 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGhanaNLP Parallel Corpora: Comprehensive Multilingual Resources for Low-Resource Ghanaian Languages
Mar 14, 2026Low resource languages present unique challenges for natural language processing due to the limited availability of digitized and well structured linguistic data. To address this gap, the GhanaNLP initiative has developed and curated 41,513 parallel sentence pairs for the Twi, Fante, Ewe, Ga, and Kusaal languages, which are widely spoken across Ghana yet remain underrepresented in digital spaces. Each dataset consists of carefully aligned sentence pairs between a local language and English. The data were collected, translated, and annotated by human professionals and enriched with standard structural metadata to ensure consistency and usability. These corpora are designed to support research, educational, and commercial applications, including machine translation, speech technologies, and language preservation. This paper documents the dataset creation methodology, structure, intended use cases, and evaluation, as well as their deployment in real world applications such as the Khaya AI translation engine. Overall, this work contributes to broader efforts to democratize AI by enabling inclusive and accessible language technologies for African languages.
English-Twi Parallel Corpus for Machine Translation
Apr 01, 2021


We present a parallel machine translation training corpus for English and Akuapem Twi of 25,421 sentence pairs. We used a transformer-based translator to generate initial translations in Akuapem Twi, which were later verified and corrected where necessary by native speakers to eliminate any occurrence of translationese. In addition, 697 higher quality crowd-sourced sentences are provided for use as an evaluation set for downstream Natural Language Processing (NLP) tasks. The typical use case for the larger human-verified dataset is for further training of machine translation models in Akuapem Twi. The higher quality 697 crowd-sourced dataset is recommended as a testing dataset for machine translation of English to Twi and Twi to English models. Furthermore, the Twi part of the crowd-sourced data may also be used for other tasks, such as representation learning, classification, etc. We fine-tune the transformer translation model on the training corpus and report benchmarks on the crowd-sourced test set.
NLP for Ghanaian Languages
Apr 01, 2021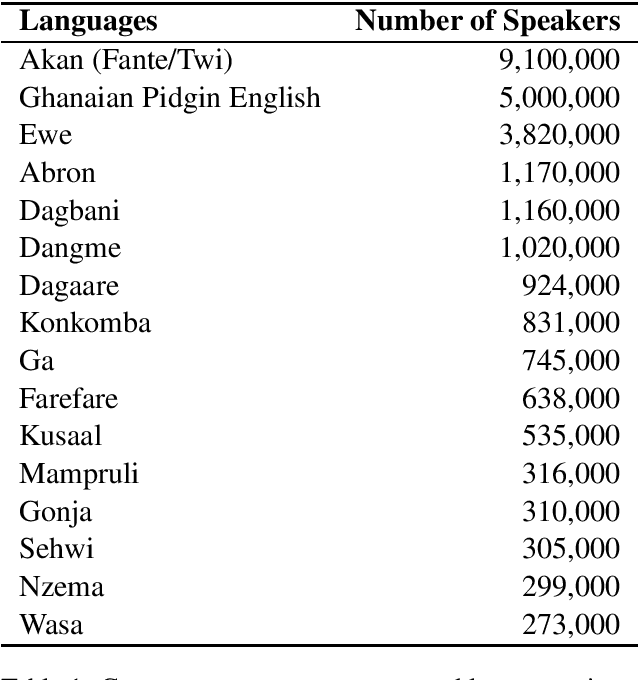
NLP Ghana is an open-source non-profit organization aiming to advance the development and adoption of state-of-the-art NLP techniques and digital language tools to Ghanaian languages and problems. In this paper, we first present the motivation and necessity for the efforts of the organization; by introducing some popular Ghanaian languages while presenting the state of NLP in Ghana. We then present the NLP Ghana organization and outline its aims, scope of work, some of the methods employed and contributions made thus far in the NLP community in Ghana.
