 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-World Deployment of a 5G-Connected Edge-Controlled Aerial Robot in Industrial Subterranean Mines
Jun 03, 2026This article presents the first real-world autonomous flight of a 5G-connected aerial robot controlled by an edge-offloaded controller, and aims to bridge the gap between controlled and factual setups. The robot operates within an active industrial subterranean mine, while the high-level controller is deployed in a nearby Kubernetes-based edge cluster. Communication between the robot and the edge is enabled via a 5G New Radio (NR) Standalone (SA) network. The chosen controller is a Model Predictive Controller (MPC), which generates control actions to allow the robot to navigate seamlessly through the mining environment. A human operator selects waypoints for the aerial robot, and the MPC generates smooth, collision-free paths for autonomous executions. The proposed 5G edge-based closed-loop system is evaluated in a real industrial setting and demonstrates the potential of edge-controlled robotic systems toward time-critical, safe and efficient future deployments.
Aerial Inspection Behaviors via RL-based Quadrotor Control for Under-canopy Forest Environments
May 19, 2026This paper addresses the problem of using a deep Reinforcement Learning (RL)-based low-level Quadrotor controller within an autonomous Quadrotor navigation stack for aerial inspection missions in under-canopy forest environments. Specifically, the article presents an end-to-end (mapping states to RPMs) Quadrotor control policy that achieves inspection view-pose tracking (simultaneous position and yaw reference tracking), which is crucial for various target inspection behaviors and point-to-point navigation in forests. To ensure safe and reliable deployment of the end-to-end RL controller in long-range missions, this article utilizes a higher navigation guidance layer comprising of a Traveling Salesman Problem planner (TSP) and a Rapidly-exploring Random Tree Star (RRT*) planner. Over a known map of a forest and a set of user-specified inspection regions, the TSP planner finds the optimal visitation sequence. Between two target regions, collision-free paths that respect the tracking limitations of the lower end-to-end RL policy are generated by an RRT* planner. Through five target inspection scenarios, this article demonstrates that an RL-based motor-level stabilizing controller, supported by a navigation guidance layer, can be used effectively as the low-level inspection execution module for under-canopy forest inspection missions.
A Heuristic Approach for Performance Tuning in RL-based Quadrotor Control via Reward Design and Termination Conditions
May 18, 2026Reinforcement learning (RL)-based quadrotor control policies have achieved impressive performance in tasks such as fast navigation in cluttered environments and drone racing, where the focus is on speed and agility. However, in several applications, such as infrastructure inspection, it is critical to achieve precise, controlled maneuvers with tunable performance. In this article, we present a novel heuristic approach to achieve tunable performance in RL-based Quadrotor control through reward design and termination conditions. We present a novel reward structure containing dual bandwidth exponentials that achieves a baseline critically damped response in setpoint tracking, with low steady-state errors. When trained with a Proximal Policy Optimization (PPO) algorithm, in conjunction with episode truncation conditions, the desired performance is achieved in 6 million time steps in a sample-efficient manner. In order to tune the performance about the baseline behavior, we present intuitive heuristic rules to adjust the reward weights and exponential coefficients to achieve faster (acrobatic-like) and slower (inspection-like) settling time performance, while retaining the baseline critically damped response and approximately 2\% steady-state error. We evaluate the three RL policies (baseline, acrobatic, and inspection) across 100 trials and show accurate and tunable performance in position and yaw tracking from random initial conditions, thereby demonstrating the effectiveness of the proposed heuristic approach.
