 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Evaluation: Co-Evolutionary Mechanisms for LLM-Driven Strategy Evolution in Adversarial Games
Jun 09, 2026Recent advances in LLM-driven code evolution have enabled automated discovery by iteratively generating and improving programs. However, applying these methods to adversarial multi-agent games introduces a fundamental challenge: the evaluation landscape shifts as strategies improve, causing fixed evaluators to become unreliable and evolution to stagnate. We propose three mechanisms to address this challenge: evaluator co-evolution, which incorporates discovered champions into the opponent pool; hierarchical deep evaluation, which replaces noisy few-game scores with statistically reliable assessments; and weakness pressure, which dynamically up-weights the most difficult opponents to break through plateaus. We implement these mechanisms within FAMOU, a framework built upon the same foundation-model code-evolution paradigm as OpenEvolve and ShinkaEvolve. On the MCTF 2026 3v3 maritime capture-the-flag task, FAMOU consistently outperforms both baselines under two backbone LLMs, achieving the highest combined score (0.526) and the best generalization to unseen opponents (61.7% win rate), while ablations confirm that each mechanism contributes to performance. Notably, the LLM mutation process generates tactical structures entirely absent from the seed strategies -- including lookahead search and adaptive interception -- demonstrating that code-level evolution can produce nontrivial algorithmic innovations in adversarial settings. The FAMOU-evolved strategy further achieved 1st place in the hardware round-robin and 3rd in simulation at the AAMAS 2026 MCTF Competition, validating its real-world transferability. The optimized implementation and corresponding evaluation codes developed through our evolutionary process are available at: https://github.com/1xiangliu1/FAMOU-CoEvo
Rollout Pass-Rate Control: Steering Binary-Reward RL Toward Its Most Informative Regime
May 06, 2026SWE-bench-style agentic reinforcement learning relies on expensive stateful trajectories, yet substantial compute is wasted on sampled rollout groups with skewed pass rates, where binary rewards provide a weak contrastive signal. We frame this inefficiency as a pass-rate control problem and show that a 50% pass rate is the most informative operating point: it maximizes reward entropy, the probability of surviving group filtering, RLOO advantage energy under GRPO, and success--failure contrastive structure. Guided by this principle, we propose Prefix Sampling (PS), which replays trajectory prefixes to steer skewed groups toward this regime: successful prefixes serve as head starts for mostly failing groups, while failing prefixes serve as handicaps for mostly passing groups. In stateful agent environments, prefix states are reconstructed through replay while replayed tokens are excluded from the loss, restricting optimization to continuations generated by the current policy. On SWE-bench-style agentic RL, PS delivers end-to-end wall-clock speedups of 2.01x on Qwen3-14B and 1.55x on Qwen3-32B while preserving or improving final verified performance. For 14B, the SWE-bench Verified peak rises from the baseline peak of 0.273 to 0.295 under PS. Additional mathematical reasoning experiments on AIME 2025 show the same pass-rate control pattern and decompose the gains into replay, bidirectional coverage, and adaptive control.
Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
Mar 11, 2026We present Qianfan-OCR, a 4B-parameter end-to-end vision-language model that unifies document parsing, layout analysis, and document understanding within a single architecture. It performs direct image-to-Markdown conversion and supports diverse prompt-driven tasks including table extraction, chart understanding, document QA, and key information extraction. To address the loss of explicit layout analysis in end-to-end OCR, we propose Layout-as-Thought, an optional thinking phase triggered by special think tokens that generates structured layout representations -- bounding boxes, element types, and reading order -- before producing final outputs, recovering layout grounding capabilities while improving accuracy on complex layouts. Qianfan-OCR ranks first among end-to-end models on OmniDocBench v1.5 (93.12) and OlmOCR Bench (79.8), achieves competitive results on OCRBench, CCOCR, DocVQA, and ChartQA against general VLMs of comparable scale, and attains the highest average score on public key information extraction benchmarks, surpassing Gemini-3.1-Pro, Seed-2.0, and Qwen3-VL-235B. The model is publicly accessible via the Baidu AI Cloud Qianfan platform.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
