-based router training objective that incentivizes the router to combine experts in a way that aligns with user-specified trade-offs. This provides improved flexibility in exploring the chemical property space at test time, facilitating rapid trade-off exploration. Benchmarking against state-of-the-art methods, we show that Mol-MoE achieves superior sample quality and steerability.
Towards General-Purpose Model-Free Reinforcement Learning
Jan 27, 2025



Reinforcement learning (RL) promises a framework for near-universal problem-solving. In practice however, RL algorithms are often tailored to specific benchmarks, relying on carefully tuned hyperparameters and algorithmic choices. Recently, powerful model-based RL methods have shown impressive general results across benchmarks but come at the cost of increased complexity and slow run times, limiting their broader applicability. In this paper, we attempt to find a unifying model-free deep RL algorithm that can address a diverse class of domains and problem settings. To achieve this, we leverage model-based representations that approximately linearize the value function, taking advantage of the denser task objectives used by model-based RL while avoiding the costs associated with planning or simulated trajectories. We evaluate our algorithm, MR.Q, on a variety of common RL benchmarks with a single set of hyperparameters and show a competitive performance against domain-specific and general baselines, providing a concrete step towards building general-purpose model-free deep RL algorithms.
MaestroMotif: Skill Design from Artificial Intelligence Feedback
Dec 11, 2024
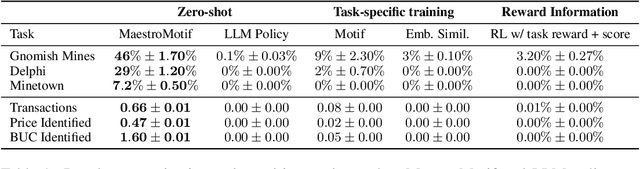

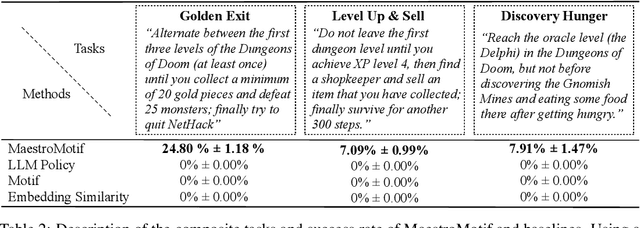
Describing skills in natural language has the potential to provide an accessible way to inject human knowledge about decision-making into an AI system. We present MaestroMotif, a method for AI-assisted skill design, which yields high-performing and adaptable agents. MaestroMotif leverages the capabilities of Large Language Models (LLMs) to effectively create and reuse skills. It first uses an LLM's feedback to automatically design rewards corresponding to each skill, starting from their natural language description. Then, it employs an LLM's code generation abilities, together with reinforcement learning, for training the skills and combining them to implement complex behaviors specified in language. We evaluate MaestroMotif using a suite of complex tasks in the NetHack Learning Environment (NLE), demonstrating that it surpasses existing approaches in both performance and usability.
Controlling Large Language Model Agents with Entropic Activation Steering
Jun 01, 2024The generality of pretrained large language models (LLMs) has prompted increasing interest in their use as in-context learning agents. To be successful, such agents must form beliefs about how to achieve their goals based on limited interaction with their environment, resulting in uncertainty about the best action to take at each step. In this paper, we study how LLM agents form and act on these beliefs by conducting experiments in controlled sequential decision-making tasks. To begin, we find that LLM agents are overconfident: They draw strong conclusions about what to do based on insufficient evidence, resulting in inadequately explorative behavior. We dig deeper into this phenomenon and show how it emerges from a collapse in the entropy of the action distribution implied by sampling from the LLM. We then demonstrate that existing token-level sampling techniques are by themselves insufficient to make the agent explore more. Motivated by this fact, we introduce Entropic Activation Steering (EAST), an activation steering method for in-context LLM agents. EAST computes a steering vector as an entropy-weighted combination of representations, and uses it to manipulate an LLM agent's uncertainty over actions by intervening on its activations during the forward pass. We show that EAST can reliably increase the entropy in an LLM agent's actions, causing more explorative behavior to emerge. Finally, EAST modifies the subjective uncertainty an LLM agent expresses, paving the way to interpreting and controlling how LLM agents represent uncertainty about their decisions.
The Curse of Diversity in Ensemble-Based Exploration
May 07, 2024


