 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLip Reading
Papers and Code
VALLR-Pin: Dual-Decoding Visual Speech Recognition for Mandarin with Pinyin-Guided LLM Refinement
Dec 23, 2025Visual Speech Recognition aims to transcribe spoken words from silent lip-motion videos. This task is particularly challenging for Mandarin, as visemes are highly ambiguous and homophones are prevalent. We propose VALLR-Pin, a novel two-stage framework that extends the recent VALLR architecture from English to Mandarin. First, a shared video encoder feeds into dual decoders, which jointly predict both Chinese character sequences and their standard Pinyin romanization. The multi-task learning of character and phonetic outputs fosters robust visual-semantic representations. During inference, the text decoder generates multiple candidate transcripts. We construct a prompt by concatenating the Pinyin output with these candidate Chinese sequences and feed it to a large language model to resolve ambiguities and refine the transcription. This provides the LLM with explicit phonetic context to correct homophone-induced errors. Finally, we fine-tune the LLM on synthetic noisy examples: we generate imperfect Pinyin-text pairs from intermediate VALLR-Pin checkpoints using the training data, creating instruction-response pairs for error correction. This endows the LLM with awareness of our model's specific error patterns. In summary, VALLR-Pin synergizes visual features with phonetic and linguistic context to improve Mandarin lip-reading performance.
STARCaster: Spatio-Temporal AutoRegressive Video Diffusion for Identity- and View-Aware Talking Portraits
Dec 15, 2025


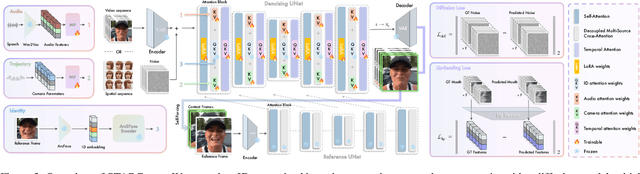
This paper presents STARCaster, an identity-aware spatio-temporal video diffusion model that addresses both speech-driven portrait animation and free-viewpoint talking portrait synthesis, given an identity embedding or reference image, within a unified framework. Existing 2D speech-to-video diffusion models depend heavily on reference guidance, leading to limited motion diversity. At the same time, 3D-aware animation typically relies on inversion through pre-trained tri-plane generators, which often leads to imperfect reconstructions and identity drift. We rethink reference- and geometry-based paradigms in two ways. First, we deviate from strict reference conditioning at pre-training by introducing softer identity constraints. Second, we address 3D awareness implicitly within the 2D video domain by leveraging the inherent multi-view nature of video data. STARCaster adopts a compositional approach progressing from ID-aware motion modeling, to audio-visual synchronization via lip reading-based supervision, and finally to novel view animation through temporal-to-spatial adaptation. To overcome the scarcity of 4D audio-visual data, we propose a decoupled learning approach in which view consistency and temporal coherence are trained independently. A self-forcing training scheme enables the model to learn from longer temporal contexts than those generated at inference, mitigating the overly static animations common in existing autoregressive approaches. Comprehensive evaluations demonstrate that STARCaster generalizes effectively across tasks and identities, consistently surpassing prior approaches in different benchmarks.
LRW-Persian: Lip-reading in the Wild Dataset for Persian Language
Oct 26, 2025Lipreading has emerged as an increasingly important research area for developing robust speech recognition systems and assistive technologies for the hearing-impaired. However, non-English resources for visual speech recognition remain limited. We introduce LRW-Persian, the largest in-the-wild Persian word-level lipreading dataset, comprising $743$ target words and over $414{,}000$ video samples extracted from more than $1{,}900$ hours of footage across $67$ television programs. Designed as a benchmark-ready resource, LRW-Persian provides speaker-disjoint training and test splits, wide regional and dialectal coverage, and rich per-clip metadata including head pose, age, and gender. To ensure large-scale data quality, we establish a fully automated end-to-end curation pipeline encompassing transcription based on Automatic Speech Recognition(ASR), active-speaker localization, quality filtering, and pose/mask screening. We further fine-tune two widely used lipreading architectures on LRW-Persian, establishing reference performance and demonstrating the difficulty of Persian visual speech recognition. By filling a critical gap in low-resource languages, LRW-Persian enables rigorous benchmarking, supports cross-lingual transfer, and provides a foundation for advancing multimodal speech research in underrepresented linguistic contexts. The dataset is publicly available at: https://lrw-persian.vercel.app.
