 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstractive Tabular Dataset Summarization via Knowledge Base Semantic Embeddings
Paper and Code
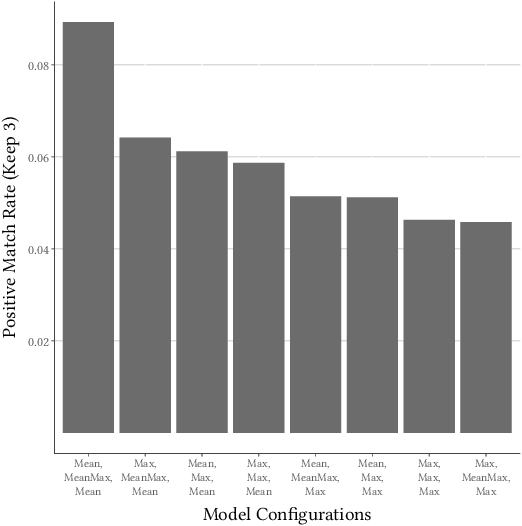
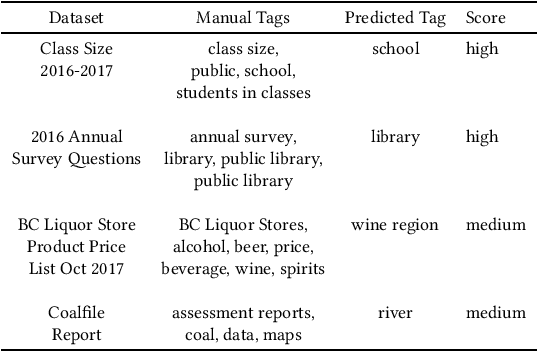
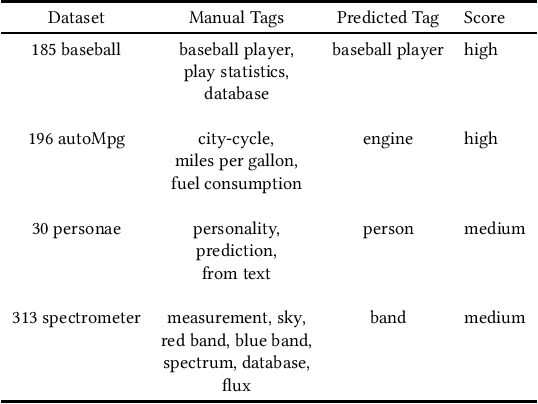
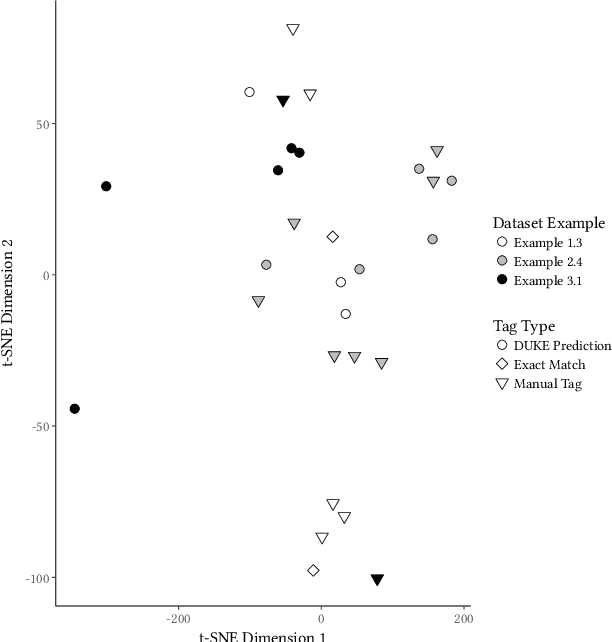
This paper describes an abstractive summarization method for tabular data which employs a knowledge base semantic embedding to generate the summary. Assuming the dataset contains descriptive text in headers, columns and/or some augmenting metadata, the system employs the embedding to recommend a subject/type for each text segment. Recommendations are aggregated into a small collection of super types considered to be descriptive of the dataset by exploiting the hierarchy of types in a pre-specified ontology. Using February 2015 Wikipedia as the knowledge base, and a corresponding DBpedia ontology as types, we present experimental results on open data taken from several sources--OpenML, CKAN and data.world--to illustrate the effectiveness of the approach.