 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton Based Action Recognition
Skeleton-based Action Recognition is a computer-vision task that involves recognizing human actions from a sequence of 3D skeletal joint data captured from sensors such as Microsoft Kinect, Intel RealSense, and wearable devices. The goal of skeleton-based action recognition is to develop algorithms that can understand and classify human actions from skeleton data, which can be used in various applications such as human-computer interaction, sports analysis, and surveillance.
Papers and Code
Affinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
SkeFi: Cross-Modal Knowledge Transfer for Wireless Skeleton-Based Action Recognition
Jan 18, 2026Skeleton-based action recognition leverages human pose keypoints to categorize human actions, which shows superior generalization and interoperability compared to regular end-to-end action recognition. Existing solutions use RGB cameras to annotate skeletal keypoints, but their performance declines in dark environments and raises privacy concerns, limiting their use in smart homes and hospitals. This paper explores non-invasive wireless sensors, i.e., LiDAR and mmWave, to mitigate these challenges as a feasible alternative. Two problems are addressed: (1) insufficient data on wireless sensor modality to train an accurate skeleton estimation model, and (2) skeletal keypoints derived from wireless sensors are noisier than RGB, causing great difficulties for subsequent action recognition models. Our work, SkeFi, overcomes these gaps through a novel cross-modal knowledge transfer method acquired from the data-rich RGB modality. We propose the enhanced Temporal Correlation Adaptive Graph Convolution (TC-AGC) with frame interactive enhancement to overcome the noise from missing or inconsecutive frames. Additionally, our research underscores the effectiveness of enhancing multiscale temporal modeling through dual temporal convolution. By integrating TC-AGC with temporal modeling for cross-modal transfer, our framework can extract accurate poses and actions from noisy wireless sensors. Experiments demonstrate that SkeFi realizes state-of-the-art performances on mmWave and LiDAR. The code is available at https://github.com/Huang0035/Skefi.
Variational Contrastive Learning for Skeleton-based Action Recognition
Jan 12, 2026In recent years, self-supervised representation learning for skeleton-based action recognition has advanced with the development of contrastive learning methods. However, most of contrastive paradigms are inherently discriminative and often struggle to capture the variability and uncertainty intrinsic to human motion. To address this issue, we propose a variational contrastive learning framework that integrates probabilistic latent modeling with contrastive self-supervised learning. This formulation enables the learning of structured and semantically meaningful representations that generalize across different datasets and supervision levels. Extensive experiments on three widely used skeleton-based action recognition benchmarks show that our proposed method consistently outperforms existing approaches, particularly in low-label regimes. Moreover, qualitative analyses show that the features provided by our method are more relevant given the motion and sample characteristics, with more focus on important skeleton joints, when compared to the other methods.
Summary of the Unusual Activity Recognition Challenge for Developmental Disability Support
Jan 21, 2026This paper presents an overview of the Recognize the Unseen: Unusual Behavior Recognition from Pose Data Challenge, hosted at ISAS 2025. The challenge aims to address the critical need for automated recognition of unusual behaviors in facilities for individuals with developmental disabilities using non-invasive pose estimation data. Participating teams were tasked with distinguishing between normal and unusual activities based on skeleton keypoints extracted from video recordings of simulated scenarios. The dataset reflects real-world imbalance and temporal irregularities in behavior, and the evaluation adopted a Leave-One-Subject-Out (LOSO) strategy to ensure subject-agnostic generalization. The challenge attracted broad participation from 40 teams applying diverse approaches ranging from classical machine learning to deep learning architectures. Submissions were assessed primarily using macro-averaged F1 scores to account for class imbalance. The results highlight the difficulty of modeling rare, abrupt actions in noisy, low-dimensional data, and emphasize the importance of capturing both temporal and contextual nuances in behavior modeling. Insights from this challenge may contribute to future developments in socially responsible AI applications for healthcare and behavior monitoring.
BHaRNet: Reliability-Aware Body-Hand Modality Expertized Networks for Fine-grained Skeleton Action Recognition
Jan 01, 2026Skeleton-based human action recognition (HAR) has achieved remarkable progress with graph-based architectures. However, most existing methods remain body-centric, focusing on large-scale motions while neglecting subtle hand articulations that are crucial for fine-grained recognition. This work presents a probabilistic dual-stream framework that unifies reliability modeling and multi-modal integration, generalizing expertized learning under uncertainty across both intra-skeleton and cross-modal domains. The framework comprises three key components: (1) a calibration-free preprocessing pipeline that removes canonical-space transformations and learns directly from native coordinates; (2) a probabilistic Noisy-OR fusion that stabilizes reliability-aware dual-stream learning without requiring explicit confidence supervision; and (3) an intra- to cross-modal ensemble that couples four skeleton modalities (Joint, Bone, Joint Motion, and Bone Motion) to RGB representations, bridging structural and visual motion cues in a unified cross-modal formulation. Comprehensive evaluations across multiple benchmarks (NTU RGB+D~60/120, PKU-MMD, N-UCLA) and a newly defined hand-centric benchmark exhibit consistent improvements and robustness under noisy and heterogeneous conditions.