How IMU Drift Influences Multi-Radar Inertial Odometry for Ground Robots in Subterranean Terrains
Feb 27, 2026Reliable radar inertial odometry (RIO) requires mitigating IMU bias drift, a challenge that intensifies in subterranean environments due to extreme temperatures and gravity-induced accelerations. Cost-effective IMUs such as the Pixhawk, when paired with FMCW TI IWR6843AOP EVM radars, suffer from drift-induced degradation compounded by sparse, noisy, and flickering radar returns, making fusion less stable than LiDAR-based odometry. Yet, LiDAR fails under smoke, dust, and aerosols, whereas FMCW radars remain compact, lightweight, cost-effective, and robust in these situations. To address these challenges, we propose a two-stage MRIO framework that combines an IMU bias estimator for resilient localization and mapping in GPS-denied subterranean environments affected by smoke. Radar-based ego-velocity estimation is formulated through a least-squares approach and incorporated into an EKF for online IMU bias correction; the corrected IMU accelerations are fused with heterogeneous measurements from multiple radars and an IMU to refine odometry. The proposed framework further supports radar-only mapping by exploiting the robot's estimated translational and rotational displacements. In subterranean field trials, MRIO delivers robust localization and mapping, outperforming EKF-RIO. It maintains accuracy across cost-efficient FMCW radar setups and different IMUs, showing resilience with Pixhawk and higher-grade units such as VectorNav. The implementation will be provided as an open-source resource to the community (code available at https://github.com/LTU-RAI/MRIO
Safe Heterogeneous Multi-Agent RL with Communication Regularization for Coordinated Target Acquisition
Jan 13, 2026This paper introduces a decentralized multi-agent reinforcement learning framework enabling structurally heterogeneous teams of agents to jointly discover and acquire randomly located targets in environments characterized by partial observability, communication constraints, and dynamic interactions. Each agent's policy is trained with the Multi-Agent Proximal Policy Optimization algorithm and employs a Graph Attention Network encoder that integrates simulated range-sensing data with communication embeddings exchanged among neighboring agents, enabling context-aware decision-making from both local sensing and relational information. In particular, this work introduces a unified framework that integrates graph-based communication and trajectory-aware safety through safety filters. The architecture is supported by a structured reward formulation designed to encourage effective target discovery and acquisition, collision avoidance, and de-correlation between the agents' communication vectors by promoting informational orthogonality. The effectiveness of the proposed reward function is demonstrated through a comprehensive ablation study. Moreover, simulation results demonstrate safe and stable task execution, confirming the framework's effectiveness.
Planetary Terrain Datasets and Benchmarks for Rover Path Planning
Dec 24, 2025
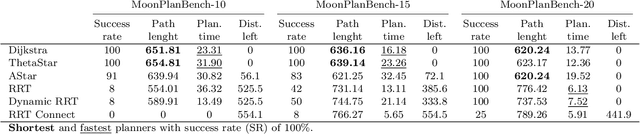
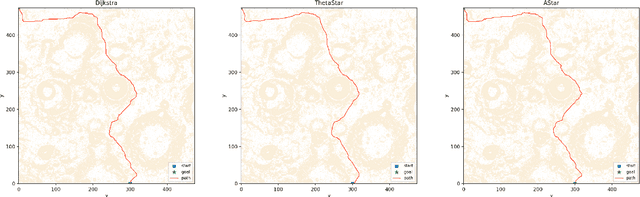
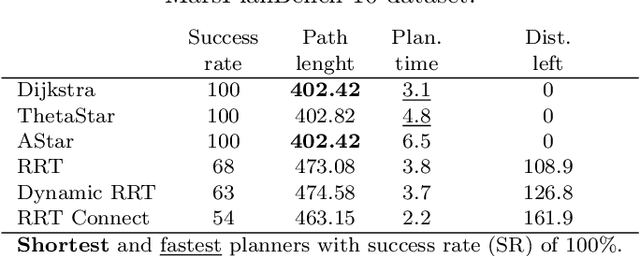
Planetary rover exploration is attracting renewed interest with several upcoming space missions to the Moon and Mars. However, a substantial amount of data from prior missions remain underutilized for path planning and autonomous navigation research. As a result, there is a lack of space mission-based planetary datasets, standardized benchmarks, and evaluation protocols. In this paper, we take a step towards coordinating these three research directions in the context of planetary rover path planning. We propose the first two large planar benchmark datasets, MarsPlanBench and MoonPlanBench, derived from high-resolution digital terrain images of Mars and the Moon. In addition, we set up classical and learned path planning algorithms, in a unified framework, and evaluate them on our proposed datasets and on a popular planning benchmark. Through comprehensive experiments, we report new insights on the performance of representative path planning algorithms on planetary terrains, for the first time to the best of our knowledge. Our results show that classical algorithms can achieve up to 100% global path planning success rates on average across challenging terrains such as Moon's north and south poles. This suggests, for instance, why these algorithms are used in practice by NASA. Conversely, learning-based models, although showing promising results in less complex environments, still struggle to generalize to planetary domains. To serve as a starting point for fundamental path planning research, our code and datasets will be released at: https://github.com/mchancan/PlanetaryPathBench.
