 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe IKEA ASM Dataset: Understanding People Assembling Furniture through Actions, Objects and Pose
Jul 01, 2020
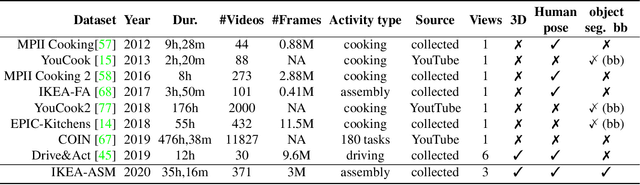
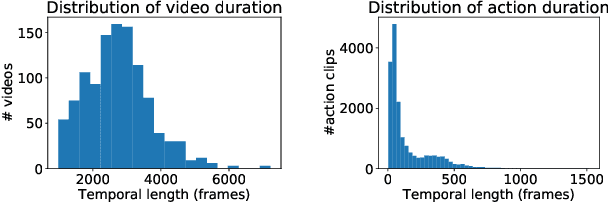

The availability of a large labeled dataset is a key requirement for applying deep learning methods to solve various computer vision tasks. In the context of understanding human activities, existing public datasets, while large in size, are often limited to a single RGB camera and provide only per-frame or per-clip action annotations. To enable richer analysis and understanding of human activities, we introduce IKEA ASM---a three million frame, multi-view, furniture assembly video dataset that includes depth, atomic actions, object segmentation, and human pose. Additionally, we benchmark prominent methods for video action recognition, object segmentation and human pose estimation tasks on this challenging dataset. The dataset enables the development of holistic methods, which integrate multi-modal and multi-view data to better perform on these tasks.
UC-Net: Uncertainty Inspired RGB-D Saliency Detection via Conditional Variational Autoencoders
Apr 13, 2020
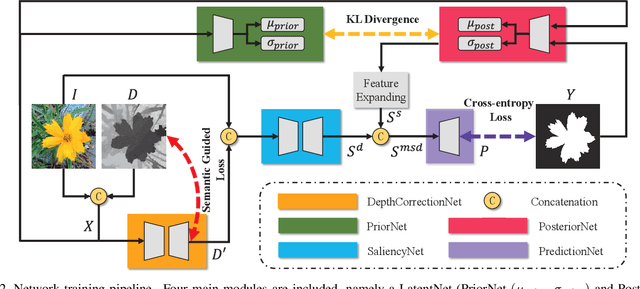
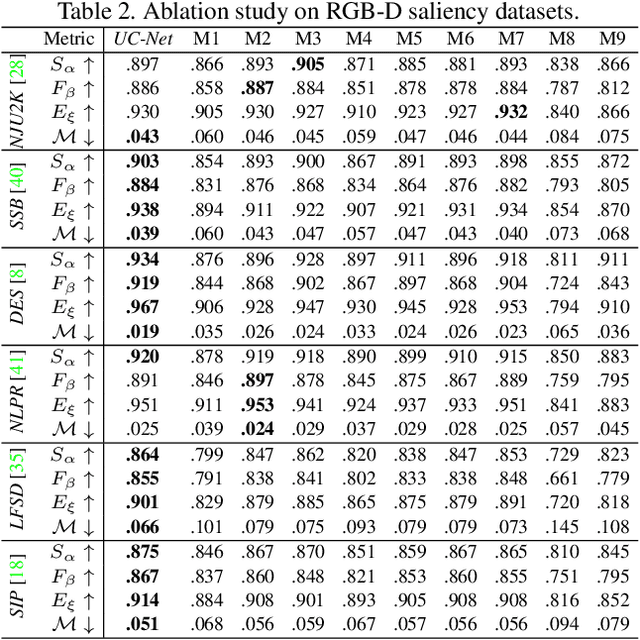
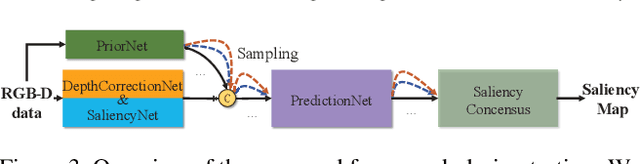
In this paper, we propose the first framework (UCNet) to employ uncertainty for RGB-D saliency detection by learning from the data labeling process. Existing RGB-D saliency detection methods treat the saliency detection task as a point estimation problem, and produce a single saliency map following a deterministic learning pipeline. Inspired by the saliency data labeling process, we propose probabilistic RGB-D saliency detection network via conditional variational autoencoders to model human annotation uncertainty and generate multiple saliency maps for each input image by sampling in the latent space. With the proposed saliency consensus process, we are able to generate an accurate saliency map based on these multiple predictions. Quantitative and qualitative evaluations on six challenging benchmark datasets against 18 competing algorithms demonstrate the effectiveness of our approach in learning the distribution of saliency maps, leading to a new state-of-the-art in RGB-D saliency detection.
