 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparation-Free Spectral Super-Resolution via Convex Optimization
Nov 28, 2022



Atomic norm methods have recently been proposed for spectral super-resolution with flexibility in dealing with missing data and miscellaneous noises. A notorious drawback of these convex optimization methods however is their lower resolution in the high signal-to-noise (SNR) regime as compared to conventional methods such as ESPRIT. In this paper, we devise a simple weighting scheme in existing atomic norm methods and show that the resolution of the resulting convex optimization method can be made arbitrarily high in the absence of noise, achieving the so-called separation-free super-resolution. This is proved by a novel, kernel-free construction of the dual certificate whose existence guarantees exact super-resolution using the proposed method. Numerical results corroborating our analysis are provided.
Error Analysis of Tensor-Train Cross Approximation
Jul 09, 2022
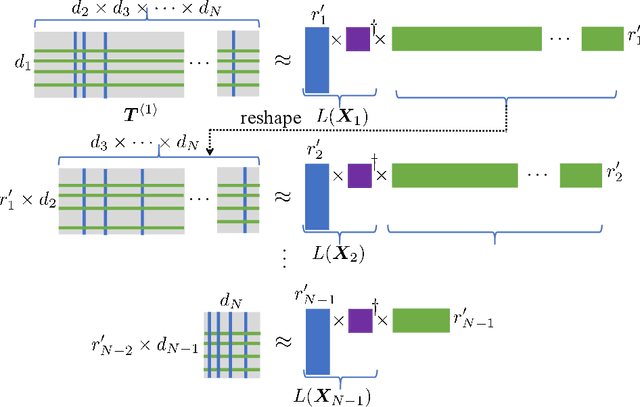
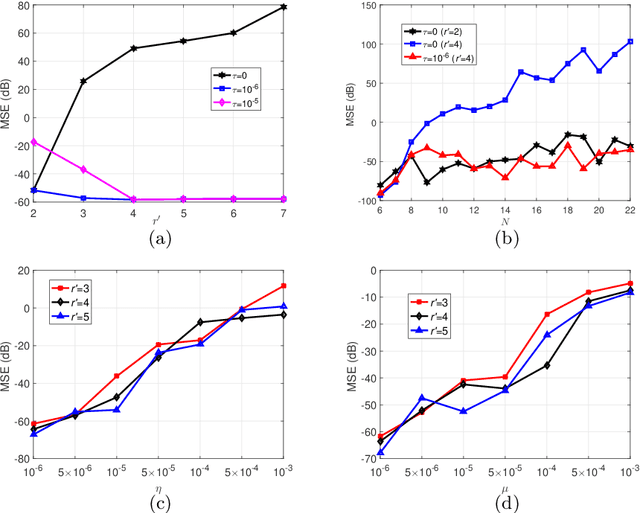

Tensor train decomposition is widely used in machine learning and quantum physics due to its concise representation of high-dimensional tensors, overcoming the curse of dimensionality. Cross approximation-originally developed for representing a matrix from a set of selected rows and columns-is an efficient method for constructing a tensor train decomposition of a tensor from few of its entries. While tensor train cross approximation has achieved remarkable performance in practical applications, its theoretical analysis, in particular regarding the error of the approximation, is so far lacking. To our knowledge, existing results only provide element-wise approximation accuracy guarantees, which lead to a very loose bound when extended to the entire tensor. In this paper, we bridge this gap by providing accuracy guarantees in terms of the entire tensor for both exact and noisy measurements. Our results illustrate how the choice of selected subtensors affects the quality of the cross approximation and that the approximation error caused by model error and/or measurement error may not grow exponentially with the order of the tensor. These results are verified by numerical experiments, and may have important implications for the usefulness of cross approximations for high-order tensors, such as those encountered in the description of quantum many-body states.
