 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling Good Latent Variables via CPP-VAEs: VAEs with Condition Posterior as Prior
Paper and Code
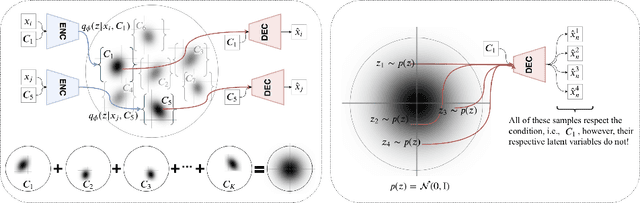
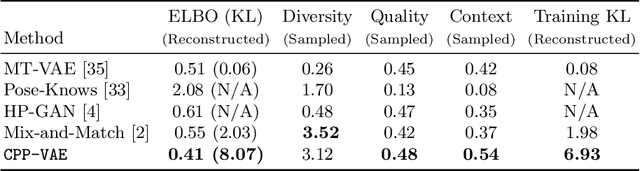
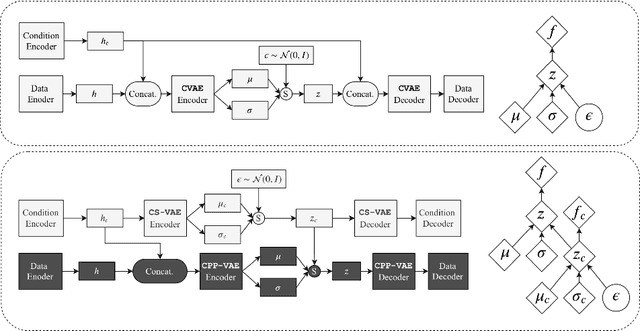

In practice, conditional variational autoencoders (CVAEs) perform conditioning by combining two sources of information which are computed completely independently; CVAEs first compute the condition, then sample the latent variable, and finally concatenate these two sources of information. However, these two processes should be tied together such that the model samples a latent variable given the conditioning signal. In this paper, we directly address this by conditioning the sampling of the latent variable on the CVAE condition, thus encouraging it to carry relevant information. We study this specifically for tasks that leverage with strong conditioning signals and where the generative models have highly expressive decoders able to generate a sample based on the information contained in the condition solely. In particular, we experiments with the two challenging tasks of diverse human motion generation and diverse image captioning, for which our results suggest that unifying latent variable sampling and conditioning not only yields samples of higher quality, but also helps the model to avoid the posterior collapse, a known problem of VAEs with expressive decoders.