 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Heterogeneous Multi-Agent RL with Communication Regularization for Coordinated Target Acquisition
Jan 13, 2026This paper introduces a decentralized multi-agent reinforcement learning framework enabling structurally heterogeneous teams of agents to jointly discover and acquire randomly located targets in environments characterized by partial observability, communication constraints, and dynamic interactions. Each agent's policy is trained with the Multi-Agent Proximal Policy Optimization algorithm and employs a Graph Attention Network encoder that integrates simulated range-sensing data with communication embeddings exchanged among neighboring agents, enabling context-aware decision-making from both local sensing and relational information. In particular, this work introduces a unified framework that integrates graph-based communication and trajectory-aware safety through safety filters. The architecture is supported by a structured reward formulation designed to encourage effective target discovery and acquisition, collision avoidance, and de-correlation between the agents' communication vectors by promoting informational orthogonality. The effectiveness of the proposed reward function is demonstrated through a comprehensive ablation study. Moreover, simulation results demonstrate safe and stable task execution, confirming the framework's effectiveness.
Platform-Agnostic Reinforcement Learning Framework for Safe Exploration of Cluttered Environments with Graph Attention
Nov 19, 2025Autonomous exploration of obstacle-rich spaces requires strategies that ensure efficiency while guaranteeing safety against collisions with obstacles. This paper investigates a novel platform-agnostic reinforcement learning framework that integrates a graph neural network-based policy for next-waypoint selection, with a safety filter ensuring safe mobility. Specifically, the neural network is trained using reinforcement learning through the Proximal Policy Optimization (PPO) algorithm to maximize exploration efficiency while minimizing safety filter interventions. Henceforth, when the policy proposes an infeasible action, the safety filter overrides it with the closest feasible alternative, ensuring consistent system behavior. In addition, this paper introduces a reward function shaped by a potential field that accounts for both the agent's proximity to unexplored regions and the expected information gain from reaching them. The proposed framework combines the adaptability of reinforcement learning-based exploration policies with the reliability provided by explicit safety mechanisms. This feature plays a key role in enabling the deployment of learning-based policies on robotic platforms operating in real-world environments. Extensive evaluations in both simulations and experiments performed in a lab environment demonstrate that the approach achieves efficient and safe exploration in cluttered spaces.
Design and Evaluation of a UGV-Based Robotic Platform for Precision Soil Moisture Remote Sensing
Apr 25, 2025This extended abstract presents the design and evaluation of AgriOne, an automated unmanned ground vehicle (UGV) platform for high precision sensing of soil moisture in large agricultural fields. The developed robotic system is equipped with a volumetric water content (VWC) sensor mounted on a robotic manipulator and utilizes a surface-aware data collection framework to ensure accurate measurements in heterogeneous terrains. The framework identifies and removes invalid data points where the sensor fails to penetrate the soil, ensuring data reliability. Multiple field experiments were conducted to validate the platform's performance, while the obtained results demonstrate the efficacy of the AgriOne robot in real-time data acquisition, reducing the need for permanent sensors and labor-intensive methods.
A Graph-Based Reinforcement Learning Approach with Frontier Potential Based Reward for Safe Cluttered Environment Exploration
Apr 16, 2025



Autonomous exploration of cluttered environments requires efficient exploration strategies that guarantee safety against potential collisions with unknown random obstacles. This paper presents a novel approach combining a graph neural network-based exploration greedy policy with a safety shield to ensure safe navigation goal selection. The network is trained using reinforcement learning and the proximal policy optimization algorithm to maximize exploration efficiency while reducing the safety shield interventions. However, if the policy selects an infeasible action, the safety shield intervenes to choose the best feasible alternative, ensuring system consistency. Moreover, this paper proposes a reward function that includes a potential field based on the agent's proximity to unexplored regions and the expected information gain from reaching them. Overall, the approach investigated in this paper merges the benefits of the adaptability of reinforcement learning-driven exploration policies and the guarantee ensured by explicit safety mechanisms. Extensive evaluations in simulated environments demonstrate that the approach enables efficient and safe exploration in cluttered environments.
Soft Arm-Motor Thrust Characterization for a Pneumatically Actuated Soft Morphing Quadrotor
Feb 18, 2025In this work, an experimental characterization of the configuration space of a soft, pneumatically actuated morphing quadrotor is presented, with a focus on precise thrust characterization of its flexible arms, considering the effect of downwash. Unlike traditional quadrotors, the soft drone has pneumatically actuated arms, introducing complex, nonlinear interactions between motor thrust and arm deformation, which make precise control challenging. The silicone arms are actuated using differential pressure to achieve flexibility and thus have a variable workspace compared to their fixed counter-parts. The deflection of the soft arms during compression and expansion is controlled throughout the flight. However, in real time, the downwash from the motor attached at the tip of the soft arm generates a significant and random disturbance on the arm. This disturbance affects both the desired deflection of the arm and the overall stability of the system. To address this factor, an experimental characterization of the effect of downwash on the deflection angle of the arm is conducted.
