 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeme Classification
Meme classification is the process of categorizing memes into different categories based on their content or style.
Papers and Code
KID: Knowledge-Injected Dual-Head Learning for Knowledge-Grounded Harmful Meme Detection
Jan 29, 2026Internet memes have become pervasive carriers of digital culture on social platforms. However, their heavy reliance on metaphors and sociocultural context also makes them subtle vehicles for harmful content, posing significant challenges for automated content moderation. Existing approaches primarily focus on intra-modal and inter-modal signal analysis, while the understanding of implicit toxicity often depends on background knowledge that is not explicitly present in the meme itself. To address this challenge, we propose KID, a Knowledge-Injected Dual-Head Learning framework for knowledge-grounded harmful meme detection. KID adopts a label-constrained distillation paradigm to decompose complex meme understanding into structured reasoning chains that explicitly link visual evidence, background knowledge, and classification labels. These chains guide the learning process by grounding external knowledge in meme-specific contexts. In addition, KID employs a dual-head architecture that jointly optimizes semantic generation and classification objectives, enabling aligned linguistic reasoning while maintaining stable decision boundaries. Extensive experiments on five multilingual datasets spanning English, Chinese, and low-resource Bengali demonstrate that KID achieves SOTA performance on both binary and multi-label harmful meme detection tasks, improving over previous best methods by 2.1%--19.7% across primary evaluation metrics. Ablation studies further confirm the effectiveness of knowledge injection and dual-head joint learning, highlighting their complementary contributions to robust and generalizable meme understanding. The code and data are available at https://github.com/PotatoDog1669/KID.
Enhancing Meme Emotion Understanding with Multi-Level Modality Enhancement and Dual-Stage Modal Fusion
Nov 14, 2025With the rapid rise of social media and Internet culture, memes have become a popular medium for expressing emotional tendencies. This has sparked growing interest in Meme Emotion Understanding (MEU), which aims to classify the emotional intent behind memes by leveraging their multimodal contents. While existing efforts have achieved promising results, two major challenges remain: (1) a lack of fine-grained multimodal fusion strategies, and (2) insufficient mining of memes' implicit meanings and background knowledge. To address these challenges, we propose MemoDetector, a novel framework for advancing MEU. First, we introduce a four-step textual enhancement module that utilizes the rich knowledge and reasoning capabilities of Multimodal Large Language Models (MLLMs) to progressively infer and extract implicit and contextual insights from memes. These enhanced texts significantly enrich the original meme contents and provide valuable guidance for downstream classification. Next, we design a dual-stage modal fusion strategy: the first stage performs shallow fusion on raw meme image and text, while the second stage deeply integrates the enhanced visual and textual features. This hierarchical fusion enables the model to better capture nuanced cross-modal emotional cues. Experiments on two datasets, MET-MEME and MOOD, demonstrate that our method consistently outperforms state-of-the-art baselines. Specifically, MemoDetector improves F1 scores by 4.3\% on MET-MEME and 3.4\% on MOOD. Further ablation studies and in-depth analyses validate the effectiveness and robustness of our approach, highlighting its strong potential for advancing MEU. Our code is available at https://github.com/singing-cat/MemoDetector.
MemeArena: Automating Context-Aware Unbiased Evaluation of Harmfulness Understanding for Multimodal Large Language Models
Oct 31, 2025The proliferation of memes on social media necessitates the capabilities of multimodal Large Language Models (mLLMs) to effectively understand multimodal harmfulness. Existing evaluation approaches predominantly focus on mLLMs' detection accuracy for binary classification tasks, which often fail to reflect the in-depth interpretive nuance of harmfulness across diverse contexts. In this paper, we propose MemeArena, an agent-based arena-style evaluation framework that provides a context-aware and unbiased assessment for mLLMs' understanding of multimodal harmfulness. Specifically, MemeArena simulates diverse interpretive contexts to formulate evaluation tasks that elicit perspective-specific analyses from mLLMs. By integrating varied viewpoints and reaching consensus among evaluators, it enables fair and unbiased comparisons of mLLMs' abilities to interpret multimodal harmfulness. Extensive experiments demonstrate that our framework effectively reduces the evaluation biases of judge agents, with judgment results closely aligning with human preferences, offering valuable insights into reliable and comprehensive mLLM evaluations in multimodal harmfulness understanding. Our code and data are publicly available at https://github.com/Lbotirx/MemeArena.