FineTec: Fine-Grained Action Recognition Under Temporal Corruption via Skeleton Decomposition and Sequence Completion
Dec 31, 2025Recognizing fine-grained actions from temporally corrupted skeleton sequences remains a significant challenge, particularly in real-world scenarios where online pose estimation often yields substantial missing data. Existing methods often struggle to accurately recover temporal dynamics and fine-grained spatial structures, resulting in the loss of subtle motion cues crucial for distinguishing similar actions. To address this, we propose FineTec, a unified framework for Fine-grained action recognition under Temporal Corruption. FineTec first restores a base skeleton sequence from corrupted input using context-aware completion with diverse temporal masking. Next, a skeleton-based spatial decomposition module partitions the skeleton into five semantic regions, further divides them into dynamic and static subgroups based on motion variance, and generates two augmented skeleton sequences via targeted perturbation. These, along with the base sequence, are then processed by a physics-driven estimation module, which utilizes Lagrangian dynamics to estimate joint accelerations. Finally, both the fused skeleton position sequence and the fused acceleration sequence are jointly fed into a GCN-based action recognition head. Extensive experiments on both coarse-grained (NTU-60, NTU-120) and fine-grained (Gym99, Gym288) benchmarks show that FineTec significantly outperforms previous methods under various levels of temporal corruption. Specifically, FineTec achieves top-1 accuracies of 89.1% and 78.1% on the challenging Gym99-severe and Gym288-severe settings, respectively, demonstrating its robustness and generalizability. Code and datasets could be found at https://smartdianlab.github.io/projects-FineTec/.
Skeleton-Snippet Contrastive Learning with Multiscale Feature Fusion for Action Localization
Dec 22, 2025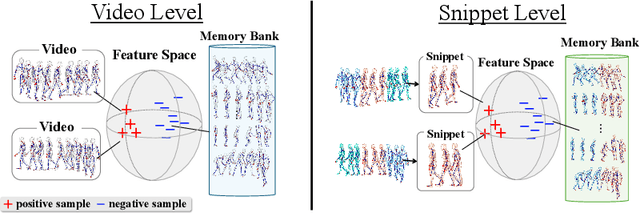
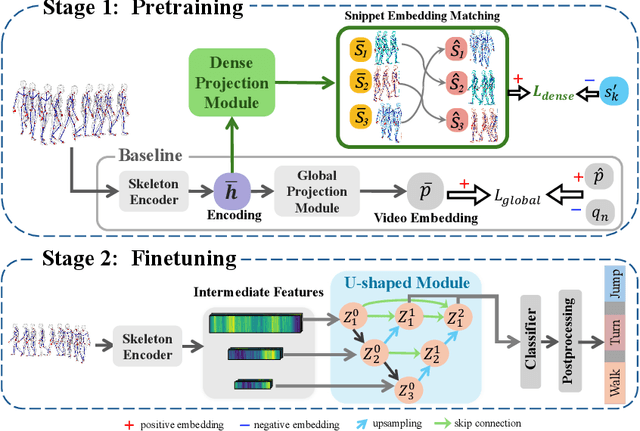
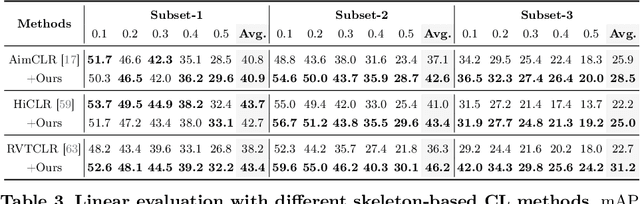
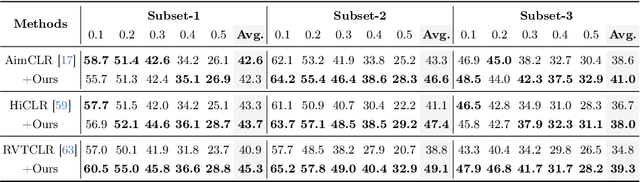
The self-supervised pretraining paradigm has achieved great success in learning 3D action representations for skeleton-based action recognition using contrastive learning. However, learning effective representations for skeleton-based temporal action localization remains challenging and underexplored. Unlike video-level {action} recognition, detecting action boundaries requires temporally sensitive features that capture subtle differences between adjacent frames where labels change. To this end, we formulate a snippet discrimination pretext task for self-supervised pretraining, which densely projects skeleton sequences into non-overlapping segments and promotes features that distinguish them across videos via contrastive learning. Additionally, we build on strong backbones of skeleton-based action recognition models by fusing intermediate features with a U-shaped module to enhance feature resolution for frame-level localization. Our approach consistently improves existing skeleton-based contrastive learning methods for action localization on BABEL across diverse subsets and evaluation protocols. We also achieve state-of-the-art transfer learning performance on PKUMMD with pretraining on NTU RGB+D and BABEL.