The Landscape of Non-convex Empirical Risk with Degenerate Population Risk
Jul 11, 2019
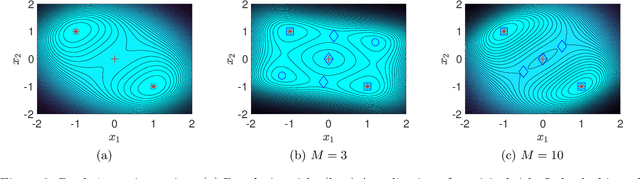

The landscape of empirical risk has been widely studied in a series of machine learning problems, including low-rank matrix factorization, matrix sensing, matrix completion, and phase retrieval. In this work, we focus on the situation where the corresponding population risk is a degenerate non-convex loss function, namely, the Hessian of the population risk can have zero eigenvalues. Instead of analyzing the non-convex empirical risk directly, we first study the landscape of the corresponding population risk, which is usually easier to characterize, and then build a connection between the landscape of the empirical risk and its population risk. In particular, we establish a correspondence between the critical points of the empirical risk and its population risk without the strongly Morse assumption, which is required in existing literature but not satisfied in degenerate scenarios. We also apply the theory to matrix sensing and phase retrieval to demonstrate how to infer the landscape of empirical risk from that of the corresponding population risk.
Provable Bregman-divergence based Methods for Nonconvex and Non-Lipschitz Problems
Apr 22, 2019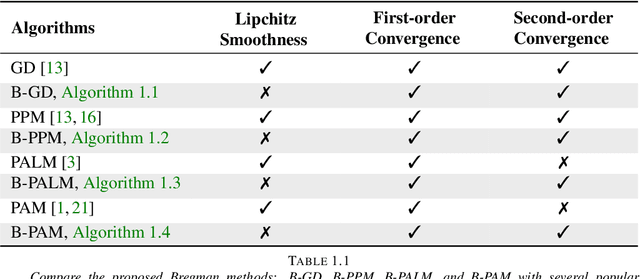
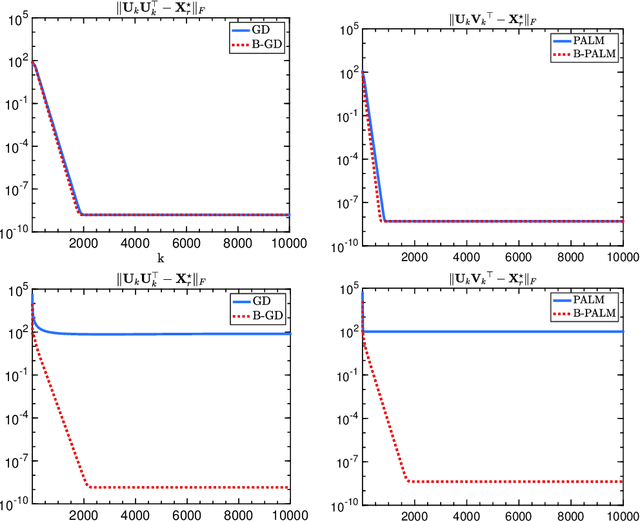
The (global) Lipschitz smoothness condition is crucial in establishing the convergence theory for most optimization methods. Unfortunately, most machine learning and signal processing problems are not Lipschitz smooth. This motivates us to generalize the concept of Lipschitz smoothness condition to the relative smoothness condition, which is satisfied by any finite-order polynomial objective function. Further, this work develops new Bregman-divergence based algorithms that are guaranteed to converge to a second-order stationary point for any relatively smooth problem. In addition, the proposed optimization methods cover both the proximal alternating minimization and the proximal alternating linearized minimization when we specialize the Bregman divergence to the Euclidian distance. Therefore, this work not only develops guaranteed optimization methods for non-Lipschitz smooth problems but also solves an open problem of showing the second-order convergence guarantees for these alternating minimization methods.