Curriculum-based Sample Efficient Reinforcement Learning for Robust Stabilization of a Quadrotor
Jan 30, 2025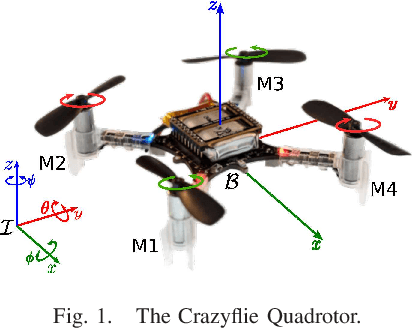
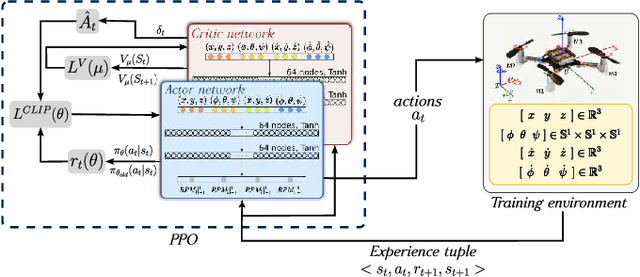
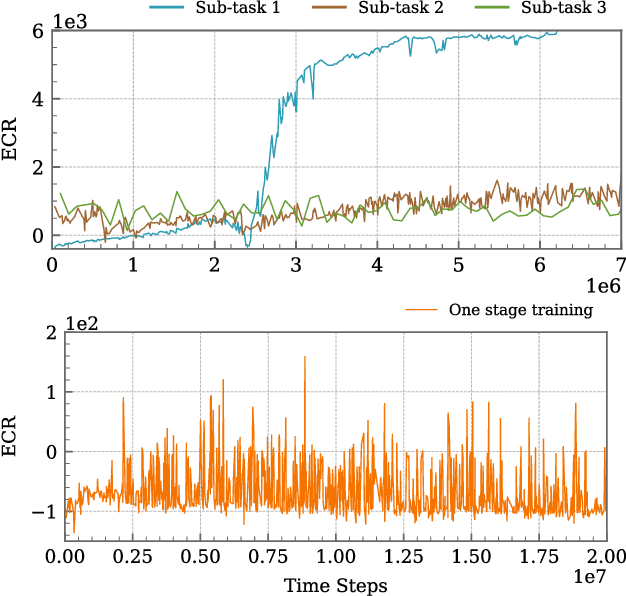
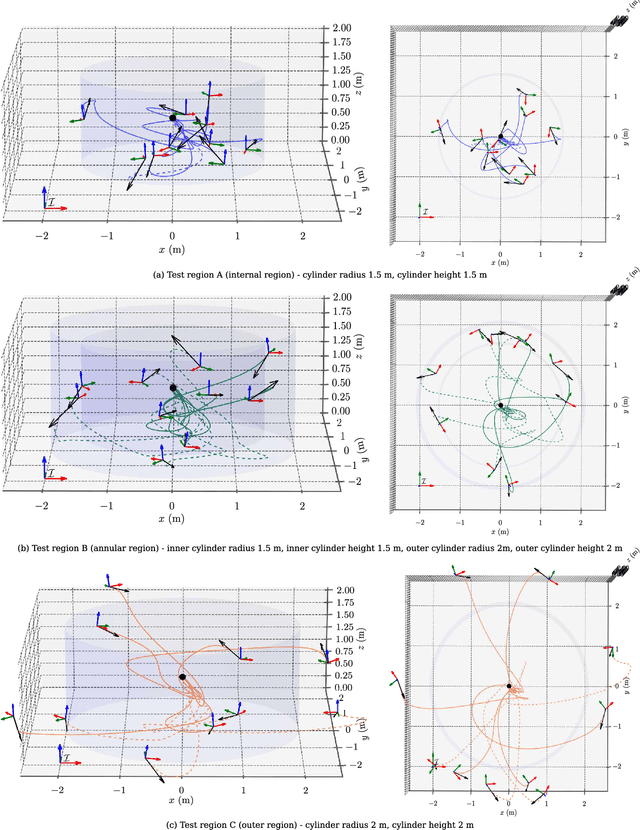
This article introduces a curriculum learning approach to develop a reinforcement learning-based robust stabilizing controller for a Quadrotor that meets predefined performance criteria. The learning objective is to achieve desired positions from random initial conditions while adhering to both transient and steady-state performance specifications. This objective is challenging for conventional one-stage end-to-end reinforcement learning, due to the strong coupling between position and orientation dynamics, the complexity in designing and tuning the reward function, and poor sample efficiency, which necessitates substantial computational resources and leads to extended convergence times. To address these challenges, this work decomposes the learning objective into a three-stage curriculum that incrementally increases task complexity. The curriculum begins with learning to achieve stable hovering from a fixed initial condition, followed by progressively introducing randomization in initial positions, orientations and velocities. A novel additive reward function is proposed, to incorporate transient and steady-state performance specifications. The results demonstrate that the Proximal Policy Optimization (PPO)-based curriculum learning approach, coupled with the proposed reward structure, achieves superior performance compared to a single-stage PPO-trained policy with the same reward function, while significantly reducing computational resource requirements and convergence time. The curriculum-trained policy's performance and robustness are thoroughly validated under random initial conditions and in the presence of disturbances.