Signal-SGN++: Topology-Enhanced Time-Frequency Spiking Graph Network for Skeleton-Based Action Recognition
Dec 22, 2025Graph Convolutional Networks (GCNs) demonstrate strong capability in modeling skeletal topology for action recognition, yet their dense floating-point computations incur high energy costs. Spiking Neural Networks (SNNs), characterized by event-driven and sparse activation, offer energy efficiency but remain limited in capturing coupled temporal-frequency and topological dependencies of human motion. To bridge this gap, this article proposes Signal-SGN++, a topology-aware spiking graph framework that integrates structural adaptivity with time-frequency spiking dynamics. The network employs a backbone composed of 1D Spiking Graph Convolution (1D-SGC) and Frequency Spiking Convolution (FSC) for joint spatiotemporal and spectral feature extraction. Within this backbone, a Topology-Shift Self-Attention (TSSA) mechanism is embedded to adaptively route attention across learned skeletal topologies, enhancing graph-level sensitivity without increasing computational complexity. Moreover, an auxiliary Multi-Scale Wavelet Transform Fusion (MWTF) branch decomposes spiking features into multi-resolution temporal-frequency representations, wherein a Topology-Aware Time-Frequency Fusion (TATF) unit incorporates structural priors to preserve topology-consistent spectral fusion. Comprehensive experiments on large-scale benchmarks validate that Signal-SGN++ achieves superior accuracy-efficiency trade-offs, outperforming existing SNN-based methods and achieving competitive results against state-of-the-art GCNs under substantially reduced energy consumption.
TSkel-Mamba: Temporal Dynamic Modeling via State Space Model for Human Skeleton-based Action Recognition
Dec 12, 2025Skeleton-based action recognition has garnered significant attention in the computer vision community. Inspired by the recent success of the selective state-space model (SSM) Mamba in modeling 1D temporal sequences, we propose TSkel-Mamba, a hybrid Transformer-Mamba framework that effectively captures both spatial and temporal dynamics. In particular, our approach leverages Spatial Transformer for spatial feature learning while utilizing Mamba for temporal modeling. Mamba, however, employs separate SSM blocks for individual channels, which inherently limits its ability to model inter-channel dependencies. To better adapt Mamba for skeleton data and enhance Mamba`s ability to model temporal dependencies, we introduce a Temporal Dynamic Modeling (TDM) block, which is a versatile plug-and-play component that integrates a novel Multi-scale Temporal Interaction (MTI) module. The MTI module employs multi-scale Cycle operators to capture cross-channel temporal interactions, a critical factor in action recognition. Extensive experiments on NTU-RGB+D 60, NTU-RGB+D 120, NW-UCLA and UAV-Human datasets demonstrate that TSkel-Mamba achieves state-of-the-art performance while maintaining low inference time, making it both efficient and highly effective.
Patch as Node: Human-Centric Graph Representation Learning for Multimodal Action Recognition
Dec 26, 2025While human action recognition has witnessed notable achievements, multimodal methods fusing RGB and skeleton modalities still suffer from their inherent heterogeneity and fail to fully exploit the complementary potential between them. In this paper, we propose PAN, the first human-centric graph representation learning framework for multimodal action recognition, in which token embeddings of RGB patches containing human joints are represented as spatiotemporal graphs. The human-centric graph modeling paradigm suppresses the redundancy in RGB frames and aligns well with skeleton-based methods, thus enabling a more effective and semantically coherent fusion of multimodal features. Since the sampling of token embeddings heavily relies on 2D skeletal data, we further propose attention-based post calibration to reduce the dependency on high-quality skeletal data at a minimal cost interms of model performance. To explore the potential of PAN in integrating with skeleton-based methods, we present two variants: PAN-Ensemble, which employs dual-path graph convolution networks followed by late fusion, and PAN-Unified, which performs unified graph representation learning within a single network. On three widely used multimodal action recognition datasets, both PAN-Ensemble and PAN-Unified achieve state-of-the-art (SOTA) performance in their respective settings of multimodal fusion: separate and unified modeling, respectively.