Platform-Agnostic Reinforcement Learning Framework for Safe Exploration of Cluttered Environments with Graph Attention
Nov 19, 2025Autonomous exploration of obstacle-rich spaces requires strategies that ensure efficiency while guaranteeing safety against collisions with obstacles. This paper investigates a novel platform-agnostic reinforcement learning framework that integrates a graph neural network-based policy for next-waypoint selection, with a safety filter ensuring safe mobility. Specifically, the neural network is trained using reinforcement learning through the Proximal Policy Optimization (PPO) algorithm to maximize exploration efficiency while minimizing safety filter interventions. Henceforth, when the policy proposes an infeasible action, the safety filter overrides it with the closest feasible alternative, ensuring consistent system behavior. In addition, this paper introduces a reward function shaped by a potential field that accounts for both the agent's proximity to unexplored regions and the expected information gain from reaching them. The proposed framework combines the adaptability of reinforcement learning-based exploration policies with the reliability provided by explicit safety mechanisms. This feature plays a key role in enabling the deployment of learning-based policies on robotic platforms operating in real-world environments. Extensive evaluations in both simulations and experiments performed in a lab environment demonstrate that the approach achieves efficient and safe exploration in cluttered spaces.
Real-time Point Cloud Data Transmission via L4S for 5G-Edge-Assisted Robotics
Nov 11, 2025This article presents a novel framework for real-time Light Detection and Ranging (LiDAR) data transmission that leverages rate-adaptive technologies and point cloud encoding methods to ensure low-latency, and low-loss data streaming. The proposed framework is intended for, but not limited to, robotic applications that require real-time data transmission over the internet for offloaded processing. Specifically, the Low Latency, Low Loss, Scalable Throughput L4S-enabled SCReAM v2 transmission framework is extended to incorporate the Draco geometry compression algorithm, enabling dynamic compression of high-bitrate 3D LiDAR data according to the sensed channel capacity and network load. The low-latency 3D LiDAR streaming system is designed to maintain minimal end-to-end delay while constraining encoding errors to meet the accuracy requirements of robotic applications. We demonstrate the effectiveness of the proposed method through real-world experiments conducted over a public 5G network across multi-kilometer urban environments. The low-latency and low-loss requirements are preserved, while real-time offloading and evaluation of 3D SLAM algorithms are used to validate the framework's performance in practical use cases.
Cloud-Assisted Remote Control for Aerial Robots: From Theory to Proof-of-Concept Implementation
Sep 04, 2025Cloud robotics has emerged as a promising technology for robotics applications due to its advantages of offloading computationally intensive tasks, facilitating data sharing, and enhancing robot coordination. However, integrating cloud computing with robotics remains a complex challenge due to network latency, security concerns, and the need for efficient resource management. In this work, we present a scalable and intuitive framework for testing cloud and edge robotic systems. The framework consists of two main components enabled by containerized technology: (a) a containerized cloud cluster and (b) the containerized robot simulation environment. The system incorporates two endpoints of a User Datagram Protocol (UDP) tunnel, enabling bidirectional communication between the cloud cluster container and the robot simulation environment, while simulating realistic network conditions. To achieve this, we consider the use case of cloud-assisted remote control for aerial robots, while utilizing Linux-based traffic control to introduce artificial delay and jitter, replicating variable network conditions encountered in practical cloud-robot deployments.
* 6 pages, 7 figures, CCGridW 2025
SPADE: Towards Scalable Path Planning Architecture on Actionable Multi-Domain 3D Scene Graphs
May 25, 2025In this work, we introduce SPADE, a path planning framework designed for autonomous navigation in dynamic environments using 3D scene graphs. SPADE combines hierarchical path planning with local geometric awareness to enable collision-free movement in dynamic scenes. The framework bifurcates the planning problem into two: (a) solving the sparse abstract global layer plan and (b) iterative path refinement across denser lower local layers in step with local geometric scene navigation. To ensure efficient extraction of a feasible route in a dense multi-task domain scene graphs, the framework enforces informed sampling of traversable edges prior to path-planning. This removes extraneous information not relevant to path-planning and reduces the overall planning complexity over a graph. Existing approaches address the problem of path planning over scene graphs by decoupling hierarchical and geometric path evaluation processes. Specifically, this results in an inefficient replanning over the entire scene graph when encountering path obstructions blocking the original route. In contrast, SPADE prioritizes local layer planning coupled with local geometric scene navigation, enabling navigation through dynamic scenes while maintaining efficiency in computing a traversable route. We validate SPADE through extensive simulation experiments and real-world deployment on a quadrupedal robot, demonstrating its efficacy in handling complex and dynamic scenarios.