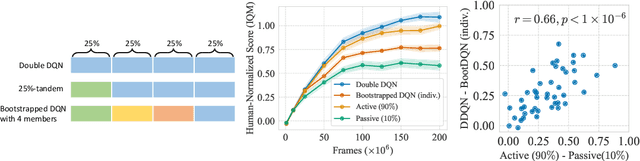
We uncover a surprising phenomenon in deep reinforcement learning: training a diverse ensemble of data-sharing agents -- a well-established exploration strategy -- can significantly impair the performance of the individual ensemble members when compared to standard single-agent training. Through careful analysis, we attribute the degradation in performance to the low proportion of self-generated data in the shared training data for each ensemble member, as well as the inefficiency of the individual ensemble members to learn from such highly off-policy data. We thus name this phenomenon the curse of diversity. We find that several intuitive solutions -- such as a larger replay buffer or a smaller ensemble size -- either fail to consistently mitigate the performance loss or undermine the advantages of ensembling. Finally, we demonstrate the potential of representation learning to counteract the curse of diversity with a novel method named Cross-Ensemble Representation Learning (CERL) in both discrete and continuous control domains. Our work offers valuable insights into an unexpected pitfall in ensemble-based exploration and raises important caveats for future applications of similar approaches.
Maxwell's Demon at Work: Efficient Pruning by Leveraging Saturation of Neurons
Mar 12, 2024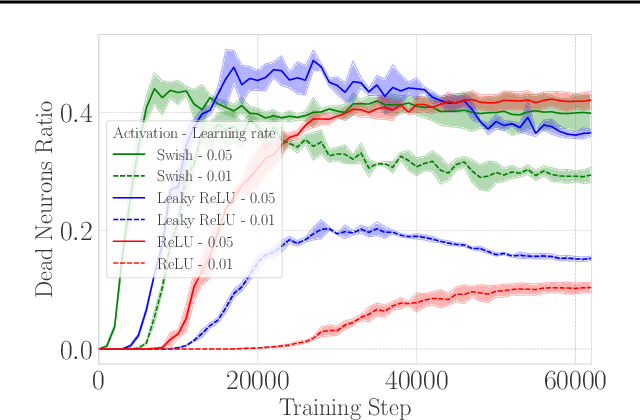
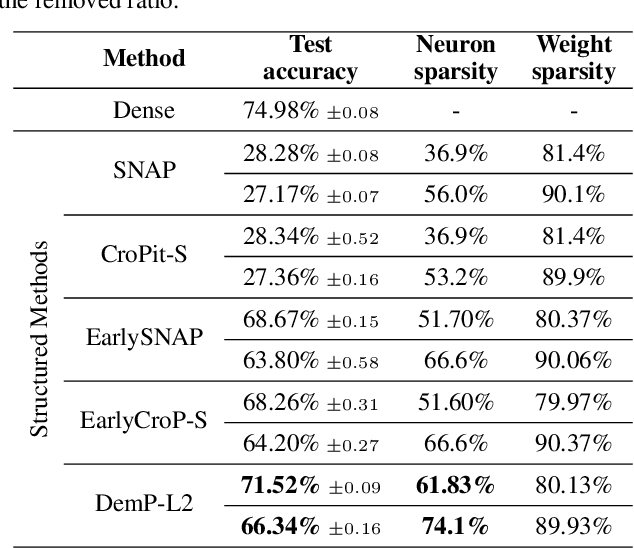
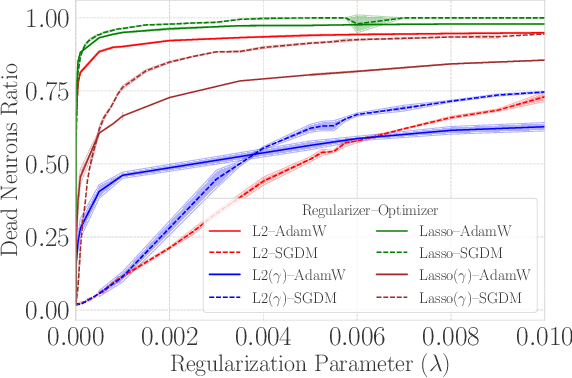
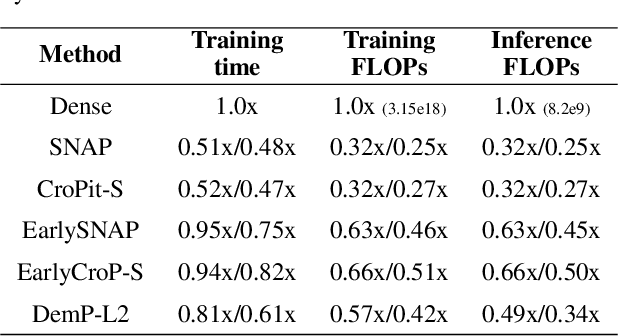
When training deep neural networks, the phenomenon of $\textit{dying neurons}$ $\unicode{x2013}$units that become inactive or saturated, output zero during training$\unicode{x2013}$ has traditionally been viewed as undesirable, linked with optimization challenges, and contributing to plasticity loss in continual learning scenarios. In this paper, we reassess this phenomenon, focusing on sparsity and pruning. By systematically exploring the impact of various hyperparameter configurations on dying neurons, we unveil their potential to facilitate simple yet effective structured pruning algorithms. We introduce $\textit{Demon Pruning}$ (DemP), a method that controls the proliferation of dead neurons, dynamically leading to network sparsity. Achieved through a combination of noise injection on active units and a one-cycled schedule regularization strategy, DemP stands out for its simplicity and broad applicability. Experiments on CIFAR10 and ImageNet datasets demonstrate that DemP surpasses existing structured pruning techniques, showcasing superior accuracy-sparsity tradeoffs and training speedups. These findings suggest a novel perspective on dying neurons as a valuable resource for efficient model compression and optimization.
Do Transformer World Models Give Better Policy Gradients?
Feb 11, 2024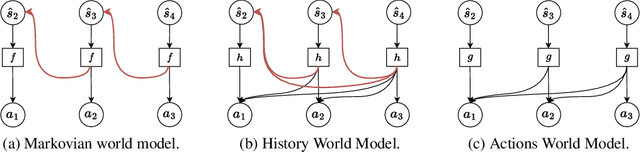