Contextual Text Embeddings for Twi
Mar 31, 2021
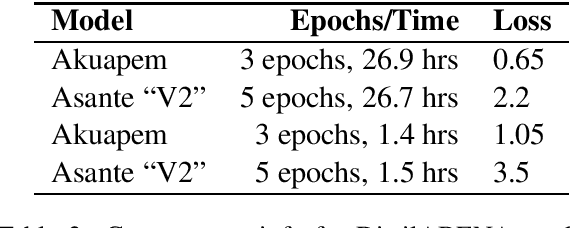


Transformer-based language models have been changing the modern Natural Language Processing (NLP) landscape for high-resource languages such as English, Chinese, Russian, etc. However, this technology does not yet exist for any Ghanaian language. In this paper, we introduce the first of such models for Twi or Akan, the most widely spoken Ghanaian language. The specific contribution of this research work is the development of several pretrained transformer language models for the Akuapem and Asante dialects of Twi, paving the way for advances in application areas such as Named Entity Recognition (NER), Neural Machine Translation (NMT), Sentiment Analysis (SA) and Part-of-Speech (POS) tagging. Specifically, we introduce four different flavours of ABENA -- A BERT model Now in Akan that is fine-tuned on a set of Akan corpora, and BAKO - BERT with Akan Knowledge only, which is trained from scratch. We open-source the model through the Hugging Face model hub and demonstrate its use via a simple sentiment classification example.
Using Deep Networks and Transfer Learning to Address Disinformation
May 24, 2019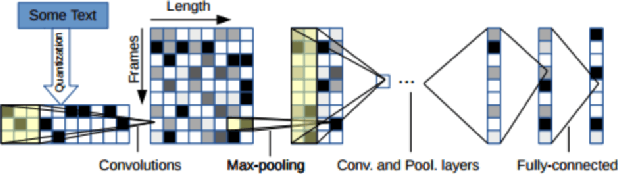
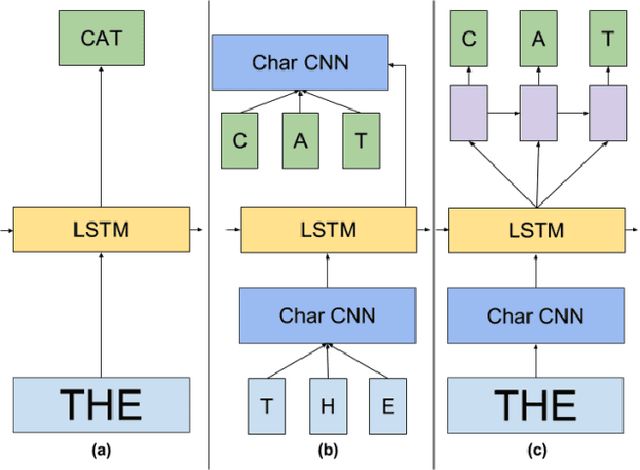
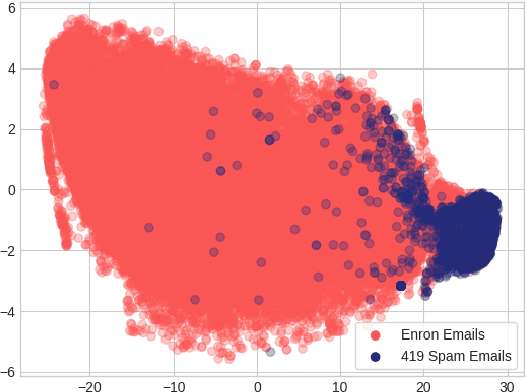
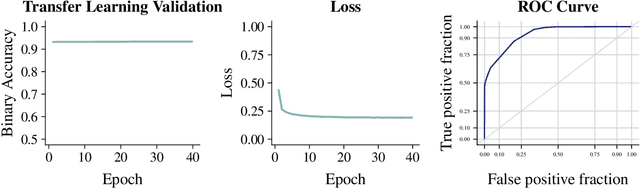
We apply an ensemble pipeline composed of a character-level convolutional neural network (CNN) and a long short-term memory (LSTM) as a general tool for addressing a range of disinformation problems. We also demonstrate the ability to use this architecture to transfer knowledge from labeled data in one domain to related (supervised and unsupervised) tasks. Character-level neural networks and transfer learning are particularly valuable tools in the disinformation space because of the messy nature of social media, lack of labeled data, and the multi-channel tactics of influence campaigns. We demonstrate their effectiveness in several tasks relevant for detecting disinformation: spam emails, review bombing, political sentiment, and conversation clustering.