Sampling Good Latent Variables via CPP-VAEs: VAEs with Condition Posterior as Prior
Dec 18, 2019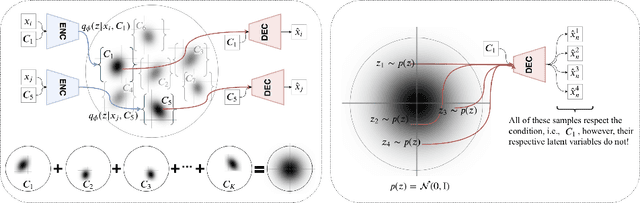
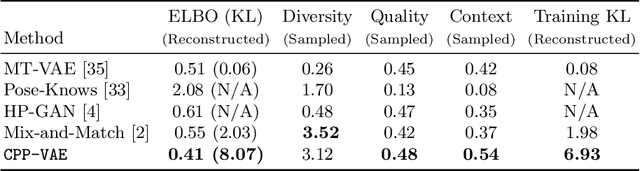
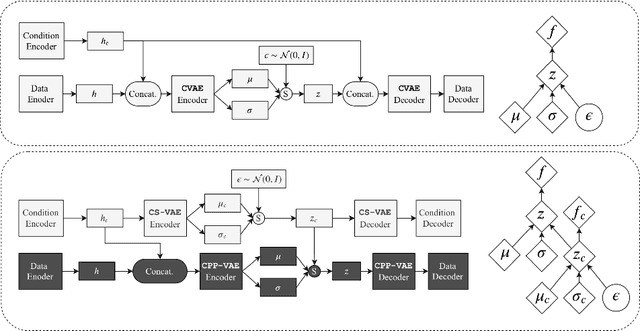

In practice, conditional variational autoencoders (CVAEs) perform conditioning by combining two sources of information which are computed completely independently; CVAEs first compute the condition, then sample the latent variable, and finally concatenate these two sources of information. However, these two processes should be tied together such that the model samples a latent variable given the conditioning signal. In this paper, we directly address this by conditioning the sampling of the latent variable on the CVAE condition, thus encouraging it to carry relevant information. We study this specifically for tasks that leverage with strong conditioning signals and where the generative models have highly expressive decoders able to generate a sample based on the information contained in the condition solely. In particular, we experiments with the two challenging tasks of diverse human motion generation and diverse image captioning, for which our results suggest that unifying latent variable sampling and conditioning not only yields samples of higher quality, but also helps the model to avoid the posterior collapse, a known problem of VAEs with expressive decoders.