GLip: A Global-Local Integrated Progressive Framework for Robust Visual Speech Recognition
Sep 19, 2025Visual speech recognition (VSR), also known as lip reading, is the task of recognizing speech from silent video. Despite significant advancements in VSR over recent decades, most existing methods pay limited attention to real-world visual challenges such as illumination variations, occlusions, blurring, and pose changes. To address these challenges, we propose GLip, a Global-Local Integrated Progressive framework designed for robust VSR. GLip is built upon two key insights: (i) learning an initial \textit{coarse} alignment between visual features across varying conditions and corresponding speech content facilitates the subsequent learning of \textit{precise} visual-to-speech mappings in challenging environments; (ii) under adverse conditions, certain local regions (e.g., non-occluded areas) often exhibit more discriminative cues for lip reading than global features. To this end, GLip introduces a dual-path feature extraction architecture that integrates both global and local features within a two-stage progressive learning framework. In the first stage, the model learns to align both global and local visual features with corresponding acoustic speech units using easily accessible audio-visual data, establishing a coarse yet semantically robust foundation. In the second stage, we introduce a Contextual Enhancement Module (CEM) to dynamically integrate local features with relevant global context across both spatial and temporal dimensions, refining the coarse representations into precise visual-speech mappings. Our framework uniquely exploits discriminative local regions through a progressive learning strategy, demonstrating enhanced robustness against various visual challenges and consistently outperforming existing methods on the LRS2 and LRS3 benchmarks. We further validate its effectiveness on a newly introduced challenging Mandarin dataset.
VisualSpeaker: Visually-Guided 3D Avatar Lip Synthesis
Jul 08, 2025



Realistic, high-fidelity 3D facial animations are crucial for expressive avatar systems in human-computer interaction and accessibility. Although prior methods show promising quality, their reliance on the mesh domain limits their ability to fully leverage the rapid visual innovations seen in 2D computer vision and graphics. We propose VisualSpeaker, a novel method that bridges this gap using photorealistic differentiable rendering, supervised by visual speech recognition, for improved 3D facial animation. Our contribution is a perceptual lip-reading loss, derived by passing photorealistic 3D Gaussian Splatting avatar renders through a pre-trained Visual Automatic Speech Recognition model during training. Evaluation on the MEAD dataset demonstrates that VisualSpeaker improves both the standard Lip Vertex Error metric by 56.1% and the perceptual quality of the generated animations, while retaining the controllability of mesh-driven animation. This perceptual focus naturally supports accurate mouthings, essential cues that disambiguate similar manual signs in sign language avatars.
SwinLip: An Efficient Visual Speech Encoder for Lip Reading Using Swin Transformer
May 07, 2025This paper presents an efficient visual speech encoder for lip reading. While most recent lip reading studies have been based on the ResNet architecture and have achieved significant success, they are not sufficiently suitable for efficiently capturing lip reading features due to high computational complexity in modeling spatio-temporal information. Additionally, using a complex visual model not only increases the complexity of lip reading models but also induces delays in the overall network for multi-modal studies (e.g., audio-visual speech recognition, speech enhancement, and speech separation). To overcome the limitations of Convolutional Neural Network (CNN)-based models, we apply the hierarchical structure and window self-attention of the Swin Transformer to lip reading. We configure a new lightweight scale of the Swin Transformer suitable for processing lip reading data and present the SwinLip visual speech encoder, which efficiently reduces computational load by integrating modified Convolution-augmented Transformer (Conformer) temporal embeddings with conventional spatial embeddings in the hierarchical structure. Through extensive experiments, we have validated that our SwinLip successfully improves the performance and inference speed of the lip reading network when applied to various backbones for word and sentence recognition, reducing computational load. In particular, our SwinLip demonstrated robust performance in both English LRW and Mandarin LRW-1000 datasets and achieved state-of-the-art performance on the Mandarin LRW-1000 dataset with less computation compared to the existing state-of-the-art model.
