 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Background into the Foreground: Making All Classes Equal in Weakly-supervised Video Semantic Segmentation
Paper and Code
Aug 15, 2017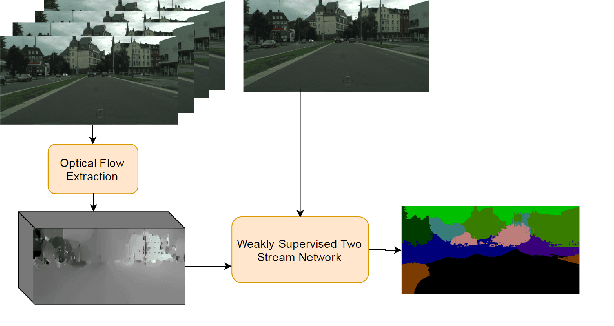

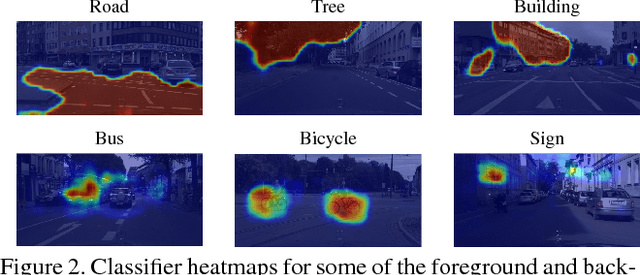
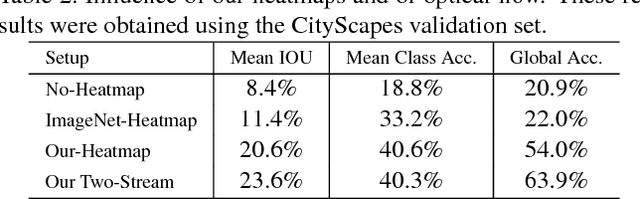
Pixel-level annotations are expensive and time-consuming to obtain. Hence, weak supervision using only image tags could have a significant impact in semantic segmentation. Recent years have seen great progress in weakly-supervised semantic segmentation, whether from a single image or from videos. However, most existing methods are designed to handle a single background class. In practical applications, such as autonomous navigation, it is often crucial to reason about multiple background classes. In this paper, we introduce an approach to doing so by making use of classifier heatmaps. We then develop a two-stream deep architecture that jointly leverages appearance and motion, and design a loss based on our heatmaps to train it. Our experiments demonstrate the benefits of our classifier heatmaps and of our two-stream architecture on challenging urban scene datasets and on the YouTube-Objects benchmark, where we obtain state-of-the-art results.