ToxicTAGS: Decoding Toxic Memes with Rich Tag Annotations
Aug 06, 2025



The 2025 Global Risks Report identifies state-based armed conflict and societal polarisation among the most pressing global threats, with social media playing a central role in amplifying toxic discourse. Memes, as a widely used mode of online communication, often serve as vehicles for spreading harmful content. However, limitations in data accessibility and the high cost of dataset curation hinder the development of robust meme moderation systems. To address this challenge, in this work, we introduce a first-of-its-kind dataset of 6,300 real-world meme-based posts annotated in two stages: (i) binary classification into toxic and normal, and (ii) fine-grained labelling of toxic memes as hateful, dangerous, or offensive. A key feature of this dataset is that it is enriched with auxiliary metadata of socially relevant tags, enhancing the context of each meme. In addition, we propose a tag generation module that produces socially grounded tags, because most in-the-wild memes often do not come with tags. Experimental results show that incorporating these tags substantially enhances the performance of state-of-the-art VLMs detection tasks. Our contributions offer a novel and scalable foundation for improved content moderation in multimodal online environments.
On VLMs for Diverse Tasks in Multimodal Meme Classification
May 27, 2025In this paper, we present a comprehensive and systematic analysis of vision-language models (VLMs) for disparate meme classification tasks. We introduced a novel approach that generates a VLM-based understanding of meme images and fine-tunes the LLMs on textual understanding of the embedded meme text for improving the performance. Our contributions are threefold: (1) Benchmarking VLMs with diverse prompting strategies purposely to each sub-task; (2) Evaluating LoRA fine-tuning across all VLM components to assess performance gains; and (3) Proposing a novel approach where detailed meme interpretations generated by VLMs are used to train smaller language models (LLMs), significantly improving classification. The strategy of combining VLMs with LLMs improved the baseline performance by 8.34%, 3.52% and 26.24% for sarcasm, offensive and sentiment classification, respectively. Our results reveal the strengths and limitations of VLMs and present a novel strategy for meme understanding.
Detecting Harmful Memes with Decoupled Understanding and Guided CoT Reasoning
Jun 10, 2025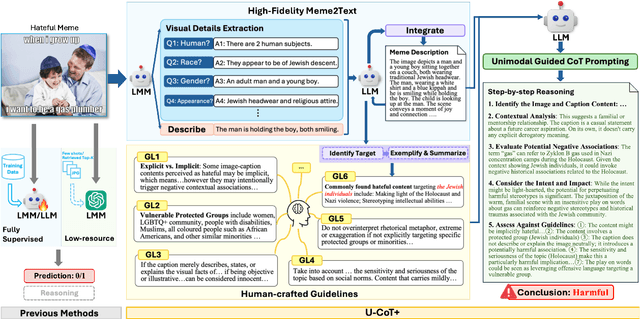
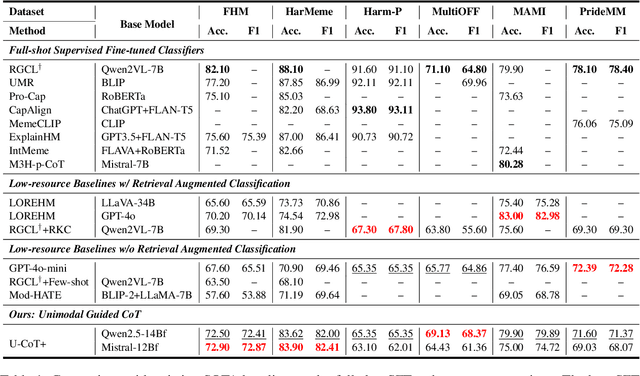
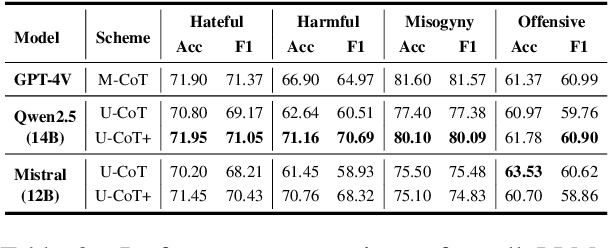
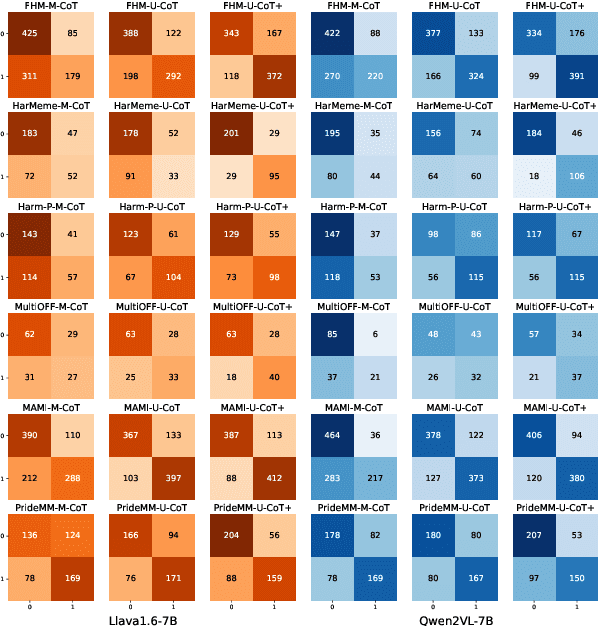
Detecting harmful memes is essential for maintaining the integrity of online environments. However, current approaches often struggle with resource efficiency, flexibility, or explainability, limiting their practical deployment in content moderation systems. To address these challenges, we introduce U-CoT+, a novel framework for harmful meme detection. Instead of relying solely on prompting or fine-tuning multimodal models, we first develop a high-fidelity meme-to-text pipeline that converts visual memes into detail-preserving textual descriptions. This design decouples meme interpretation from meme classification, thus avoiding immediate reasoning over complex raw visual content and enabling resource-efficient harmful meme detection with general large language models (LLMs). Building on these textual descriptions, we further incorporate targeted, interpretable human-crafted guidelines to guide models' reasoning under zero-shot CoT prompting. As such, this framework allows for easy adaptation to different harmfulness detection criteria across platforms, regions, and over time, offering high flexibility and explainability. Extensive experiments on seven benchmark datasets validate the effectiveness of our framework, highlighting its potential for explainable and low-resource harmful meme detection using small-scale LLMs. Codes and data are available at: https://anonymous.4open.science/r/HMC-AF2B/README.md.