Proposal-free Temporal Moment Localization of a Natural-Language Query in Video using Guided Attention
Aug 20, 2019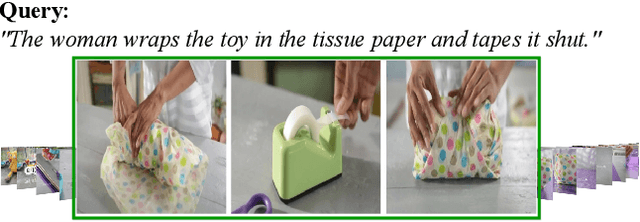
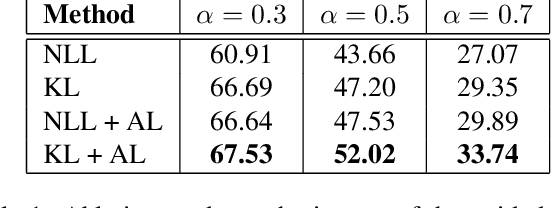
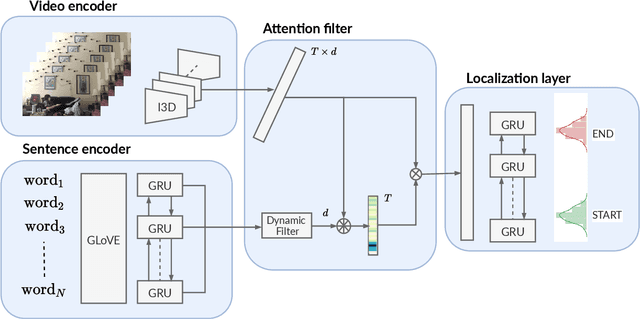
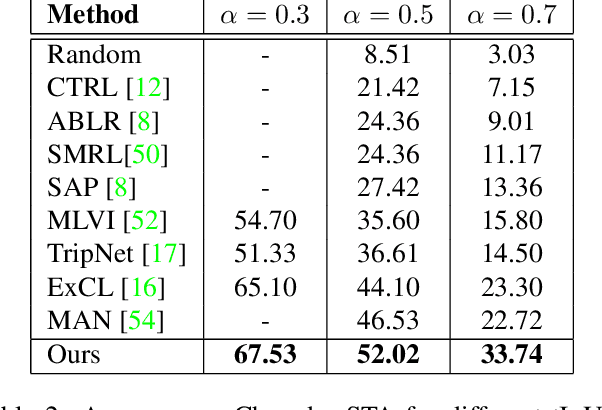
This paper studies the problem of temporal moment localization in a long untrimmed video using natural language as the query. Given an untrimmed video and a sentence as the query, the goal is to determine the starting, and the ending, of the relevant visual moment in the video, that corresponds to the query sentence. While previous works have tackled this task by a propose-and-rank approach, we introduce a more efficient, end-to-end trainable, and {\em proposal-free approach} that relies on three key components: a dynamic filter to transfer language information to the visual domain, a new loss function to guide our model to attend the most relevant parts of the video, and soft labels to model annotation uncertainty. We evaluate our method on two benchmark datasets, Charades-STA and ActivityNet-Captions. Experimental results show that our approach outperforms state-of-the-art methods on both datasets.
Learning Variations in Human Motion via Mix-and-Match Perturbation
Aug 02, 2019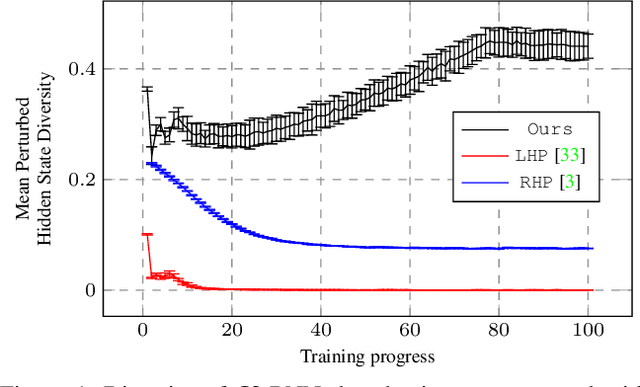
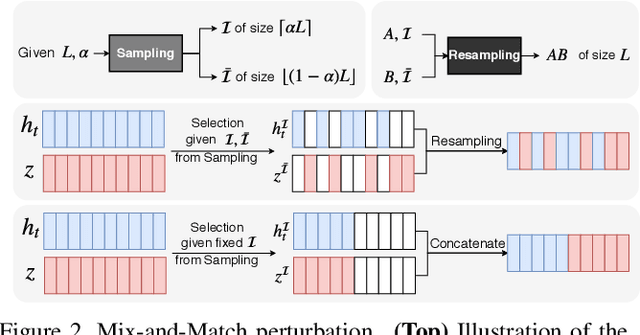
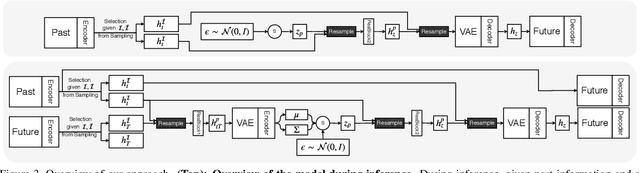

Human motion prediction is a stochastic process: Given an observed sequence of poses, multiple future motions are plausible. Existing approaches to modeling this stochasticity typically combine a random noise vector with information about the previous poses. This combination, however, is done in a deterministic manner, which gives the network the flexibility to learn to ignore the random noise. In this paper, we introduce an approach to stochastically combine the root of variations with previous pose information, which forces the model to take the noise into account. We exploit this idea for motion prediction by incorporating it into a recurrent encoder-decoder network with a conditional variational autoencoder block that learns to exploit the perturbations. Our experiments demonstrate that our model yields high-quality pose sequences that are much more diverse than those from state-of-the-art stochastic motion prediction techniques.
