 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Graph-Based Terrain-Aware Autonomous Navigation Approach for Complementary Multimodal Ground-Aerial Exploration
May 20, 2025Autonomous navigation in unknown environments is a fundamental challenge in robotics, particularly in coordinating ground and aerial robots to maximize exploration efficiency. This paper presents a novel approach that utilizes a hierarchical graph to represent the environment, encoding both geometric and semantic traversability. The framework enables the robots to compute a shared confidence metric, which helps the ground robot assess terrain and determine when deploying the aerial robot will extend exploration. The robot's confidence in traversing a path is based on factors such as predicted volumetric gain, path traversability, and collision risk. A hierarchy of graphs is used to maintain an efficient representation of traversability and frontier information through multi-resolution maps. Evaluated in a real subterranean exploration scenario, the approach allows the ground robot to autonomously identify zones that are no longer traversable but suitable for aerial deployment. By leveraging this hierarchical structure, the ground robot can selectively share graph information on confidence-assessed frontier targets from parts of the scene, enabling the aerial robot to navigate beyond obstacles and continue exploration.
Estimating Commonsense Scene Composition on Belief Scene Graphs
May 05, 2025This work establishes the concept of commonsense scene composition, with a focus on extending Belief Scene Graphs by estimating the spatial distribution of unseen objects. Specifically, the commonsense scene composition capability refers to the understanding of the spatial relationships among related objects in the scene, which in this article is modeled as a joint probability distribution for all possible locations of the semantic object class. The proposed framework includes two variants of a Correlation Information (CECI) model for learning probability distributions: (i) a baseline approach based on a Graph Convolutional Network, and (ii) a neuro-symbolic extension that integrates a spatial ontology based on Large Language Models (LLMs). Furthermore, this article provides a detailed description of the dataset generation process for such tasks. Finally, the framework has been validated through multiple runs on simulated data, as well as in a real-world indoor environment, demonstrating its ability to spatially interpret scenes across different room types.
xFLIE: Leveraging Actionable Hierarchical Scene Representations for Autonomous Semantic-Aware Inspection Missions
Dec 27, 2024



This article presents xFLIE, a fully integrated 3D hierarchical scene graph based autonomous inspection architecture. Specifically, we present a tightly-coupled solution of incremental 3D Layered Semantic Graphs (LSG) construction and real-time exploitation by a multi-modal autonomy, First-Look based Inspection and Exploration (FLIE) planner, to address the task of inspection of apriori unknown semantic targets of interest in unknown environments. This work aims to address the challenge of maintaining, in addition to or as an alternative to volumetric models, an intuitive scene representation during large-scale inspection missions. Through its contributions, the proposed architecture aims to provide a high-level multi-tiered abstract environment representation whilst simultaneously maintaining a tractable foundation for rapid and informed decision-making capable of enhancing inspection planning through scene understanding, what should it inspect ?, and reasoning, why should it inspect ?. The proposed LSG framework is designed to leverage the concept of nesting lower local graphs, at multiple layers of abstraction, with the abstract concepts grounded on the functionality of the integrated FLIE planner. Through intuitive scene representation, the proposed architecture offers an easily digestible environment model for human operators which helps to improve situational awareness and their understanding of the operating environment. We highlight the use-case benefits of hierarchical and semantic path-planning capability over LSG to address queries, by the integrated planner as well as the human operator. The validity of the proposed architecture is evaluated in large-scale simulated outdoor urban scenarios as well as being deployed onboard a Boston Dynamics Spot quadruped robot for extensive outdoor field experiments.
BOX3D: Lightweight Camera-LiDAR Fusion for 3D Object Detection and Localization
Aug 27, 2024