Investigating the Impact of Communication-Induced Action Space on Exploration of Unknown Environments with Decentralized Multi-Agent Reinforcement Learning
Dec 28, 2024



This paper introduces a novel enhancement to the Decentralized Multi-Agent Reinforcement Learning (D-MARL) exploration by proposing communication-induced action space to improve the mapping efficiency of unknown environments using homogeneous agents. Efficient exploration of large environments relies heavily on inter-agent communication as real-world scenarios are often constrained by data transmission limits, such as signal latency and bandwidth. Our proposed method optimizes each agent's policy using the heterogeneous-agent proximal policy optimization algorithm, allowing agents to autonomously decide whether to communicate or to explore, that is whether to share the locally collected maps or continue the exploration. We propose and compare multiple novel reward functions that integrate inter-agent communication and exploration, enhance mapping efficiency and robustness, and minimize exploration overlap. This article presents a framework developed in ROS2 to evaluate and validate the investigated architecture. Specifically, four TurtleBot3 Burgers have been deployed in a Gazebo-designed environment filled with obstacles to evaluate the efficacy of the trained policies in mapping the exploration arena.
Reinforcement Learning Driven Multi-Robot Exploration via Explicit Communication and Density-Based Frontier Search
Dec 28, 2024



Collaborative multi-agent exploration of unknown environments is crucial for search and rescue operations. Effective real-world deployment must address challenges such as limited inter-agent communication and static and dynamic obstacles. This paper introduces a novel decentralized collaborative framework based on Reinforcement Learning to enhance multi-agent exploration in unknown environments. Our approach enables agents to decide their next action using an agent-centered field-of-view occupancy grid, and features extracted from $\text{A}^*$ algorithm-based trajectories to frontiers in the reconstructed global map. Furthermore, we propose a constrained communication scheme that enables agents to share their environmental knowledge efficiently, minimizing exploration redundancy. The decentralized nature of our framework ensures that each agent operates autonomously, while contributing to a collective exploration mission. Extensive simulations in Gymnasium and real-world experiments demonstrate the robustness and effectiveness of our system, while all the results highlight the benefits of combining autonomous exploration with inter-agent map sharing, advancing the development of scalable and resilient robotic exploration systems.
