 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingLanMiDian: Systematic Evaluation of LLMs on TCM Knowledge and Clinical Reasoning
Feb 02, 2026Large language models (LLMs) are advancing rapidly in medical NLP, yet Traditional Chinese Medicine (TCM) with its distinctive ontology, terminology, and reasoning patterns requires domain-faithful evaluation. Existing TCM benchmarks are fragmented in coverage and scale and rely on non-unified or generation-heavy scoring that hinders fair comparison. We present the LingLanMiDian (LingLan) benchmark, a large-scale, expert-curated, multi-task suite that unifies evaluation across knowledge recall, multi-hop reasoning, information extraction, and real-world clinical decision-making. LingLan introduces a consistent metric design, a synonym-tolerant protocol for clinical labels, a per-dataset 400-item Hard subset, and a reframing of diagnosis and treatment recommendation into single-choice decision recognition. We conduct comprehensive, zero-shot evaluations on 14 leading open-source and proprietary LLMs, providing a unified perspective on their strengths and limitations in TCM commonsense knowledge understanding, reasoning, and clinical decision support; critically, the evaluation on Hard subset reveals a substantial gap between current models and human experts in TCM-specialized reasoning. By bridging fundamental knowledge and applied reasoning through standardized evaluation, LingLan establishes a unified, quantitative, and extensible foundation for advancing TCM LLMs and domain-specific medical AI research. All evaluation data and code are available at https://github.com/TCMAI-BJTU/LingLan and http://tcmnlp.com.
CAPT: Contrastive Pre-Training for Learning Denoised Sequence Representations
Oct 30, 2020
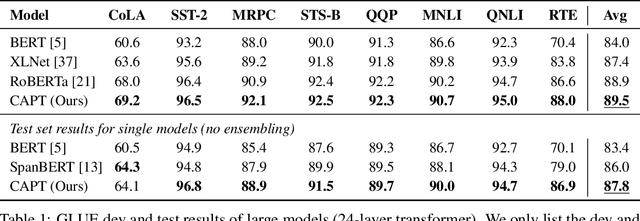
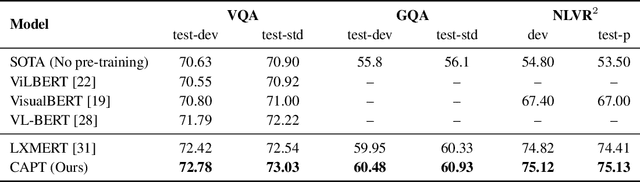
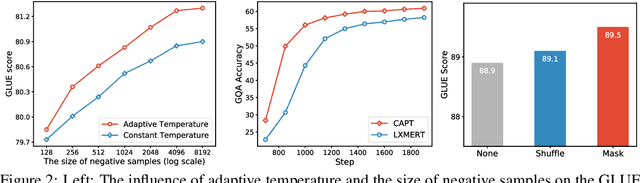
Pre-trained self-supervised models such as BERT have achieved striking success in learning sequence representations, especially for natural language processing. These models typically corrupt the given sequences with certain types of noise, such as masking, shuffling, or substitution, and then try to recover the original input. However, such pre-training approaches are prone to learning representations that are covariant with the noise, leading to the discrepancy between the pre-training and fine-tuning stage. To remedy this, we present ContrAstive Pre-Training (CAPT) to learn noise invariant sequence representations. The proposed CAPT encourages the consistency between representations of the original sequence and its corrupted version via unsupervised instance-wise training signals. In this way, it not only alleviates the pretrain-finetune discrepancy induced by the noise of pre-training, but also aids the pre-trained model in better capturing global semantics of the input via more effective sentence-level supervision. Different from most prior work that focuses on a particular modality, comprehensive empirical evidence on 11 natural language understanding and cross-modal tasks illustrates that CAPT is applicable for both language and vision-language tasks, and obtains surprisingly consistent improvement, including 0.6\% absolute gain on GLUE benchmarks and 0.8\% absolute increment on $\text{NLVR}^2$.