VIENA2: A Driving Anticipation Dataset
Oct 29, 2018

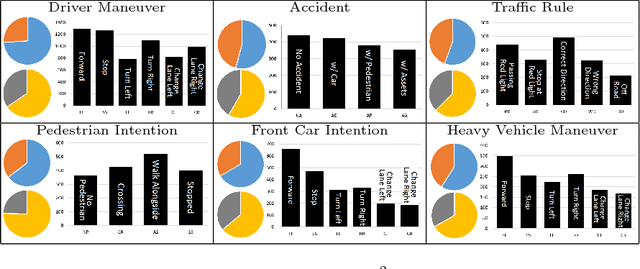
Action anticipation is critical in scenarios where one needs to react before the action is finalized. This is, for instance, the case in automated driving, where a car needs to, e.g., avoid hitting pedestrians and respect traffic lights. While solutions have been proposed to tackle subsets of the driving anticipation tasks, by making use of diverse, task-specific sensors, there is no single dataset or framework that addresses them all in a consistent manner. In this paper, we therefore introduce a new, large-scale dataset, called VIENA2, covering 5 generic driving scenarios, with a total of 25 distinct action classes. It contains more than 15K full HD, 5s long videos acquired in various driving conditions, weathers, daytimes and environments, complemented with a common and realistic set of sensor measurements. This amounts to more than 2.25M frames, each annotated with an action label, corresponding to 600 samples per action class. We discuss our data acquisition strategy and the statistics of our dataset, and benchmark state-of-the-art action anticipation techniques, including a new multi-modal LSTM architecture with an effective loss function for action anticipation in driving scenarios.
Effective Use of Synthetic Data for Urban Scene Semantic Segmentation
Jul 16, 2018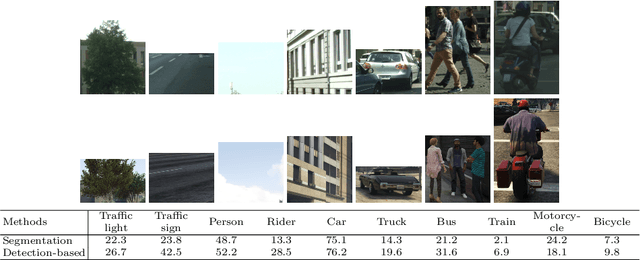
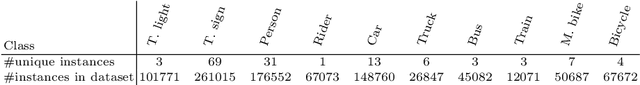

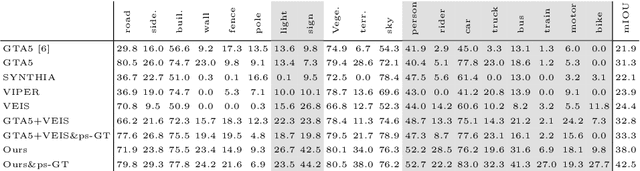
Training a deep network to perform semantic segmentation requires large amounts of labeled data. To alleviate the manual effort of annotating real images, researchers have investigated the use of synthetic data, which can be labeled automatically. Unfortunately, a network trained on synthetic data performs relatively poorly on real images. While this can be addressed by domain adaptation, existing methods all require having access to real images during training. In this paper, we introduce a drastically different way to handle synthetic images that does not require seeing any real images at training time. Our approach builds on the observation that foreground and background classes are not affected in the same manner by the domain shift, and thus should be treated differently. In particular, the former should be handled in a detection-based manner to better account for the fact that, while their texture in synthetic images is not photo-realistic, their shape looks natural. Our experiments evidence the effectiveness of our approach on Cityscapes and CamVid with models trained on synthetic data only.