Semantic Classification of Tabular Datasets via Character-Level Convolutional Neural Networks
Jan 24, 2019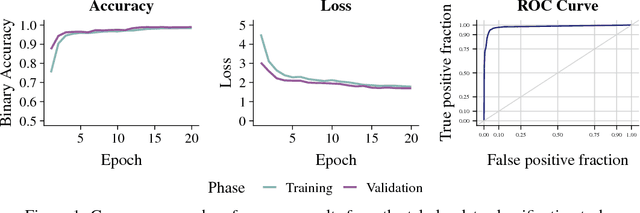
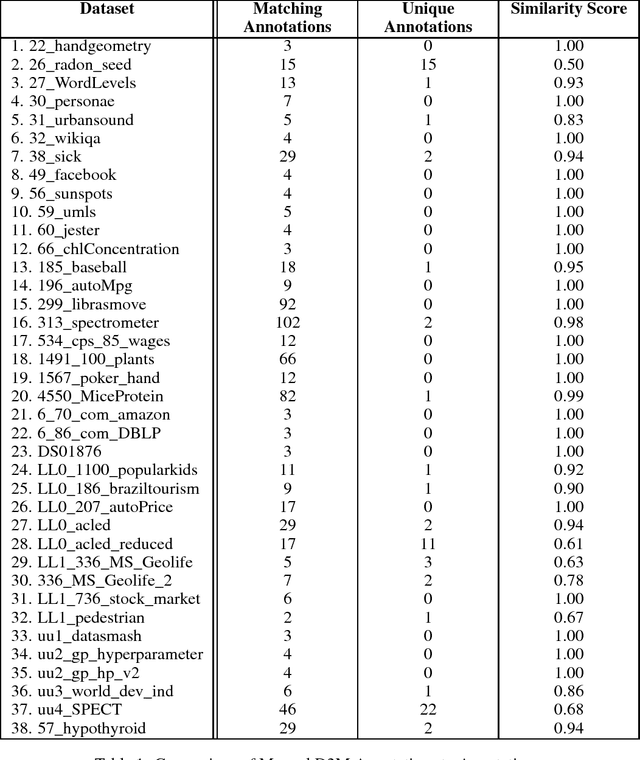
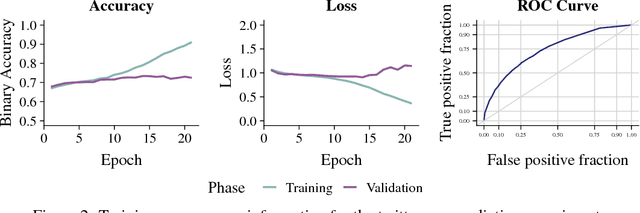
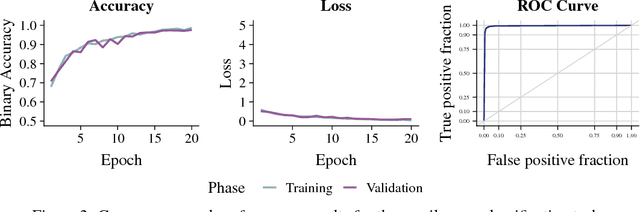
A character-level convolutional neural network (CNN) motivated by applications in "automated machine learning" (AutoML) is proposed to semantically classify columns in tabular data. Simulated data containing a set of base classes is first used to learn an initial set of weights. Hand-labeled data from the CKAN repository is then used in a transfer-learning paradigm to adapt the initial weights to a more sophisticated representation of the problem (e.g., including more classes). In doing so, realistic data imperfections are learned and the set of classes handled can be expanded from the base set with reduced labeled data and computing power requirements. Results show the effectiveness and flexibility of this approach in three diverse domains: semantic classification of tabular data, age prediction from social media posts, and email spam classification. In addition to providing further evidence of the effectiveness of transfer learning in natural language processing (NLP), our experiments suggest that analyzing the semantic structure of language at the character level without additional metadata---i.e., network structure, headers, etc.---can produce competitive accuracy for type classification, spam classification, and social media age prediction. We present our open-source toolkit SIMON, an acronym for Semantic Inference for the Modeling of ONtologies, which implements this approach in a user-friendly and scalable/parallelizable fashion.