Inductively Representing Out-of-Knowledge-Graph Entities by Optimal Estimation Under Translational Assumptions
Sep 27, 2020



Conventional Knowledge Graph Completion (KGC) assumes that all test entities appear during training. However, in real-world scenarios, Knowledge Graphs (KG) evolve fast with out-of-knowledge-graph (OOKG) entities added frequently, and we need to represent these entities efficiently. Most existing Knowledge Graph Embedding (KGE) methods cannot represent OOKG entities without costly retraining on the whole KG. To enhance efficiency, we propose a simple and effective method that inductively represents OOKG entities by their optimal estimation under translational assumptions. Given pretrained embeddings of the in-knowledge-graph (IKG) entities, our method needs no additional learning. Experimental results show that our method outperforms the state-of-the-art methods with higher efficiency on two KGC tasks with OOKG entities.
Visual Agreement Regularized Training for Multi-Modal Machine Translation
Dec 27, 2019


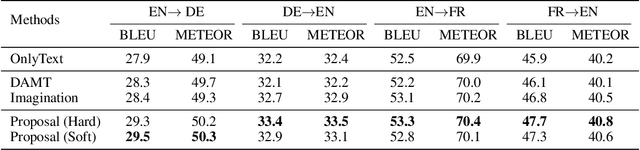
Multi-modal machine translation aims at translating the source sentence into a different language in the presence of the paired image. Previous work suggests that additional visual information only provides dispensable help to translation, which is needed in several very special cases such as translating ambiguous words. To make better use of visual information, this work presents visual agreement regularized training. The proposed approach jointly trains the source-to-target and target-to-source translation models and encourages them to share the same focus on the visual information when generating semantically equivalent visual words (e.g. "ball" in English and "ballon" in French). Besides, a simple yet effective multi-head co-attention model is also introduced to capture interactions between visual and textual features. The results show that our approaches can outperform competitive baselines by a large margin on the Multi30k dataset. Further analysis demonstrates that the proposed regularized training can effectively improve the agreement of attention on the image, leading to better use of visual information.
Pun-GAN: Generative Adversarial Network for Pun Generation
Oct 24, 2019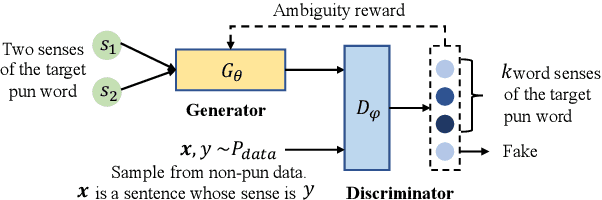
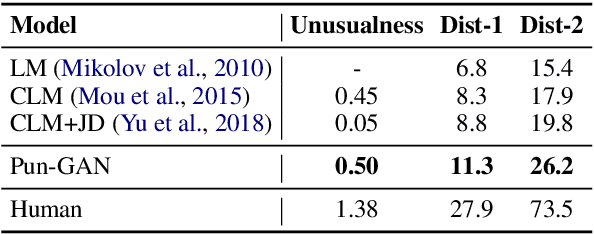
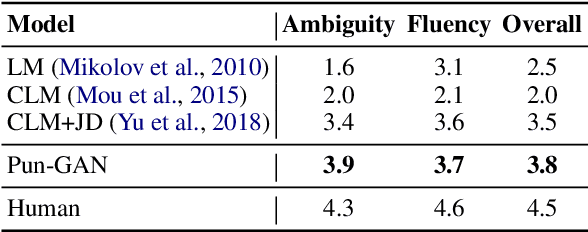
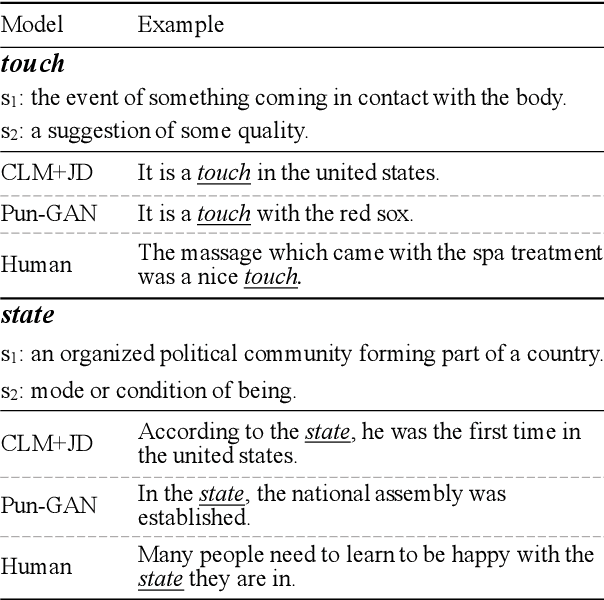
In this paper, we focus on the task of generating a pun sentence given a pair of word senses. A major challenge for pun generation is the lack of large-scale pun corpus to guide the supervised learning. To remedy this, we propose an adversarial generative network for pun generation (Pun-GAN), which does not require any pun corpus. It consists of a generator to produce pun sentences, and a discriminator to distinguish between the generated pun sentences and the real sentences with specific word senses. The output of the discriminator is then used as a reward to train the generator via reinforcement learning, encouraging it to produce pun sentences that can support two word senses simultaneously. Experiments show that the proposed Pun-GAN can generate sentences that are more ambiguous and diverse in both automatic and human evaluation.