Bringing Background into the Foreground: Making All Classes Equal in Weakly-supervised Video Semantic Segmentation
Aug 15, 2017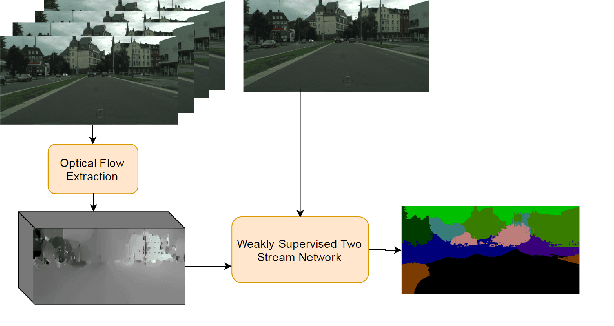

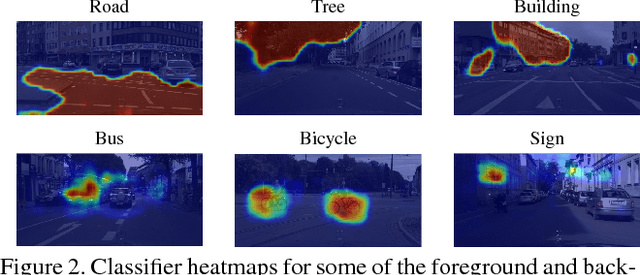
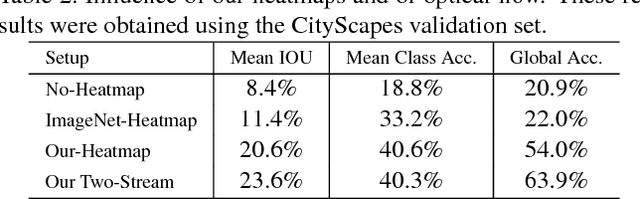
Pixel-level annotations are expensive and time-consuming to obtain. Hence, weak supervision using only image tags could have a significant impact in semantic segmentation. Recent years have seen great progress in weakly-supervised semantic segmentation, whether from a single image or from videos. However, most existing methods are designed to handle a single background class. In practical applications, such as autonomous navigation, it is often crucial to reason about multiple background classes. In this paper, we introduce an approach to doing so by making use of classifier heatmaps. We then develop a two-stream deep architecture that jointly leverages appearance and motion, and design a loss based on our heatmaps to train it. Our experiments demonstrate the benefits of our classifier heatmaps and of our two-stream architecture on challenging urban scene datasets and on the YouTube-Objects benchmark, where we obtain state-of-the-art results.
Encouraging LSTMs to Anticipate Actions Very Early
Aug 14, 2017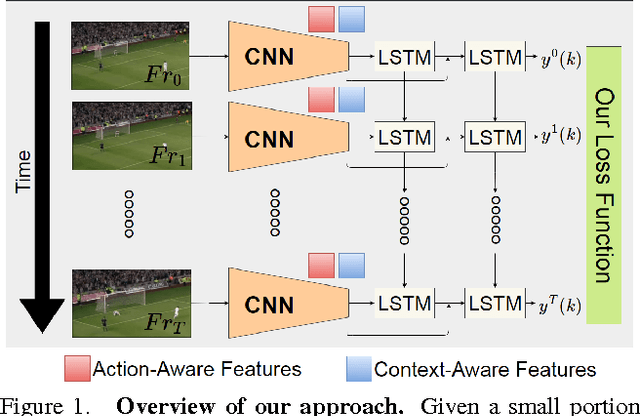
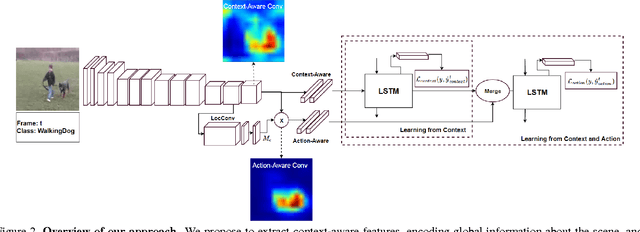


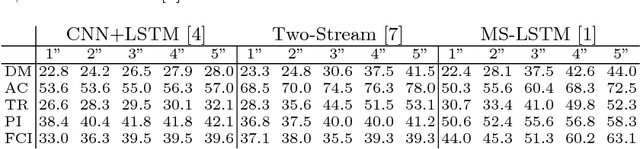
In contrast to the widely studied problem of recognizing an action given a complete sequence, action anticipation aims to identify the action from only partially available videos. As such, it is therefore key to the success of computer vision applications requiring to react as early as possible, such as autonomous navigation. In this paper, we propose a new action anticipation method that achieves high prediction accuracy even in the presence of a very small percentage of a video sequence. To this end, we develop a multi-stage LSTM architecture that leverages context-aware and action-aware features, and introduce a novel loss function that encourages the model to predict the correct class as early as possible. Our experiments on standard benchmark datasets evidence the benefits of our approach; We outperform the state-of-the-art action anticipation methods for early prediction by a relative increase in accuracy of 22.0% on JHMDB-21, 14.0% on UT-Interaction and 49.9% on UCF-101.
