 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm
Dec 30, 2025The transition from static Large Language Models (LLMs) to self-improving agents is hindered by the lack of structured reasoning in traditional evolutionary approaches. Existing methods often struggle with premature convergence and inefficient exploration in high-dimensional code spaces. To address these challenges, we introduce LoongFlow, a self-evolving agent framework that achieves state-of-the-art solution quality with significantly reduced computational costs. Unlike "blind" mutation operators, LoongFlow integrates LLMs into a cognitive "Plan-Execute-Summarize" (PES) paradigm, effectively mapping the evolutionary search to a reasoning-heavy process. To sustain long-term architectural coherence, we incorporate a hybrid evolutionary memory system. By synergizing Multi-Island models with MAP-Elites and adaptive Boltzmann selection, this system theoretically balances the exploration-exploitation trade-off, maintaining diverse behavioral niches to prevent optimization stagnation. We instantiate LoongFlow with a General Agent for algorithmic discovery and an ML Agent for pipeline optimization. Extensive evaluations on the AlphaEvolve benchmark and Kaggle competitions demonstrate that LoongFlow outperforms leading baselines (e.g., OpenEvolve, ShinkaEvolve) by up to 60% in evolutionary efficiency while discovering superior solutions. LoongFlow marks a substantial step forward in autonomous scientific discovery, enabling the generation of expert-level solutions with reduced computational overhead.
Staggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference
Dec 18, 2025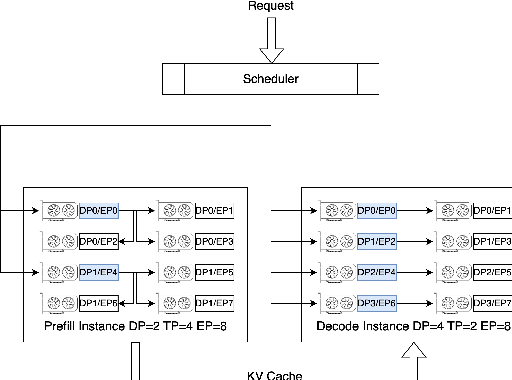
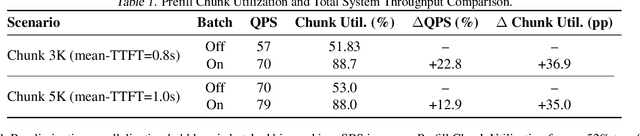
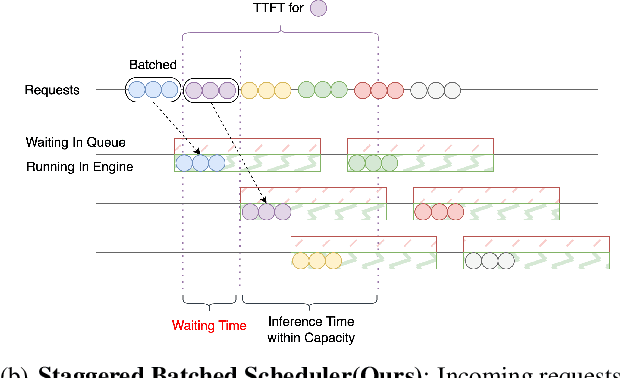
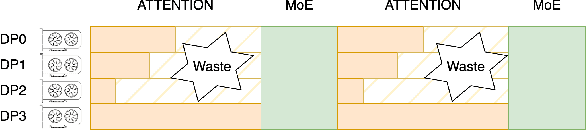
The evolution of Large Language Model (LLM) serving towards complex, distributed architectures--specifically the P/D-separated, large-scale DP+EP paradigm--introduces distinct scheduling challenges. Unlike traditional deployments where schedulers can treat instances as black boxes, DP+EP architectures exhibit high internal synchronization costs. We identify that immediate request dispatching in such systems leads to severe in-engine queuing and parallelization bubbles, degrading Time-to-First-Token (TTFT). To address this, we propose Staggered Batch Scheduling (SBS), a mechanism that deliberately buffers requests to form optimal execution batches. This temporal decoupling eliminates internal queuing bubbles without compromising throughput. Furthermore, leveraging the scheduling window created by buffering, we introduce a Load-Aware Global Allocation strategy that balances computational load across DP units for both Prefill and Decode phases. Deployed on a production H800 cluster serving Deepseek-V3, our system reduces TTFT by 30%-40% and improves throughput by 15%-20% compared to state-of-the-art immediate scheduling baselines.
FEVO: Financial Knowledge Expansion and Reasoning Evolution for Large Language Models
Jul 09, 2025Advancements in reasoning for large language models (LLMs) have lead to significant performance improvements for LLMs in various fields such as mathematics and programming. However, research applying these advances to the financial domain, where considerable domain-specific knowledge is necessary to complete tasks, remains limited. To address this gap, we introduce FEVO (Financial Evolution), a multi-stage enhancement framework developed to enhance LLM performance in the financial domain. FEVO systemically enhances LLM performance by using continued pre-training (CPT) to expand financial domain knowledge, supervised fine-tuning (SFT) to instill structured, elaborate reasoning patterns, and reinforcement learning (RL) to further integrate the expanded financial domain knowledge with the learned structured reasoning. To ensure effective and efficient training, we leverage frontier reasoning models and rule-based filtering to curate FEVO-Train, high-quality datasets specifically designed for the different post-training phases. Using our framework, we train the FEVO series of models - C32B, S32B, R32B - from Qwen2.5-32B and evaluate them on seven benchmarks to assess financial and general capabilities, with results showing that FEVO-R32B achieves state-of-the-art performance on five financial benchmarks against much larger models as well as specialist models. More significantly, FEVO-R32B demonstrates markedly better performance than FEVO-R32B-0 (trained from Qwen2.5-32B-Instruct using only RL), thus validating the effectiveness of financial domain knowledge expansion and structured, logical reasoning distillation
Astra: Efficient and Money-saving Automatic Parallel Strategies Search on Heterogeneous GPUs
Feb 19, 2025In this paper, we introduce an efficient and money-saving automatic parallel strategies search framework on heterogeneous GPUs: Astra. First, Astra searches for the efficiency-optimal parallel strategy in both GPU configurations search space (GPU types and GPU numbers) and parallel parameters search space. Then, Astra also provides the solution on heterogeneous GPUs by mathematically modeling the time consumption of heterogeneous training. At last, Astra is the first to propose the automatic parallel strategy search on money-saving. The experiment results demonstrate that Astra can achieve better throughput than expert-designed strategies. The search time cost for Astra can also be limited to 1.27 seconds in a single-GPU setting and less than 1.35 minutes in a heterogeneous-GPU setting on average with an accuracy of over 95%.