Key Fact as Pivot: A Two-Stage Model for Low Resource Table-to-Text Generation
Aug 08, 2019
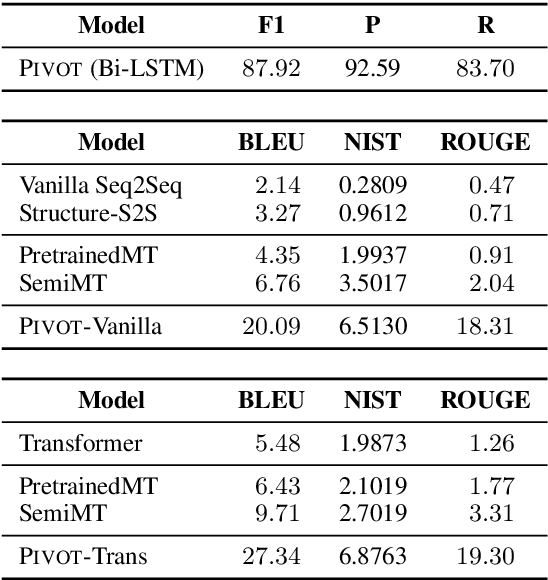

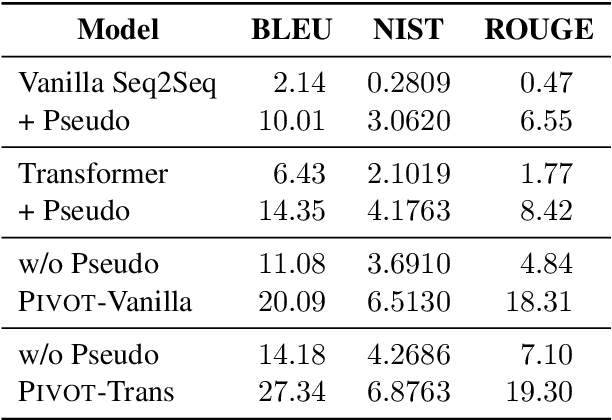
Table-to-text generation aims to translate the structured data into the unstructured text. Most existing methods adopt the encoder-decoder framework to learn the transformation, which requires large-scale training samples. However, the lack of large parallel data is a major practical problem for many domains. In this work, we consider the scenario of low resource table-to-text generation, where only limited parallel data is available. We propose a novel model to separate the generation into two stages: key fact prediction and surface realization. It first predicts the key facts from the tables, and then generates the text with the key facts. The training of key fact prediction needs much fewer annotated data, while surface realization can be trained with pseudo parallel corpus. We evaluate our model on a biography generation dataset. Our model can achieve $27.34$ BLEU score with only $1,000$ parallel data, while the baseline model only obtain the performance of $9.71$ BLEU score.
Automatic Generation of Personalized Comment Based on User Profile
Jul 24, 2019



Comments on social media are very diverse, in terms of content, style and vocabulary, which make generating comments much more challenging than other existing natural language generation~(NLG) tasks. Besides, since different user has different expression habits, it is necessary to take the user's profile into consideration when generating comments. In this paper, we introduce the task of automatic generation of personalized comment~(AGPC) for social media. Based on tens of thousands of users' real comments and corresponding user profiles on weibo, we propose Personalized Comment Generation Network~(PCGN) for AGPC. The model utilizes user feature embedding with a gated memory and attends to user description to model personality of users. In addition, external user representation is taken into consideration during the decoding to enhance the comments generation. Experimental results show that our model can generate natural, human-like and personalized comments.