Spherical Principal Component Analysis
Mar 16, 2019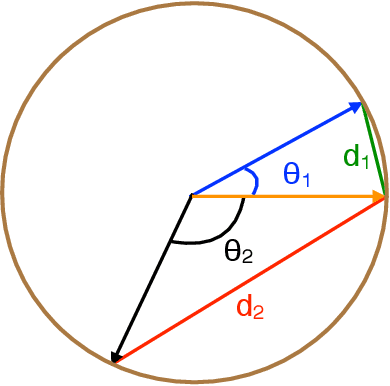

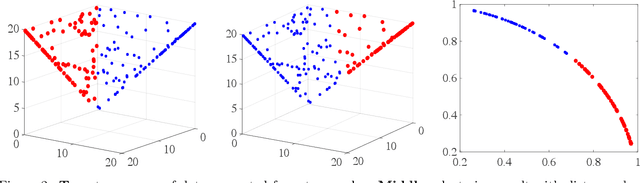

Principal Component Analysis (PCA) is one of the most important methods to handle high dimensional data. However, most of the studies on PCA aim to minimize the loss after projection, which usually measures the Euclidean distance, though in some fields, angle distance is known to be more important and critical for analysis. In this paper, we propose a method by adding constraints on factors to unify the Euclidean distance and angle distance. However, due to the nonconvexity of the objective and constraints, the optimized solution is not easy to obtain. We propose an alternating linearized minimization method to solve it with provable convergence rate and guarantee. Experiments on synthetic data and real-world datasets have validated the effectiveness of our method and demonstrated its advantages over state-of-art clustering methods.
Global Optimality in Distributed Low-rank Matrix Factorization
Nov 07, 2018We study the convergence of a variant of distributed gradient descent (DGD) on a distributed low-rank matrix approximation problem wherein some optimization variables are used for consensus (as in classical DGD) and some optimization variables appear only locally at a single node in the network. We term the resulting algorithm DGD+LOCAL. Using algorithmic connections to gradient descent and geometric connections to the well-behaved landscape of the centralized low-rank matrix approximation problem, we identify sufficient conditions where DGD+LOCAL is guaranteed to converge with exact consensus to a global minimizer of the original centralized problem. For the distributed low-rank matrix approximation problem, these guarantees are stronger---in terms of consensus and optimality---than what appear in the literature for classical DGD and more general problems.
Geometry of Factored Nuclear Norm Regularization
Apr 05, 2017This work investigates the geometry of a nonconvex reformulation of minimizing a general convex loss function $f(X)$ regularized by the matrix nuclear norm $\|X\|_*$. Nuclear-norm regularized matrix inverse problems are at the heart of many applications in machine learning, signal processing, and control. The statistical performance of nuclear norm regularization has been studied extensively in literature using convex analysis techniques. Despite its optimal performance, the resulting optimization has high computational complexity when solved using standard or even tailored fast convex solvers. To develop faster and more scalable algorithms, we follow the proposal of Burer-Monteiro to factor the matrix variable $X$ into the product of two smaller rectangular matrices $X=UV^T$ and also replace the nuclear norm $\|X\|_*$ with $(\|U\|_F^2+\|V\|_F^2)/2$. In spite of the nonconvexity of the factored formulation, we prove that when the convex loss function $f(X)$ is $(2r,4r)$-restricted well-conditioned, each critical point of the factored problem either corresponds to the optimal solution $X^\star$ of the original convex optimization or is a strict saddle point where the Hessian matrix has a strictly negative eigenvalue. Such a geometric structure of the factored formulation allows many local search algorithms to converge to the global optimum with random initializations.