Abstractive Tabular Dataset Summarization via Knowledge Base Semantic Embeddings
Apr 05, 2018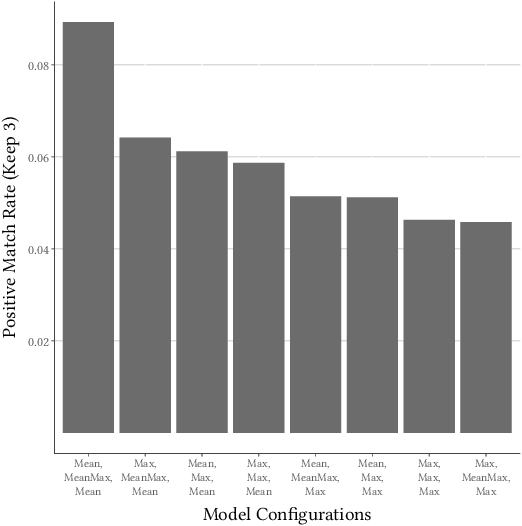
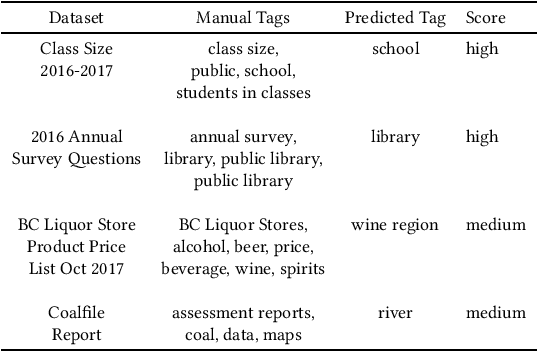
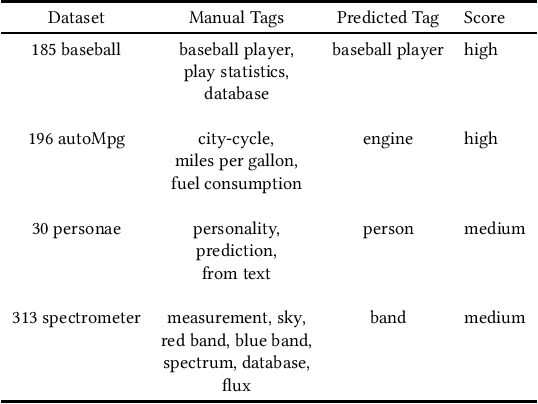
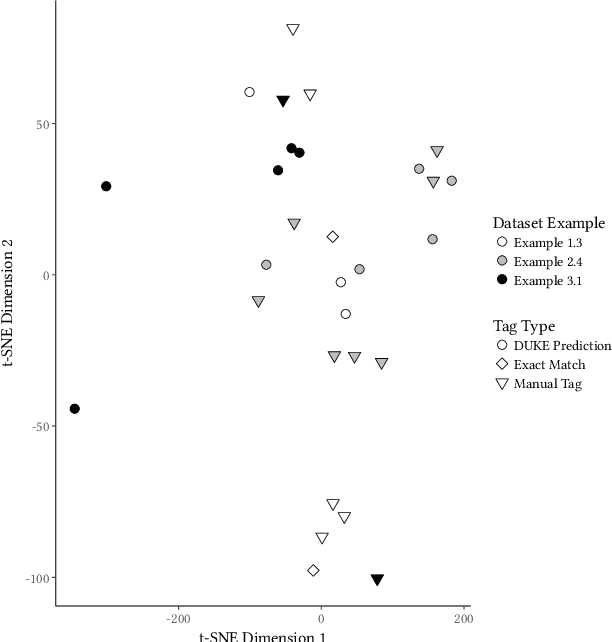
This paper describes an abstractive summarization method for tabular data which employs a knowledge base semantic embedding to generate the summary. Assuming the dataset contains descriptive text in headers, columns and/or some augmenting metadata, the system employs the embedding to recommend a subject/type for each text segment. Recommendations are aggregated into a small collection of super types considered to be descriptive of the dataset by exploiting the hierarchy of types in a pre-specified ontology. Using February 2015 Wikipedia as the knowledge base, and a corresponding DBpedia ontology as types, we present experimental results on open data taken from several sources--OpenML, CKAN and data.world--to illustrate the effectiveness of the approach.