Memorized Sparse Backpropagation
Jun 01, 2019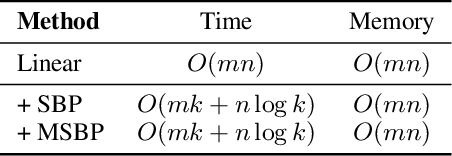

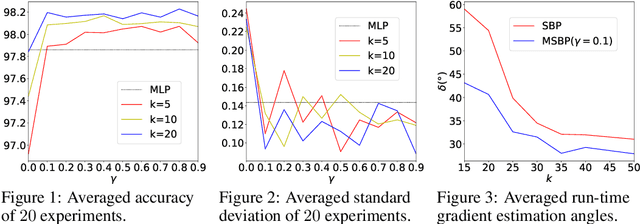
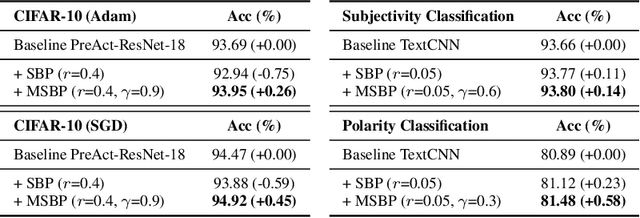
Neural network learning is typically slow since backpropagation needs to compute full gradients and backpropagate them across multiple layers. Despite its success of existing work in accelerating propagation through sparseness, the relevant theoretical characteristics remain unexplored and we empirically find that they suffer from the loss of information contained in unpropagated gradients. To tackle these problems, in this work, we present a unified sparse backpropagation framework and provide a detailed analysis of its theoretical characteristics. Analysis reveals that when applied to a multilayer perceptron, our framework essentially performs gradient descent using an estimated gradient similar enough to the true gradient, resulting in convergence in probability under certain conditions. Furthermore, a simple yet effective algorithm named memorized sparse backpropagation (MSBP) is proposed to remedy the problem of information loss by storing unpropagated gradients in memory for the next learning. The experiments demonstrate that the proposed MSBP is able to effectively alleviate the information loss in traditional sparse backpropagation while achieving comparable acceleration.
A Dual Reinforcement Learning Framework for Unsupervised Text Style Transfer
May 24, 2019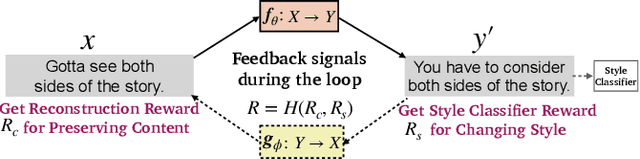
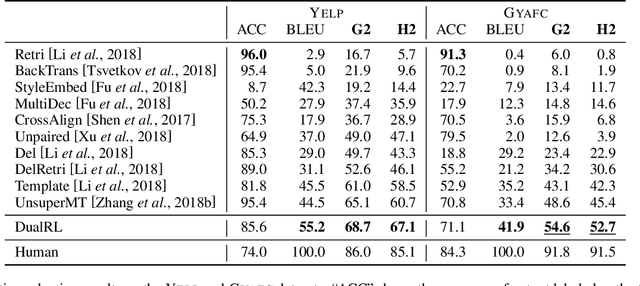
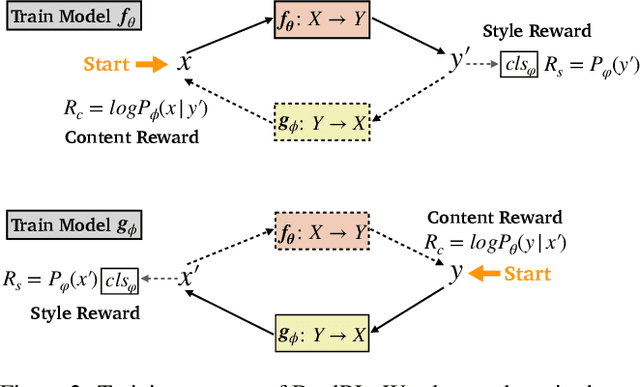
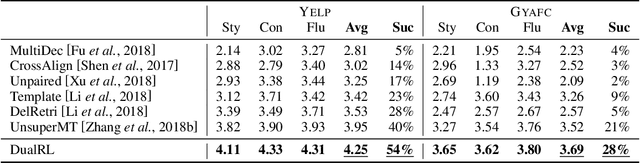
Unsupervised text style transfer aims to transfer the underlying style of text but keep its main content unchanged without parallel data. Most existing methods typically follow two steps: first separating the content from the original style, and then fusing the content with the desired style. However, the separation in the first step is challenging because the content and style interact in subtle ways in natural language. Therefore, in this paper, we propose a dual reinforcement learning framework to directly transfer the style of the text via a one-step