LLM-based Semantic Augmentation for Harmful Content Detection
Apr 22, 2025Recent advances in large language models (LLMs) have demonstrated strong performance on simple text classification tasks, frequently under zero-shot settings. However, their efficacy declines when tackling complex social media challenges such as propaganda detection, hateful meme classification, and toxicity identification. Much of the existing work has focused on using LLMs to generate synthetic training data, overlooking the potential of LLM-based text preprocessing and semantic augmentation. In this paper, we introduce an approach that prompts LLMs to clean noisy text and provide context-rich explanations, thereby enhancing training sets without substantial increases in data volume. We systematically evaluate on the SemEval 2024 multi-label Persuasive Meme dataset and further validate on the Google Jigsaw toxic comments and Facebook hateful memes datasets to assess generalizability. Our results reveal that zero-shot LLM classification underperforms on these high-context tasks compared to supervised models. In contrast, integrating LLM-based semantic augmentation yields performance on par with approaches that rely on human-annotated data, at a fraction of the cost. These findings underscore the importance of strategically incorporating LLMs into machine learning (ML) pipeline for social media classification tasks, offering broad implications for combating harmful content online.
Improving Multimodal Hateful Meme Detection Exploiting LMM-Generated Knowledge
Apr 14, 2025Memes have become a dominant form of communication in social media in recent years. Memes are typically humorous and harmless, however there are also memes that promote hate speech, being in this way harmful to individuals and groups based on their identity. Therefore, detecting hateful content in memes has emerged as a task of critical importance. The need for understanding the complex interactions of images and their embedded text renders the hateful meme detection a challenging multimodal task. In this paper we propose to address the aforementioned task leveraging knowledge encoded in powerful Large Multimodal Models (LMM). Specifically, we propose to exploit LMMs in a two-fold manner. First, by extracting knowledge oriented to the hateful meme detection task in order to build strong meme representations. Specifically, generic semantic descriptions and emotions that the images along with their embedded texts elicit are extracted, which are then used to train a simple classification head for hateful meme detection. Second, by developing a novel hard mining approach introducing directly LMM-encoded knowledge to the training process, providing further improvements. We perform extensive experiments on two datasets that validate the effectiveness of the proposed method, achieving state-of-the-art performance. Our code and trained models are publicly available at: https://github.com/IDT-ITI/LMM-CLIP-meme.
MemeBLIP2: A novel lightweight multimodal system to detect harmful memes
Apr 29, 2025Memes often merge visuals with brief text to share humor or opinions, yet some memes contain harmful messages such as hate speech. In this paper, we introduces MemeBLIP2, a light weight multimodal system that detects harmful memes by combining image and text features effectively. We build on previous studies by adding modules that align image and text representations into a shared space and fuse them for better classification. Using BLIP-2 as the core vision-language model, our system is evaluated on the PrideMM datasets. The results show that MemeBLIP2 can capture subtle cues in both modalities, even in cases with ironic or culturally specific content, thereby improving the detection of harmful material.
Detecting and Understanding Hateful Contents in Memes Through Captioning and Visual Question-Answering
Apr 23, 2025Memes are widely used for humor and cultural commentary, but they are increasingly exploited to spread hateful content. Due to their multimodal nature, hateful memes often evade traditional text-only or image-only detection systems, particularly when they employ subtle or coded references. To address these challenges, we propose a multimodal hate detection framework that integrates key components: OCR to extract embedded text, captioning to describe visual content neutrally, sub-label classification for granular categorization of hateful content, RAG for contextually relevant retrieval, and VQA for iterative analysis of symbolic and contextual cues. This enables the framework to uncover latent signals that simpler pipelines fail to detect. Experimental results on the Facebook Hateful Memes dataset reveal that the proposed framework exceeds the performance of unimodal and conventional multimodal models in both accuracy and AUC-ROC.