 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-level Deep Sign Language Recognition from Video: A New Large-scale Dataset and Methods Comparison
Oct 24, 2019



Vision-based sign language recognition aims at helping the hearing-impaired people to communicate with others. However, most existing sign language datasets are limited to a small number of words. Due to the limited vocabulary size, models learned from those datasets cannot be applied in practice. In this paper, we introduce a new large-scale Word-Level American Sign Language (WLASL) video dataset, containing more than 2000 words performed by over 100 signers. This dataset will be made publicly available to the research community. To our knowledge, it is by far the largest public ASL dataset to facilitate word-level sign recognition research. Based on this new large-scale dataset, we are able to experiment with several deep learning methods for word-level sign recognition and evaluate their performances in large scale scenarios. Specifically we implement and compare two different models,i.e., (i) holistic visual appearance-based approach, and (ii) 2D human pose based approach. Both models are valuable baselines that will benefit the community for method benchmarking. Moreover, we also propose a novel pose-based temporal graph convolution networks (Pose-TGCN) that models spatial and temporal dependencies in human pose trajectories simultaneously, which has further boosted the performance of the pose-based method. Our results show that pose-based and appearance-based models achieve comparable performances up to 66% at top-10 accuracy on 2,000 words/glosses, demonstrating the validity and challenges of our dataset. We will make the large-scale dataset, as well as our baseline deep models, freely available online.
Proposal-free Temporal Moment Localization of a Natural-Language Query in Video using Guided Attention
Aug 20, 2019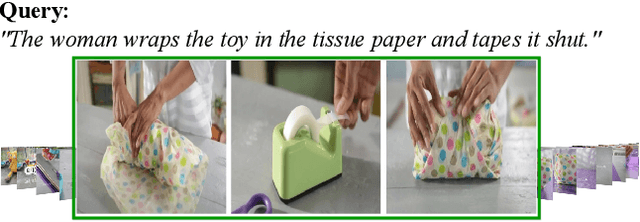
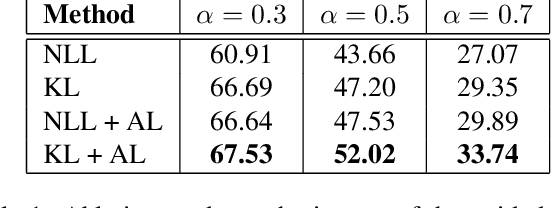
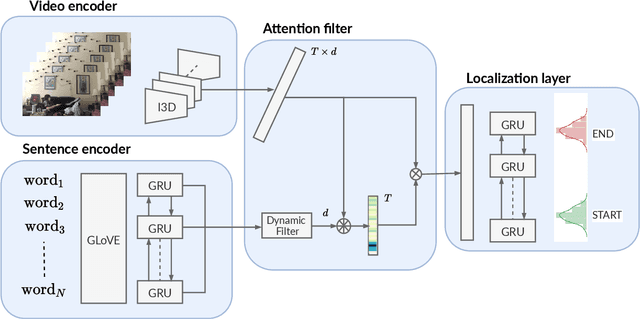
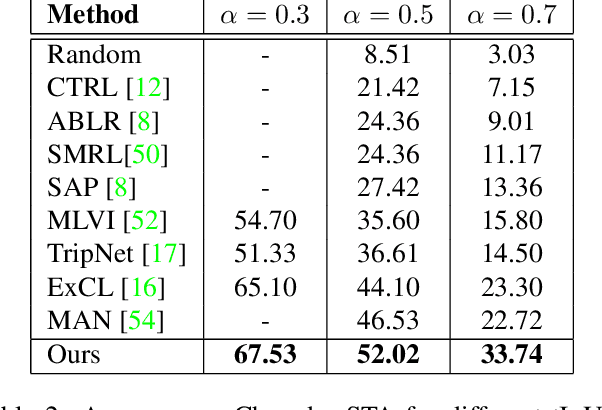
This paper studies the problem of temporal moment localization in a long untrimmed video using natural language as the query. Given an untrimmed video and a sentence as the query, the goal is to determine the starting, and the ending, of the relevant visual moment in the video, that corresponds to the query sentence. While previous works have tackled this task by a propose-and-rank approach, we introduce a more efficient, end-to-end trainable, and {\em proposal-free approach} that relies on three key components: a dynamic filter to transfer language information to the visual domain, a new loss function to guide our model to attend the most relevant parts of the video, and soft labels to model annotation uncertainty. We evaluate our method on two benchmark datasets, Charades-STA and ActivityNet-Captions. Experimental results show that our approach outperforms state-of-the-art methods on both datasets.