 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAfriMTE and AfriCOMET: Empowering COMET to Embrace Under-resourced African Languages
Nov 16, 2023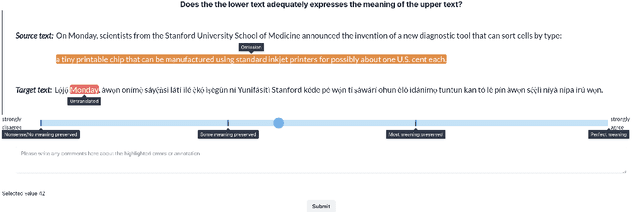
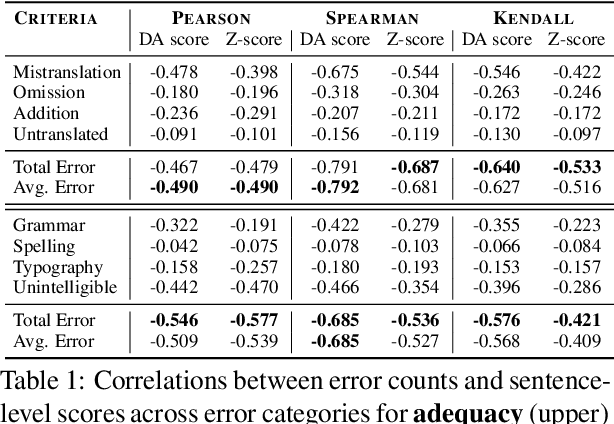
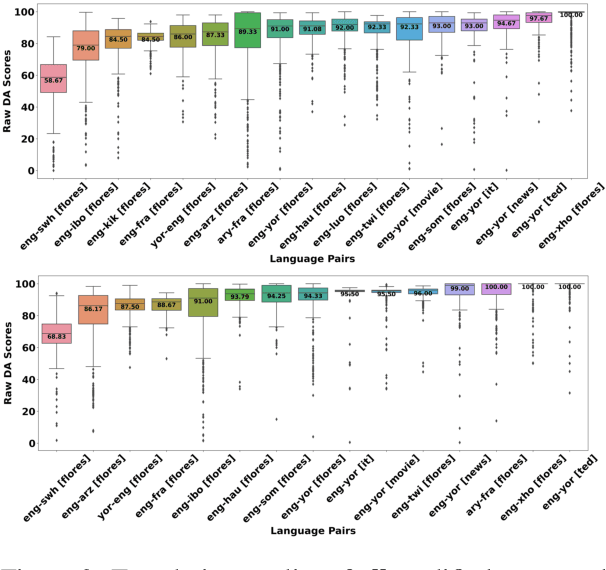
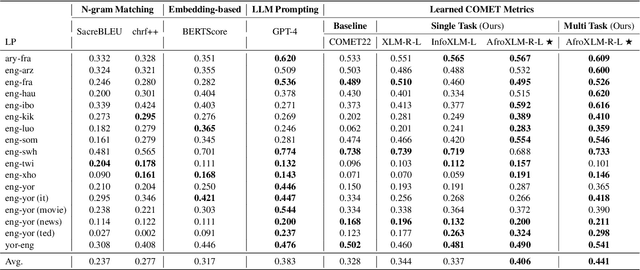
Despite the progress we have recorded in scaling multilingual machine translation (MT) models and evaluation data to several under-resourced African languages, it is difficult to measure accurately the progress we have made on these languages because evaluation is often performed on n-gram matching metrics like BLEU that often have worse correlation with human judgments. Embedding-based metrics such as COMET correlate better; however, lack of evaluation data with human ratings for under-resourced languages, complexity of annotation guidelines like Multidimensional Quality Metrics (MQM), and limited language coverage of multilingual encoders have hampered their applicability to African languages. In this paper, we address these challenges by creating high-quality human evaluation data with a simplified MQM guideline for error-span annotation and direct assessment (DA) scoring for 13 typologically diverse African languages. Furthermore, we develop AfriCOMET, a COMET evaluation metric for African languages by leveraging DA training data from high-resource languages and African-centric multilingual encoder (AfroXLM-Roberta) to create the state-of-the-art evaluation metric for African languages MT with respect to Spearman-rank correlation with human judgments (+0.406).
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
AfriSenti: A Twitter Sentiment Analysis Benchmark for African Languages
Feb 17, 2023



Africa is home to over 2000 languages from over six language families and has the highest linguistic diversity among all continents. This includes 75 languages with at least one million speakers each. Yet, there is little NLP research conducted on African languages. Crucial in enabling such research is the availability of high-quality annotated datasets. In this paper, we introduce AfriSenti, which consists of 14 sentiment datasets of 110,000+ tweets in 14 African languages (Amharic, Algerian Arabic, Hausa, Igbo, Kinyarwanda, Moroccan Arabic, Mozambican Portuguese, Nigerian Pidgin, Oromo, Swahili, Tigrinya, Twi, Xitsonga, and Yor\`ub\'a) from four language families annotated by native speakers. The data is used in SemEval 2023 Task 12, the first Afro-centric SemEval shared task. We describe the data collection methodology, annotation process, and related challenges when curating each of the datasets. We conduct experiments with different sentiment classification baselines and discuss their usefulness. We hope AfriSenti enables new work on under-represented languages. The dataset is available at https://github.com/afrisenti-semeval/afrisent-semeval-2023 and can also be loaded as a huggingface datasets (https://huggingface.co/datasets/shmuhammad/AfriSenti).
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022
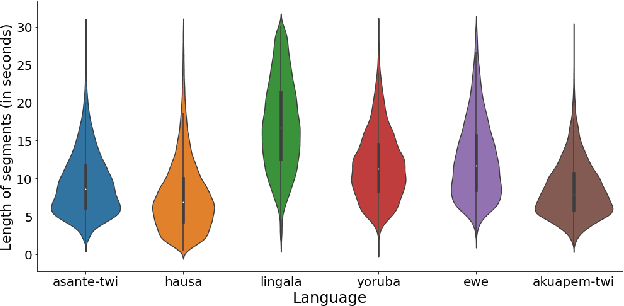