Experimental robustness of Fourier Ptychography phase retrieval algorithms
Dec 18, 2015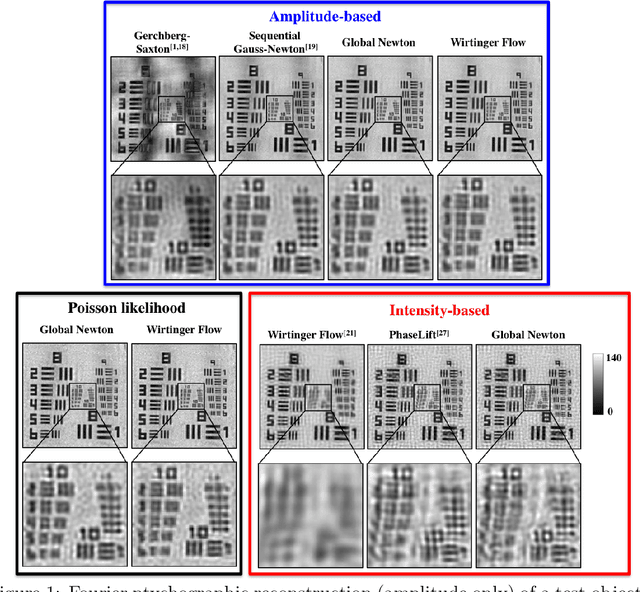
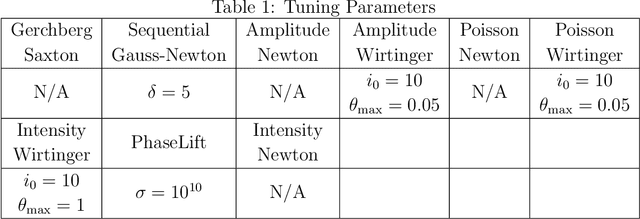
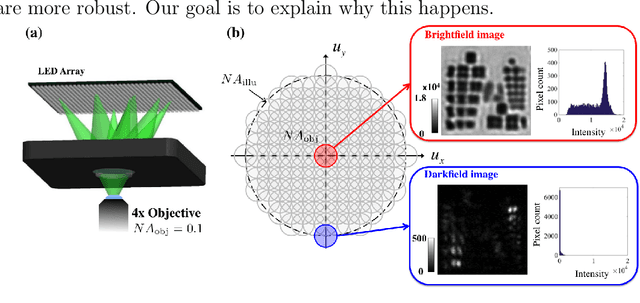
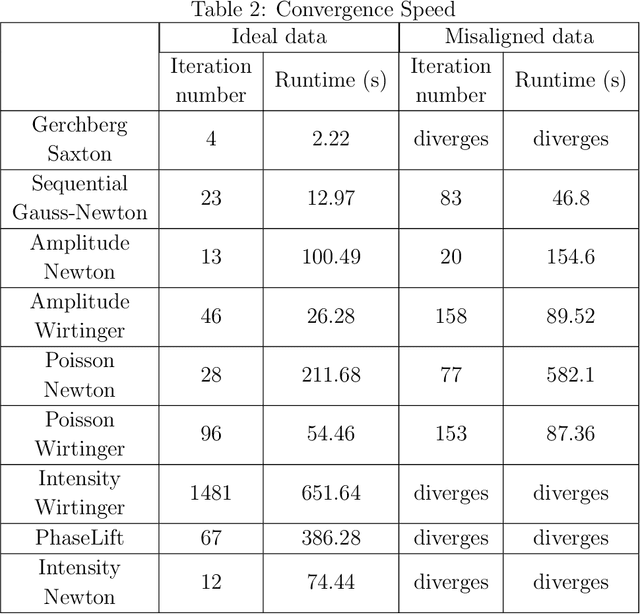
Fourier ptychography is a new computational microscopy technique that provides gigapixel-scale intensity and phase images with both wide field-of-view and high resolution. By capturing a stack of low-resolution images under different illumination angles, a nonlinear inverse algorithm can be used to computationally reconstruct the high-resolution complex field. Here, we compare and classify multiple proposed inverse algorithms in terms of experimental robustness. We find that the main sources of error are noise, aberrations and mis-calibration (i.e. model mis-match). Using simulations and experiments, we demonstrate that the choice of cost function plays a critical role, with amplitude-based cost functions performing better than intensity-based ones. The reason for this is that Fourier ptychography datasets consist of images from both brightfield and darkfield illumination, representing a large range of measured intensities. Both noise (e.g. Poisson noise) and model mis-match errors are shown to scale with intensity. Hence, algorithms that use an appropriate cost function will be more tolerant to both noise and model mis-match. Given these insights, we propose a global Newton's method algorithm which is robust and computationally efficient. Finally, we discuss the impact of procedures for algorithmic correction of aberrations and mis-calibration.