Incorporating Network Built-in Priors in Weakly-supervised Semantic Segmentation
Jun 06, 2017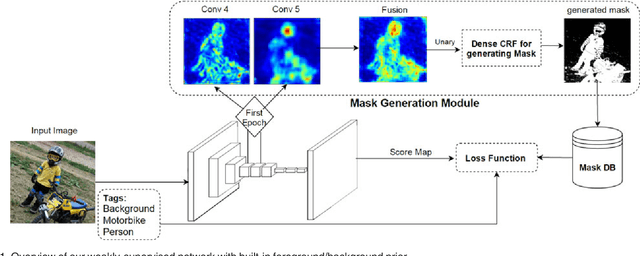
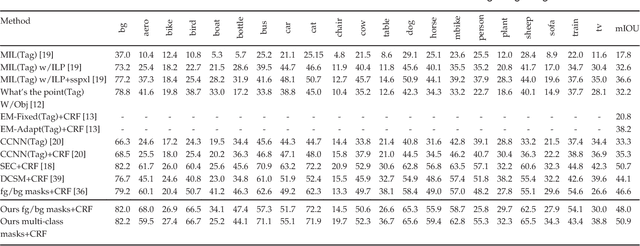
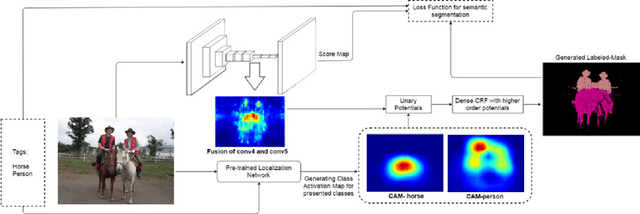
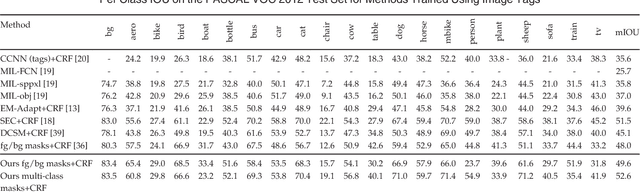
Pixel-level annotations are expensive and time consuming to obtain. Hence, weak supervision using only image tags could have a significant impact in semantic segmentation. Recently, CNN-based methods have proposed to fine-tune pre-trained networks using image tags. Without additional information, this leads to poor localization accuracy. This problem, however, was alleviated by making use of objectness priors to generate foreground/background masks. Unfortunately these priors either require pixel-level annotations/bounding boxes, or still yield inaccurate object boundaries. Here, we propose a novel method to extract accurate masks from networks pre-trained for the task of object recognition, thus forgoing external objectness modules. We first show how foreground/background masks can be obtained from the activations of higher-level convolutional layers of a network. We then show how to obtain multi-class masks by the fusion of foreground/background ones with information extracted from a weakly-supervised localization network. Our experiments evidence that exploiting these masks in conjunction with a weakly-supervised training loss yields state-of-the-art tag-based weakly-supervised semantic segmentation results.