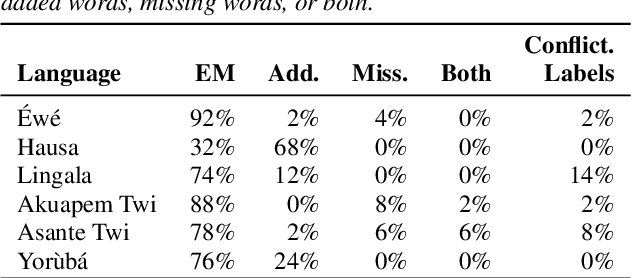
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
English-Twi Parallel Corpus for Machine Translation
Apr 01, 2021


We present a parallel machine translation training corpus for English and Akuapem Twi of 25,421 sentence pairs. We used a transformer-based translator to generate initial translations in Akuapem Twi, which were later verified and corrected where necessary by native speakers to eliminate any occurrence of translationese. In addition, 697 higher quality crowd-sourced sentences are provided for use as an evaluation set for downstream Natural Language Processing (NLP) tasks. The typical use case for the larger human-verified dataset is for further training of machine translation models in Akuapem Twi. The higher quality 697 crowd-sourced dataset is recommended as a testing dataset for machine translation of English to Twi and Twi to English models. Furthermore, the Twi part of the crowd-sourced data may also be used for other tasks, such as representation learning, classification, etc. We fine-tune the transformer translation model on the training corpus and report benchmarks on the crowd-sourced test set.
NLP for Ghanaian Languages
Apr 01, 2021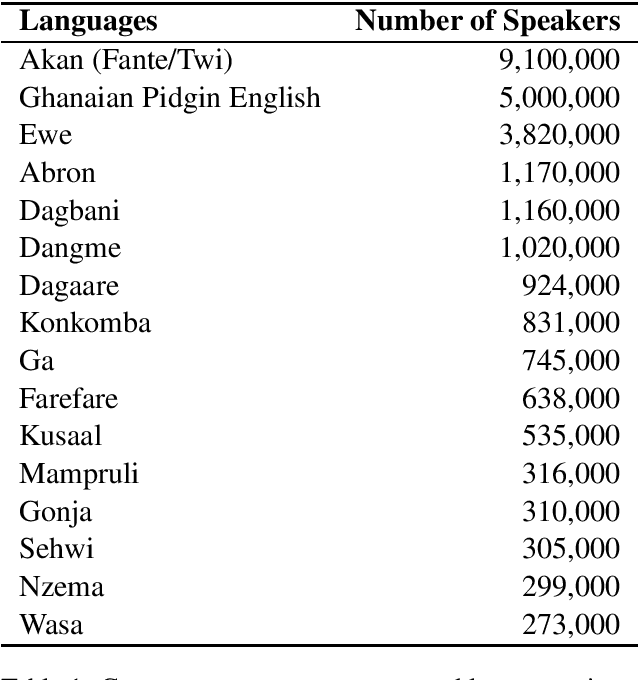
NLP Ghana is an open-source non-profit organization aiming to advance the development and adoption of state-of-the-art NLP techniques and digital language tools to Ghanaian languages and problems. In this paper, we first present the motivation and necessity for the efforts of the organization; by introducing some popular Ghanaian languages while presenting the state of NLP in Ghana. We then present the NLP Ghana organization and outline its aims, scope of work, some of the methods employed and contributions made thus far in the NLP community in Ghana.
Contextual Text Embeddings for Twi
Mar 31, 2021
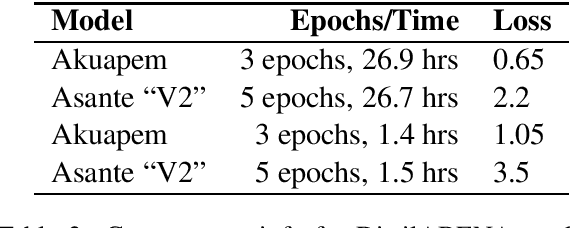


Transformer-based language models have been changing the modern Natural Language Processing (NLP) landscape for high-resource languages such as English, Chinese, Russian, etc. However, this technology does not yet exist for any Ghanaian language. In this paper, we introduce the first of such models for Twi or Akan, the most widely spoken Ghanaian language. The specific contribution of this research work is the development of several pretrained transformer language models for the Akuapem and Asante dialects of Twi, paving the way for advances in application areas such as Named Entity Recognition (NER), Neural Machine Translation (NMT), Sentiment Analysis (SA) and Part-of-Speech (POS) tagging. Specifically, we introduce four different flavours of ABENA -- A BERT model Now in Akan that is fine-tuned on a set of Akan corpora, and BAKO - BERT with Akan Knowledge only, which is trained from scratch. We open-source the model through the Hugging Face model hub and demonstrate its use via a simple sentiment classification example.