Optimal Low-Rank Tensor Recovery from Separable Measurements: Four Contractions Suffice
May 15, 2015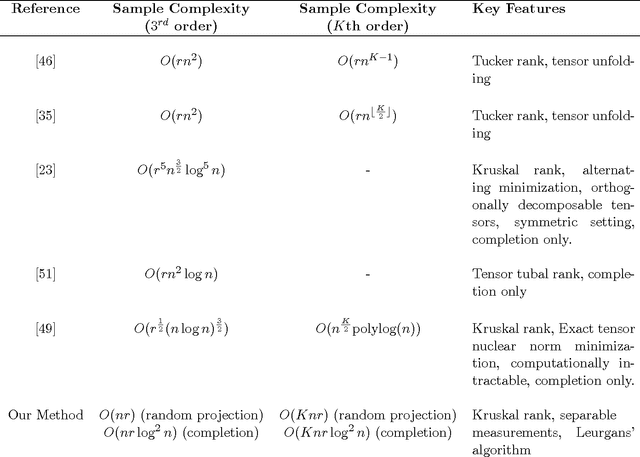
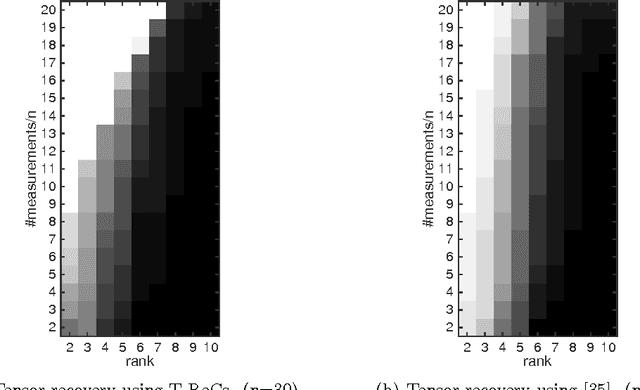
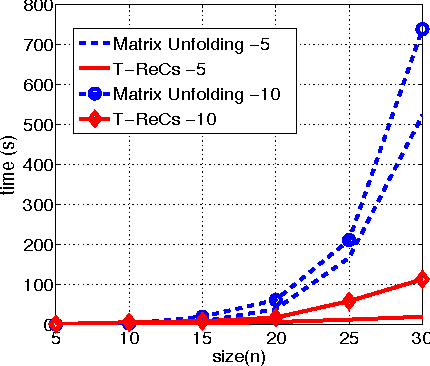
Tensors play a central role in many modern machine learning and signal processing applications. In such applications, the target tensor is usually of low rank, i.e., can be expressed as a sum of a small number of rank one tensors. This motivates us to consider the problem of low rank tensor recovery from a class of linear measurements called separable measurements. As specific examples, we focus on two distinct types of separable measurement mechanisms (a) Random projections, where each measurement corresponds to an inner product of the tensor with a suitable random tensor, and (b) the completion problem where measurements constitute revelation of a random set of entries. We present a computationally efficient algorithm, with rigorous and order-optimal sample complexity results (upto logarithmic factors) for tensor recovery. Our method is based on reduction to matrix completion sub-problems and adaptation of Leurgans' method for tensor decomposition. We extend the methodology and sample complexity results to higher order tensors, and experimentally validate our theoretical results.
The Sample Complexity of Search over Multiple Populations
May 01, 2013


This paper studies the sample complexity of searching over multiple populations. We consider a large number of populations, each corresponding to either distribution P0 or P1. The goal of the search problem studied here is to find one population corresponding to distribution P1 with as few samples as possible. The main contribution is to quantify the number of samples needed to correctly find one such population. We consider two general approaches: non-adaptive sampling methods, which sample each population a predetermined number of times until a population following P1 is found, and adaptive sampling methods, which employ sequential sampling schemes for each population. We first derive a lower bound on the number of samples required by any sampling scheme. We then consider an adaptive procedure consisting of a series of sequential probability ratio tests, and show it comes within a constant factor of the lower bound. We give explicit expressions for this constant when samples of the populations follow Gaussian and Bernoulli distributions. An alternative adaptive scheme is discussed which does not require full knowledge of P1, and comes within a constant factor of the optimal scheme. For comparison, a lower bound on the sampling requirements of any non-adaptive scheme is presented.