 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Networks and Transfer Learning to Address Disinformation
May 24, 2019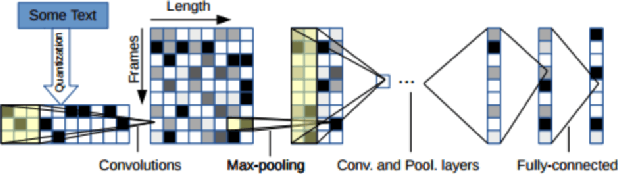
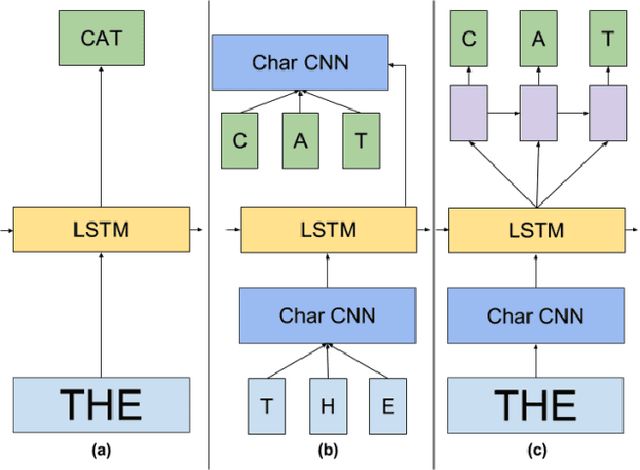
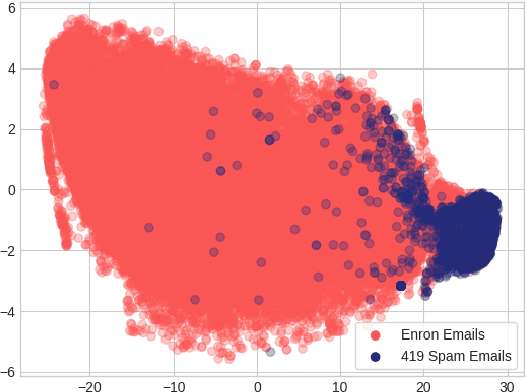
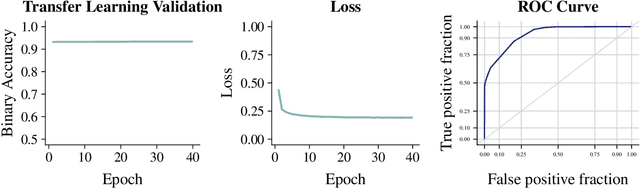
We apply an ensemble pipeline composed of a character-level convolutional neural network (CNN) and a long short-term memory (LSTM) as a general tool for addressing a range of disinformation problems. We also demonstrate the ability to use this architecture to transfer knowledge from labeled data in one domain to related (supervised and unsupervised) tasks. Character-level neural networks and transfer learning are particularly valuable tools in the disinformation space because of the messy nature of social media, lack of labeled data, and the multi-channel tactics of influence campaigns. We demonstrate their effectiveness in several tasks relevant for detecting disinformation: spam emails, review bombing, political sentiment, and conversation clustering.
Semantic Classification of Tabular Datasets via Character-Level Convolutional Neural Networks
Jan 24, 2019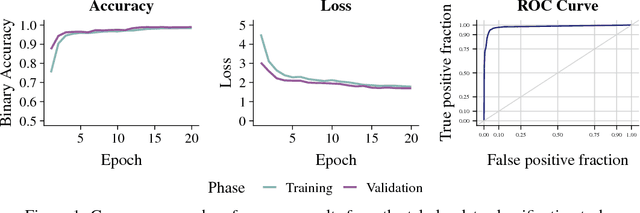
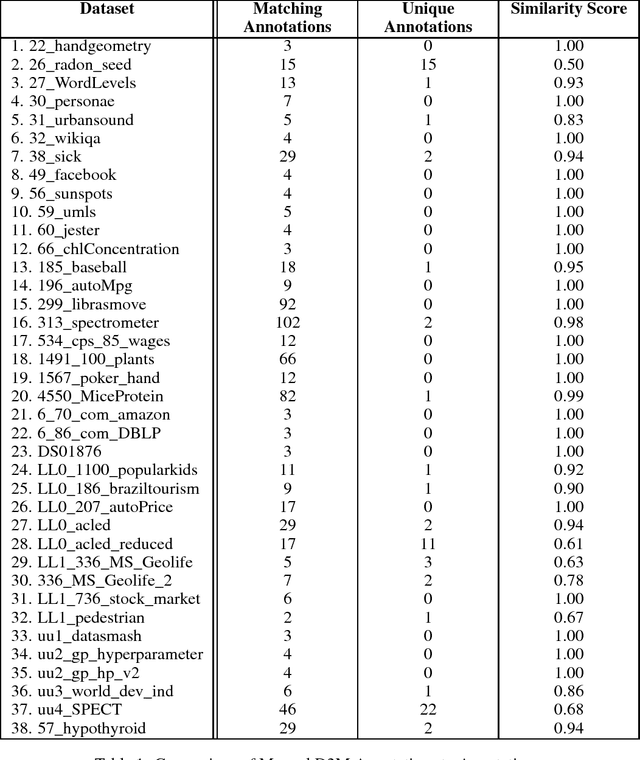
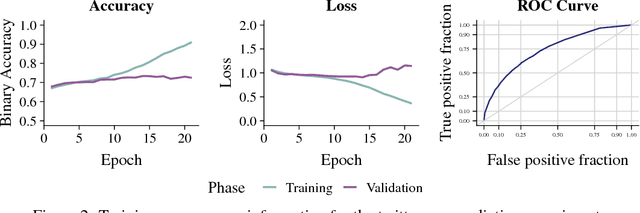
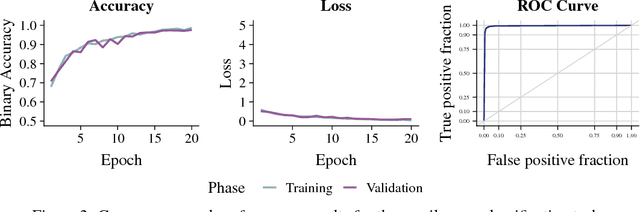
A character-level convolutional neural network (CNN) motivated by applications in "automated machine learning" (AutoML) is proposed to semantically classify columns in tabular data. Simulated data containing a set of base classes is first used to learn an initial set of weights. Hand-labeled data from the CKAN repository is then used in a transfer-learning paradigm to adapt the initial weights to a more sophisticated representation of the problem (e.g., including more classes). In doing so, realistic data imperfections are learned and the set of classes handled can be expanded from the base set with reduced labeled data and computing power requirements. Results show the effectiveness and flexibility of this approach in three diverse domains: semantic classification of tabular data, age prediction from social media posts, and email spam classification. In addition to providing further evidence of the effectiveness of transfer learning in natural language processing (NLP), our experiments suggest that analyzing the semantic structure of language at the character level without additional metadata---i.e., network structure, headers, etc.---can produce competitive accuracy for type classification, spam classification, and social media age prediction. We present our open-source toolkit SIMON, an acronym for Semantic Inference for the Modeling of ONtologies, which implements this approach in a user-friendly and scalable/parallelizable fashion.