Object detection and global localization play a crucial role in robotics, spanning across a great spectrum of applications from autonomous cars to multi-layered 3D Scene Graphs for semantic scene understanding. This article proposes BOX3D, a novel multi-modal and lightweight scheme for localizing objects of interest by fusing the information from RGB camera and 3D LiDAR. BOX3D is structured around a three-layered architecture, building up from the local perception of the incoming sequential sensor data to the global perception refinement that covers for outliers and the general consistency of each object's observation. More specifically, the first layer handles the low-level fusion of camera and LiDAR data for initial 3D bounding box extraction. The second layer converts each LiDAR's scan 3D bounding boxes to the world coordinate frame and applies a spatial pairing and merging mechanism to maintain the uniqueness of objects observed from different viewpoints. Finally, BOX3D integrates the third layer that supervises the consistency of the results on the global map iteratively, using a point-to-voxel comparison for identifying all points in the global map that belong to the object. Benchmarking results of the proposed novel architecture are showcased in multiple experimental trials on public state-of-the-art large-scale dataset of urban environments.
Belief Scene Graphs: Expanding Partial Scenes with Objects through Computation of Expectation
Feb 06, 2024
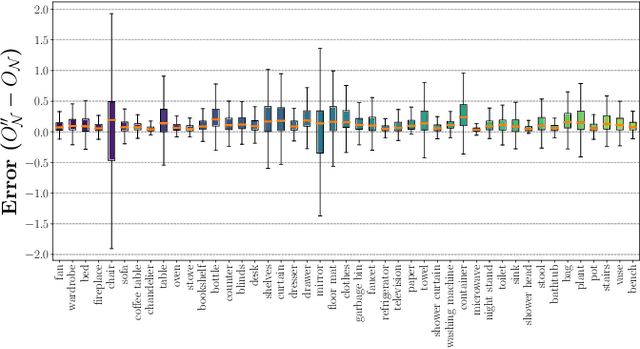
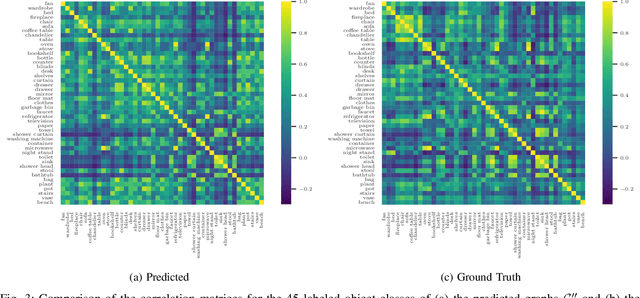
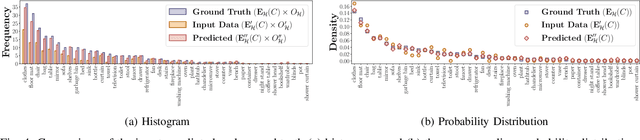
In this article, we propose the novel concept of Belief Scene Graphs, which are utility-driven extensions of partial 3D scene graphs, that enable efficient high-level task planning with partial information. We propose a graph-based learning methodology for the computation of belief (also referred to as expectation) on any given 3D scene graph, which is then used to strategically add new nodes (referred to as blind nodes) that are relevant for a robotic mission. We propose the method of Computation of Expectation based on Correlation Information (CECI), to reasonably approximate real Belief/Expectation, by learning histograms from available training data. A novel Graph Convolutional Neural Network (GCN) model is developed, to learn CECI from a repository of 3D scene graphs. As no database of 3D scene graphs exists for the training of the novel CECI model, we present a novel methodology for generating a 3D scene graph dataset based on semantically annotated real-life 3D spaces. The generated dataset is then utilized to train the proposed CECI model and for extensive validation of the proposed method. We establish the novel concept of \textit{Belief Scene Graphs} (BSG), as a core component to integrate expectations into abstract representations. This new concept is an evolution of the classical 3D scene graph concept and aims to enable high-level reasoning for the task planning and optimization of a variety of robotics missions. The efficacy of the overall framework has been evaluated in an object search scenario, and has also been tested on a real-life experiment to emulate human common sense of unseen-objects.
RecNet: An Invertible Point Cloud Encoding through Range Image Embeddings for Multi-Robot Map Sharing and Reconstruction
Feb 03, 2024In the field of resource-constrained robots and the need for effective place recognition in multi-robotic systems, this article introduces RecNet, a novel approach that concurrently addresses both challenges. The core of RecNet's methodology involves a transformative process: it projects 3D point clouds into depth images, compresses them using an encoder-decoder framework, and subsequently reconstructs the range image, seamlessly restoring the original point cloud. Additionally, RecNet utilizes the latent vector extracted from this process for efficient place recognition tasks. This unique approach not only achieves comparable place recognition results but also maintains a compact representation, suitable for seamless sharing among robots to reconstruct their collective maps. The evaluation of RecNet encompasses an array of metrics, including place recognition performance, structural similarity of the reconstructed point clouds, and the bandwidth transmission advantages, derived from sharing only the latent vectors. This reconstructed map paves a groundbreaking way for exploring its usability in navigation, localization, map-merging, and other relevant missions. Our proposed approach is rigorously assessed using both a publicly available dataset and field experiments, confirming its efficacy and potential for real-world applications.
Event Camera and LiDAR based Human Tracking for Adverse Lighting Conditions in Subterranean Environments
Apr 18, 2023



In this article, we propose a novel LiDAR and event camera fusion modality for subterranean (SubT) environments for fast and precise object and human detection in a wide variety of adverse lighting conditions, such as low or no light, high-contrast zones and in the presence of blinding light sources. In the proposed approach, information from the event camera and LiDAR are fused to localize a human or an object-of-interest in a robot's local frame. The local detection is then transformed into the inertial frame and used to set references for a Nonlinear Model Predictive Controller (NMPC) for reactive tracking of humans or objects in SubT environments. The proposed novel fusion uses intensity filtering and K-means clustering on the LiDAR point cloud and frequency filtering and connectivity clustering on the events induced in an event camera by the returning LiDAR beams. The centroids of the clusters in the event camera and LiDAR streams are then paired to localize reflective markers present on safety vests and signs in SubT environments. The efficacy of the proposed scheme has been experimentally validated in a real SubT environment (a mine) with a Pioneer 3AT mobile robot. The experimental results show real-time performance for human detection and the NMPC-based controller allows for reactive tracking of a human or object of interest, even in complete darkness.