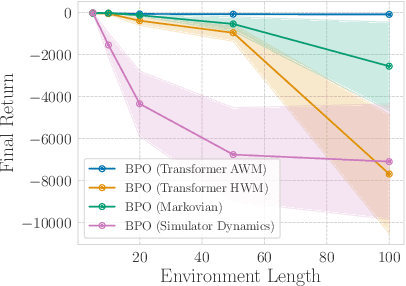

A natural approach for reinforcement learning is to predict future rewards by unrolling a neural network world model, and to backpropagate through the resulting computational graph to learn a policy. However, this method often becomes impractical for long horizons since typical world models induce hard-to-optimize loss landscapes. Transformers are known to efficiently propagate gradients over long horizons: could they be the solution to this problem? Surprisingly, we show that commonly-used transformer world models produce circuitous gradient paths, which can be detrimental to long-range policy gradients. To tackle this challenge, we propose a class of world models called Actions World Models (AWMs), designed to provide more direct routes for gradient propagation. We integrate such AWMs into a policy gradient framework that underscores the relationship between network architectures and the policy gradient updates they inherently represent. We demonstrate that AWMs can generate optimization landscapes that are easier to navigate even when compared to those from the simulator itself. This property allows transformer AWMs to produce better policies than competitive baselines in realistic long-horizon tasks.
Motif: Intrinsic Motivation from Artificial Intelligence Feedback
Sep 29, 2023



Exploring rich environments and evaluating one's actions without prior knowledge is immensely challenging. In this paper, we propose Motif, a general method to interface such prior knowledge from a Large Language Model (LLM) with an agent. Motif is based on the idea of grounding LLMs for decision-making without requiring them to interact with the environment: it elicits preferences from an LLM over pairs of captions to construct an intrinsic reward, which is then used to train agents with reinforcement learning. We evaluate Motif's performance and behavior on the challenging, open-ended and procedurally-generated NetHack game. Surprisingly, by only learning to maximize its intrinsic reward, Motif achieves a higher game score than an algorithm directly trained to maximize the score itself. When combining Motif's intrinsic reward with the environment reward, our method significantly outperforms existing approaches and makes progress on tasks where no advancements have ever been made without demonstrations. Finally, we show that Motif mostly generates intuitive human-aligned behaviors which can be steered easily through prompt modifications, while scaling well with the LLM size and the amount of information given in the prompt.