 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIENA2: A Driving Anticipation Dataset
Oct 29, 2018

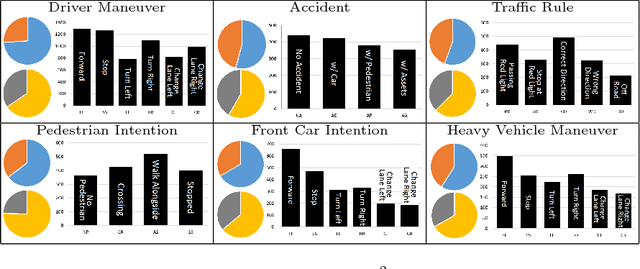
Action anticipation is critical in scenarios where one needs to react before the action is finalized. This is, for instance, the case in automated driving, where a car needs to, e.g., avoid hitting pedestrians and respect traffic lights. While solutions have been proposed to tackle subsets of the driving anticipation tasks, by making use of diverse, task-specific sensors, there is no single dataset or framework that addresses them all in a consistent manner. In this paper, we therefore introduce a new, large-scale dataset, called VIENA2, covering 5 generic driving scenarios, with a total of 25 distinct action classes. It contains more than 15K full HD, 5s long videos acquired in various driving conditions, weathers, daytimes and environments, complemented with a common and realistic set of sensor measurements. This amounts to more than 2.25M frames, each annotated with an action label, corresponding to 600 samples per action class. We discuss our data acquisition strategy and the statistics of our dataset, and benchmark state-of-the-art action anticipation techniques, including a new multi-modal LSTM architecture with an effective loss function for action anticipation in driving scenarios.
Encouraging LSTMs to Anticipate Actions Very Early
Aug 14, 2017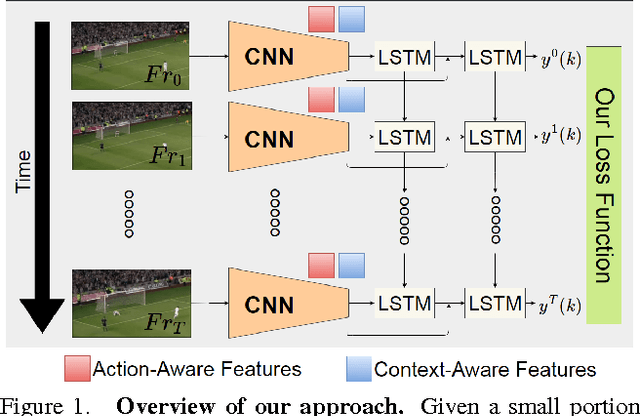
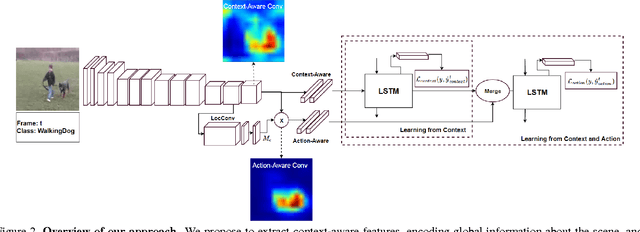


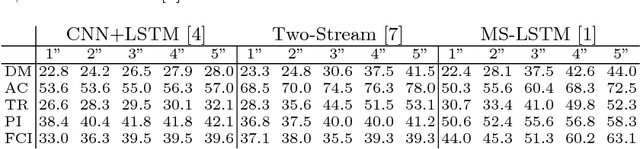
In contrast to the widely studied problem of recognizing an action given a complete sequence, action anticipation aims to identify the action from only partially available videos. As such, it is therefore key to the success of computer vision applications requiring to react as early as possible, such as autonomous navigation. In this paper, we propose a new action anticipation method that achieves high prediction accuracy even in the presence of a very small percentage of a video sequence. To this end, we develop a multi-stage LSTM architecture that leverages context-aware and action-aware features, and introduce a novel loss function that encourages the model to predict the correct class as early as possible. Our experiments on standard benchmark datasets evidence the benefits of our approach; We outperform the state-of-the-art action anticipation methods for early prediction by a relative increase in accuracy of 22.0% on JHMDB-21, 14.0% on UT-Interaction and 49.9% on UCF-101.