Chinese-LiPS: A Chinese audio-visual speech recognition dataset with Lip-reading and Presentation Slides
Apr 21, 2025Incorporating visual modalities to assist Automatic Speech Recognition (ASR) tasks has led to significant improvements. However, existing Audio-Visual Speech Recognition (AVSR) datasets and methods typically rely solely on lip-reading information or speaking contextual video, neglecting the potential of combining these different valuable visual cues within the speaking context. In this paper, we release a multimodal Chinese AVSR dataset, Chinese-LiPS, comprising 100 hours of speech, video, and corresponding manual transcription, with the visual modality encompassing both lip-reading information and the presentation slides used by the speaker. Based on Chinese-LiPS, we develop a simple yet effective pipeline, LiPS-AVSR, which leverages both lip-reading and presentation slide information as visual modalities for AVSR tasks. Experiments show that lip-reading and presentation slide information improve ASR performance by approximately 8\% and 25\%, respectively, with a combined performance improvement of about 35\%. The dataset is available at https://kiri0824.github.io/Chinese-LiPS/
Transforming faces into video stories -- VideoFace2.0
May 04, 2025

Face detection and face recognition have been in the focus of vision community since the very beginnings. Inspired by the success of the original Videoface digitizer, a pioneering device that allowed users to capture video signals from any source, we have designed an advanced video analytics tool to efficiently create structured video stories, i.e. identity-based information catalogs. VideoFace2.0 is the name of the developed system for spatial and temporal localization of each unique face in the input video, i.e. face re-identification (ReID), which also allows their cataloging, characterization and creation of structured video outputs for later downstream tasks. Developed near real-time solution is primarily designed to be utilized in application scenarios involving TV production, media analysis, and as an efficient tool for creating large video datasets necessary for training machine learning (ML) models in challenging vision tasks such as lip reading and multimodal speech recognition. Conducted experiments confirm applicability of the proposed face ReID algorithm that is combining the concepts of face detection, face recognition and passive tracking-by-detection in order to achieve robust and efficient face ReID. The system is envisioned as a compact and modular extensions of the existing video production equipment. We hope that the presented work and shared code will stimulate further interest in development of similar, application specific video analysis tools, and lower the entry barrier for production of high-quality multi-modal ML datasets in the future.
VALLR: Visual ASR Language Model for Lip Reading
Mar 27, 2025Lip Reading, or Visual Automatic Speech Recognition (V-ASR), is a complex task requiring the interpretation of spoken language exclusively from visual cues, primarily lip movements and facial expressions. This task is especially challenging due to the absence of auditory information and the inherent ambiguity when visually distinguishing phonemes that have overlapping visemes where different phonemes appear identical on the lips. Current methods typically attempt to predict words or characters directly from these visual cues, but this approach frequently encounters high error rates due to coarticulation effects and viseme ambiguity. We propose a novel two-stage, phoneme-centric framework for Visual Automatic Speech Recognition (V-ASR) that addresses these longstanding challenges. First, our model predicts a compact sequence of phonemes from visual inputs using a Video Transformer with a CTC head, thereby reducing the task complexity and achieving robust speaker invariance. This phoneme output then serves as the input to a fine-tuned Large Language Model (LLM), which reconstructs coherent words and sentences by leveraging broader linguistic context. Unlike existing methods that either predict words directly-often faltering on visually similar phonemes-or rely on large-scale multimodal pre-training, our approach explicitly encodes intermediate linguistic structure while remaining highly data efficient. We demonstrate state-of-the-art performance on two challenging datasets, LRS2 and LRS3, where our method achieves significant reductions in Word Error Rate (WER) achieving a SOTA WER of 18.7 on LRS3 despite using 99.4% less labelled data than the next best approach.
GLaM-Sign: Greek Language Multimodal Lip Reading with Integrated Sign Language Accessibility
Jan 09, 2025The Greek Language Multimodal Lip Reading with Integrated Sign Language Accessibility (GLaM-Sign) [1] is a groundbreaking resource in accessibility and multimodal AI, designed to support Deaf and Hard-of-Hearing (DHH) individuals. Developed from the FEELIT project [2], it integrates high-resolution audio, video, textual transcriptions, and Greek Sign Language translations for applications like real-time sign language translation and enhanced subtitle synchronization. While its primary focus is on promoting inclusivity in the Greek tourism sector, its adaptability extends to education, healthcare, and public services. Future advancements will enhance word-level precision and scalability to additional languages, supported by advanced AI methodologies and collaborations with diverse stakeholders. This dataset underscores the transformative potential of multimodal resources in bridging communication gaps, fostering innovation, and setting a benchmark for ethical AI and inclusive technologies.