 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Action- and Context-Aware Sequence Learning for Activity Recognition and Anticipation
Nov 18, 2016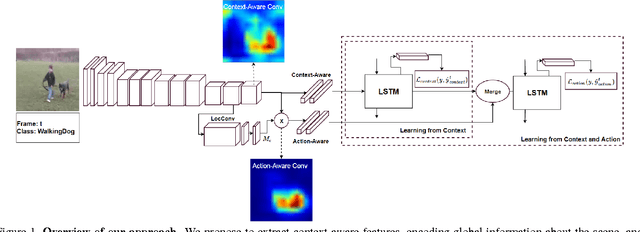
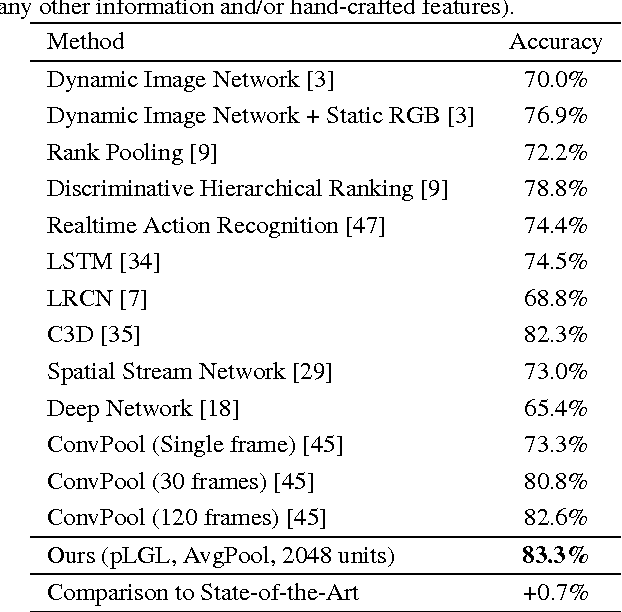
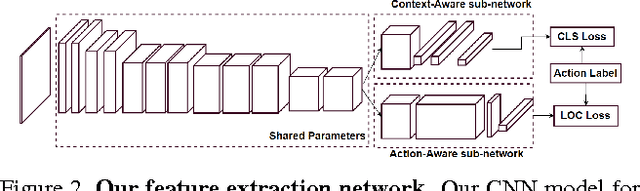
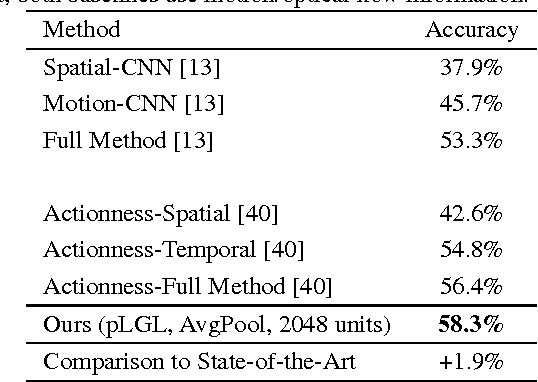
Action recognition and anticipation are key to the success of many computer vision applications. Existing methods can roughly be grouped into those that extract global, context-aware representations of the entire image or sequence, and those that aim at focusing on the regions where the action occurs. While the former may suffer from the fact that context is not always reliable, the latter completely ignore this source of information, which can nonetheless be helpful in many situations. In this paper, we aim at making the best of both worlds by developing an approach that leverages both context-aware and action-aware features. At the core of our method lies a novel multi-stage recurrent architecture that allows us to effectively combine these two sources of information throughout a video. This architecture first exploits the global, context-aware features, and merges the resulting representation with the localized, action-aware ones. Our experiments on standard datasets evidence the benefits of our approach over methods that use each information type separately. We outperform the state-of-the-art methods that, as us, rely only on RGB frames as input for both action recognition and anticipation.
Built-in Foreground/Background Prior for Weakly-Supervised Semantic Segmentation
Sep 02, 2016

Pixel-level annotations are expensive and time consuming to obtain. Hence, weak supervision using only image tags could have a significant impact in semantic segmentation. Recently, CNN-based methods have proposed to fine-tune pre-trained networks using image tags. Without additional information, this leads to poor localization accuracy. This problem, however, was alleviated by making use of objectness priors to generate foreground/background masks. Unfortunately these priors either require training pixel-level annotations/bounding boxes, or still yield inaccurate object boundaries. Here, we propose a novel method to extract markedly more accurate masks from the pre-trained network itself, forgoing external objectness modules. This is accomplished using the activations of the higher-level convolutional layers, smoothed by a dense CRF. We demonstrate that our method, based on these masks and a weakly-supervised loss, outperforms the state-of-the-art tag-based weakly-supervised semantic segmentation techniques. Furthermore, we introduce a new form of inexpensive weak supervision yielding an additional accuracy boost.