Deep Action- and Context-Aware Sequence Learning for Activity Recognition and Anticipation
Nov 18, 2016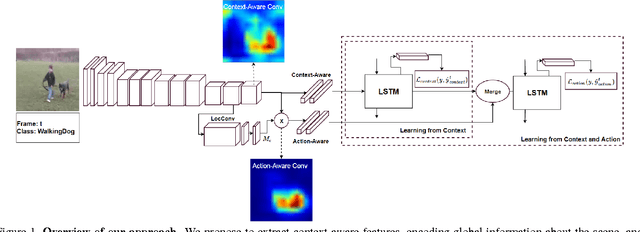
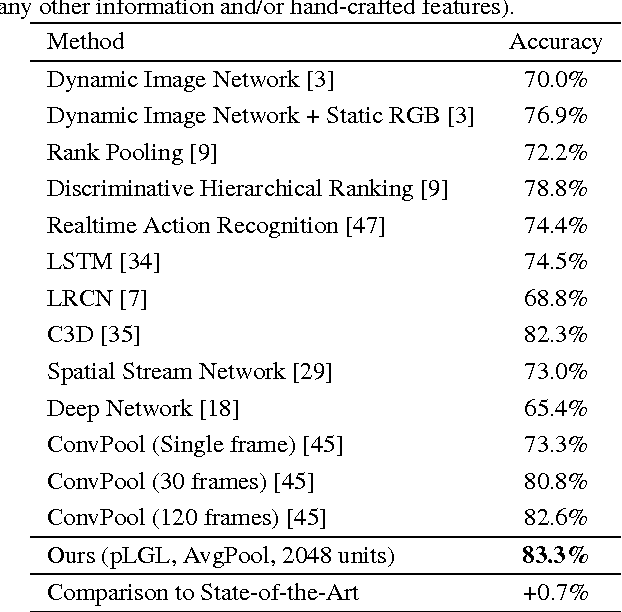
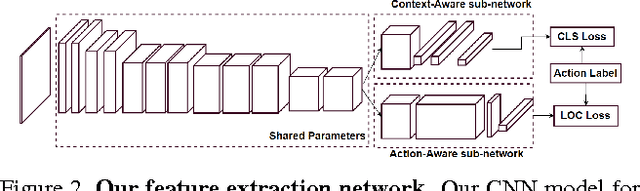
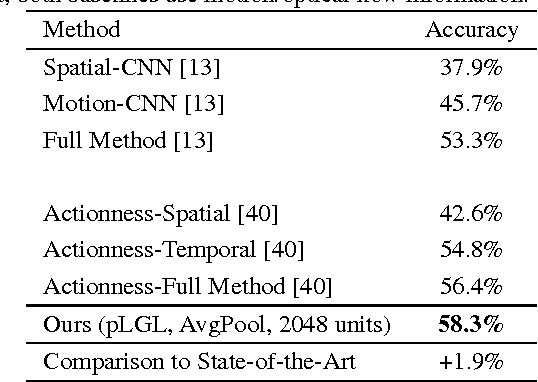
Action recognition and anticipation are key to the success of many computer vision applications. Existing methods can roughly be grouped into those that extract global, context-aware representations of the entire image or sequence, and those that aim at focusing on the regions where the action occurs. While the former may suffer from the fact that context is not always reliable, the latter completely ignore this source of information, which can nonetheless be helpful in many situations. In this paper, we aim at making the best of both worlds by developing an approach that leverages both context-aware and action-aware features. At the core of our method lies a novel multi-stage recurrent architecture that allows us to effectively combine these two sources of information throughout a video. This architecture first exploits the global, context-aware features, and merges the resulting representation with the localized, action-aware ones. Our experiments on standard datasets evidence the benefits of our approach over methods that use each information type separately. We outperform the state-of-the-art methods that, as us, rely only on RGB frames as input for both action recognition and anticipation.