mapping model, without any separation of content and style. Specifically, we consider the learning of the source-to-target and target-to-source mappings as a dual task, and two rewards are designed based on such a dual structure to reflect the style accuracy and content preservation, respectively. In this way, the two one-step mapping models can be trained via reinforcement learning, without any use of parallel data. Automatic evaluations show that our model outperforms the state-of-the-art systems by a large margin, especially with more than 8 BLEU points improvement averaged on two benchmark datasets. Human evaluations also validate the effectiveness of our model in terms of style accuracy, content preservation and fluency. Our code and data, including outputs of all baselines and our model are available at https://github.com/luofuli/DualLanST.
Learning Unsupervised Word Mapping by Maximizing Mean Discrepancy
Nov 01, 2018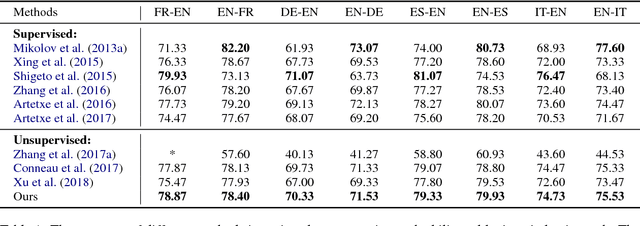

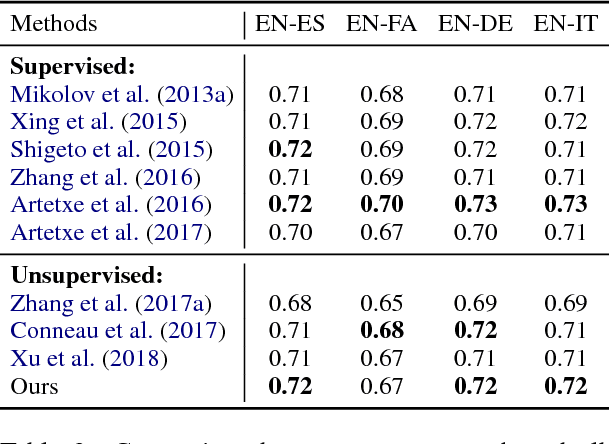
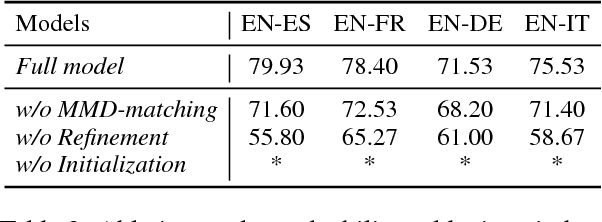
Cross-lingual word embeddings aim to capture common linguistic regularities of different languages, which benefit various downstream tasks ranging from machine translation to transfer learning. Recently, it has been shown that these embeddings can be effectively learned by aligning two disjoint monolingual vector spaces through a linear transformation (word mapping). In this work, we focus on learning such a word mapping without any supervision signal. Most previous work of this task adopts parametric metrics to measure distribution differences, which typically requires a sophisticated alternate optimization process, either in the form of \emph{minmax game} or intermediate \emph{density estimation}. This alternate optimization process is relatively hard and unstable. In order to avoid such sophisticated alternate optimization, we propose to learn unsupervised word mapping by directly maximizing the mean discrepancy between the distribution of transferred embedding and target embedding. Extensive experimental results show that our proposed model outperforms competitive baselines by a large margin.