 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnglish-Twi Parallel Corpus for Machine Translation
Apr 01, 2021


We present a parallel machine translation training corpus for English and Akuapem Twi of 25,421 sentence pairs. We used a transformer-based translator to generate initial translations in Akuapem Twi, which were later verified and corrected where necessary by native speakers to eliminate any occurrence of translationese. In addition, 697 higher quality crowd-sourced sentences are provided for use as an evaluation set for downstream Natural Language Processing (NLP) tasks. The typical use case for the larger human-verified dataset is for further training of machine translation models in Akuapem Twi. The higher quality 697 crowd-sourced dataset is recommended as a testing dataset for machine translation of English to Twi and Twi to English models. Furthermore, the Twi part of the crowd-sourced data may also be used for other tasks, such as representation learning, classification, etc. We fine-tune the transformer translation model on the training corpus and report benchmarks on the crowd-sourced test set.
NLP for Ghanaian Languages
Apr 01, 2021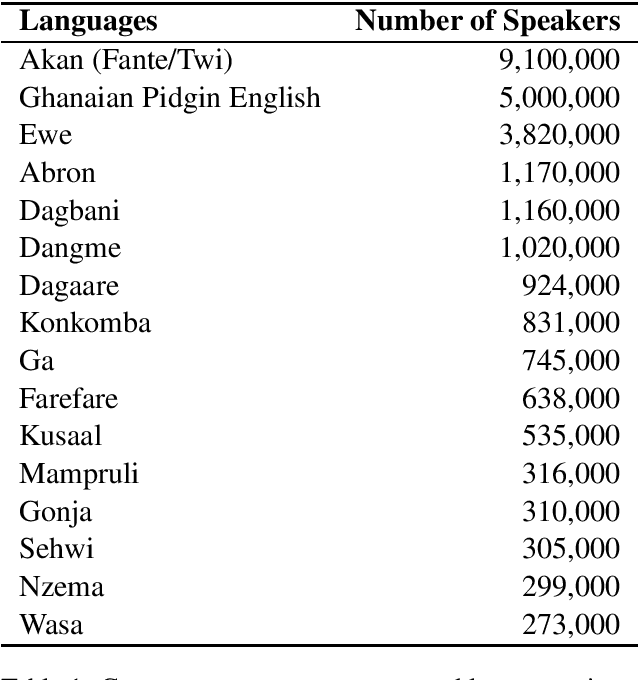
NLP Ghana is an open-source non-profit organization aiming to advance the development and adoption of state-of-the-art NLP techniques and digital language tools to Ghanaian languages and problems. In this paper, we first present the motivation and necessity for the efforts of the organization; by introducing some popular Ghanaian languages while presenting the state of NLP in Ghana. We then present the NLP Ghana organization and outline its aims, scope of work, some of the methods employed and contributions made thus far in the NLP community in Ghana.
Contextual Text Embeddings for Twi
Mar 31, 2021
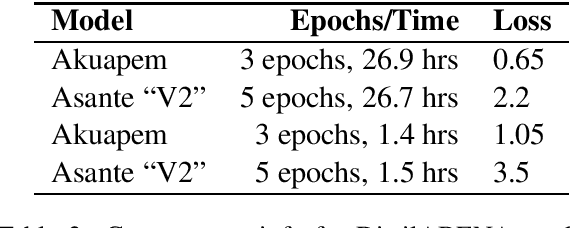


Transformer-based language models have been changing the modern Natural Language Processing (NLP) landscape for high-resource languages such as English, Chinese, Russian, etc. However, this technology does not yet exist for any Ghanaian language. In this paper, we introduce the first of such models for Twi or Akan, the most widely spoken Ghanaian language. The specific contribution of this research work is the development of several pretrained transformer language models for the Akuapem and Asante dialects of Twi, paving the way for advances in application areas such as Named Entity Recognition (NER), Neural Machine Translation (NMT), Sentiment Analysis (SA) and Part-of-Speech (POS) tagging. Specifically, we introduce four different flavours of ABENA -- A BERT model Now in Akan that is fine-tuned on a set of Akan corpora, and BAKO - BERT with Akan Knowledge only, which is trained from scratch. We open-source the model through the Hugging Face model hub and demonstrate its use via a simple sentiment classification example.