A Surface Adaptive First-Look Inspection Planner for Autonomous Remote Sensing of Open-Pit Mines
Oct 14, 2024



In this work, we present an autonomous inspection framework for remote sensing tasks in active open-pit mines. Specifically, the contributions are focused towards developing a methodology where an initial approximate operator-defined inspection plan is exploited by an online view-planner to predict an inspection path that can adapt to changes in the current mine-face morphology caused by route mining activities. The proposed inspection framework leverages instantaneous 3D LiDAR and localization measurements coupled with modelled sensor footprint for view-planning satisfying desired viewing and photogrammetric conditions. The efficacy of the proposed framework has been demonstrated through simulation in Feiring-Bruk open-pit mine environment and hardware-based outdoor experimental trials. The video showcasing the performance of the proposed work can be found here: https://youtu.be/uWWbDfoBvFc
Why Sample Space Matters: Keyframe Sampling Optimization for LiDAR-based Place Recognition
Oct 03, 2024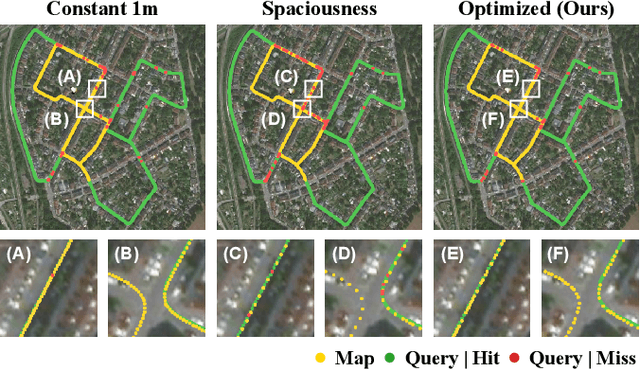
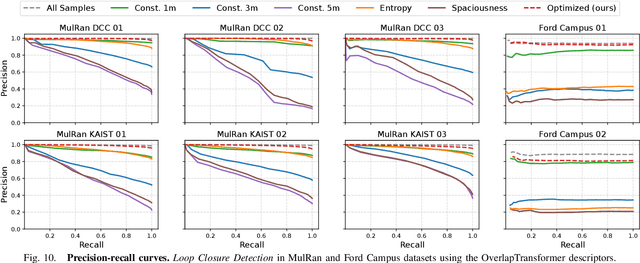
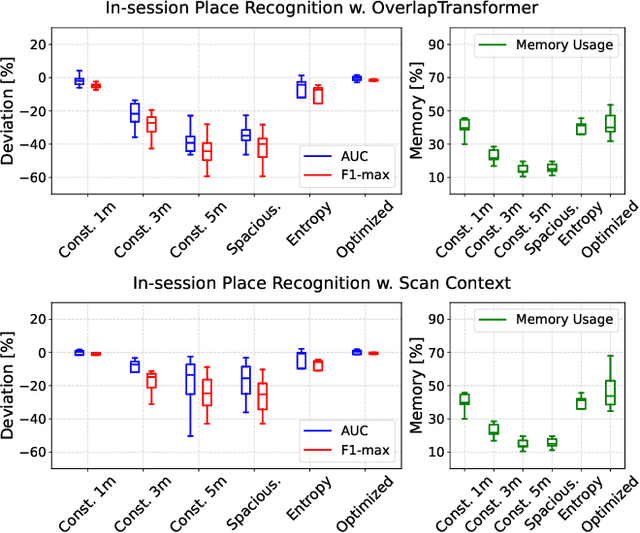
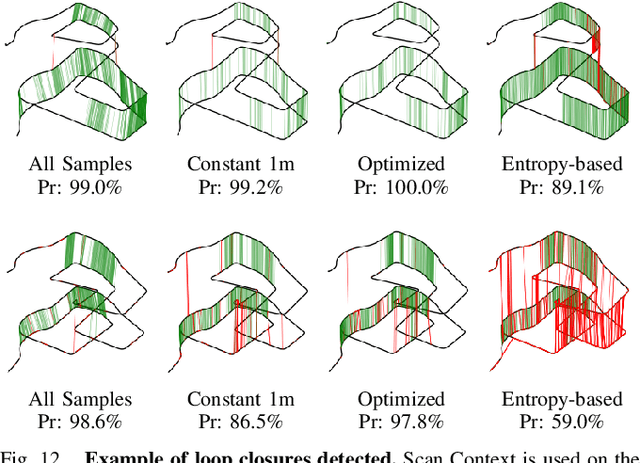
Recent advances in robotics are pushing real-world autonomy, enabling robots to perform long-term and large-scale missions. A crucial component for successful missions is the incorporation of loop closures through place recognition, which effectively mitigates accumulated pose estimation drift. Despite computational advancements, optimizing performance for real-time deployment remains challenging, especially in resource-constrained mobile robots and multi-robot systems since, conventional keyframe sampling practices in place recognition often result in retaining redundant information or overlooking relevant data, as they rely on fixed sampling intervals or work directly in the 3D space instead of the feature space. To address these concerns, we introduce the concept of sample space in place recognition and demonstrate how different sampling techniques affect the query process and overall performance. We then present a novel keyframe sampling approach for LiDAR-based place recognition, which focuses on redundancy minimization and information preservation in the hyper-dimensional descriptor space. This approach is applicable to both learning-based and handcrafted descriptors, and through the experimental validation across multiple datasets and descriptor frameworks, we demonstrate the effectiveness of our proposed method, showing it can jointly minimize redundancy and preserve essential information in real-time. The proposed approach maintains robust performance across various datasets without requiring parameter tuning, contributing to more efficient and reliable place recognition for a wide range of robotic applications.