Staggered Batch Scheduling: Co-optimizing Time-to-First-Token and Throughput for High-Efficiency LLM Inference
Dec 18, 2025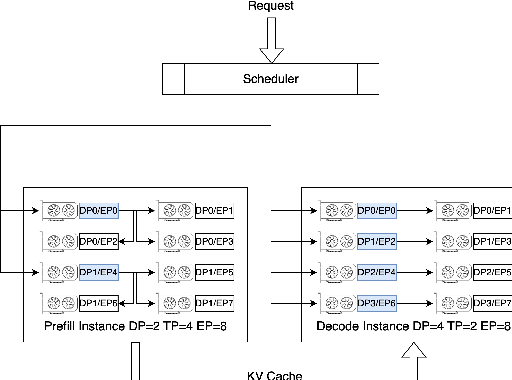
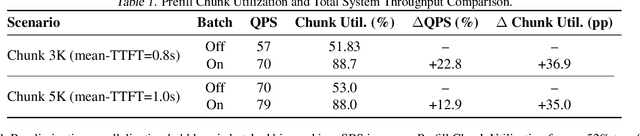
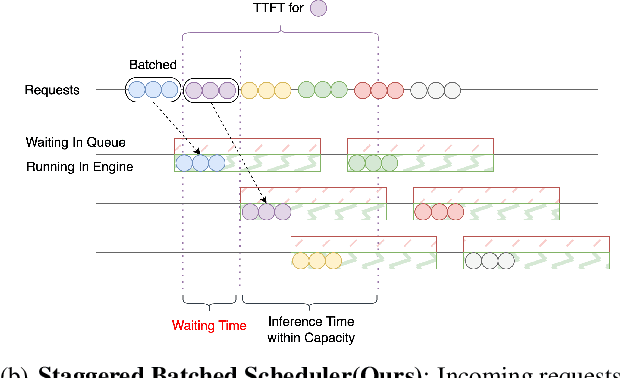
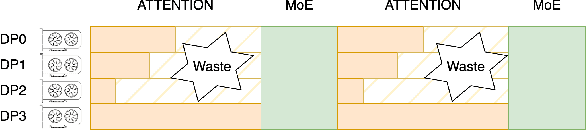
The evolution of Large Language Model (LLM) serving towards complex, distributed architectures--specifically the P/D-separated, large-scale DP+EP paradigm--introduces distinct scheduling challenges. Unlike traditional deployments where schedulers can treat instances as black boxes, DP+EP architectures exhibit high internal synchronization costs. We identify that immediate request dispatching in such systems leads to severe in-engine queuing and parallelization bubbles, degrading Time-to-First-Token (TTFT). To address this, we propose Staggered Batch Scheduling (SBS), a mechanism that deliberately buffers requests to form optimal execution batches. This temporal decoupling eliminates internal queuing bubbles without compromising throughput. Furthermore, leveraging the scheduling window created by buffering, we introduce a Load-Aware Global Allocation strategy that balances computational load across DP units for both Prefill and Decode phases. Deployed on a production H800 cluster serving Deepseek-V3, our system reduces TTFT by 30%-40% and improves throughput by 15%-20% compared to state-of-the-art immediate scheduling baselines.
The FM Agent
Oct 30, 2025Large language models (LLMs) are catalyzing the development of autonomous AI research agents for scientific and engineering discovery. We present FM Agent, a novel and general-purpose multi-agent framework that leverages a synergistic combination of LLM-based reasoning and large-scale evolutionary search to address complex real-world challenges. The core of FM Agent integrates several key innovations: 1) a cold-start initialization phase incorporating expert guidance, 2) a novel evolutionary sampling strategy for iterative optimization, 3) domain-specific evaluators that combine correctness, effectiveness, and LLM-supervised feedback, and 4) a distributed, asynchronous execution infrastructure built on Ray. Demonstrating broad applicability, our system has been evaluated across diverse domains, including operations research, machine learning, GPU kernel optimization, and classical mathematical problems. FM Agent reaches state-of-the-art results autonomously, without human interpretation or tuning -- 1976.3 on ALE-Bench (+5.2\%), 43.56\% on MLE-Bench (+4.0pp), up to 20x speedups on KernelBench, and establishes new state-of-the-art(SOTA) results on several classical mathematical problems. Beyond academic benchmarks, FM Agent shows considerable promise for both large-scale enterprise R\&D workflows and fundamental scientific research, where it can accelerate innovation, automate complex discovery processes, and deliver substantial engineering and scientific advances with broader societal impact.
Astra: Efficient and Money-saving Automatic Parallel Strategies Search on Heterogeneous GPUs
Feb 19, 2025In this paper, we introduce an efficient and money-saving automatic parallel strategies search framework on heterogeneous GPUs: Astra. First, Astra searches for the efficiency-optimal parallel strategy in both GPU configurations search space (GPU types and GPU numbers) and parallel parameters search space. Then, Astra also provides the solution on heterogeneous GPUs by mathematically modeling the time consumption of heterogeneous training. At last, Astra is the first to propose the automatic parallel strategy search on money-saving. The experiment results demonstrate that Astra can achieve better throughput than expert-designed strategies. The search time cost for Astra can also be limited to 1.27 seconds in a single-GPU setting and less than 1.35 minutes in a heterogeneous-GPU setting on average with an accuracy of over 95%.
Tree-of-Code: A Tree-Structured Exploring Framework for End-to-End Code Generation and Execution in Complex Task Handling
Dec 19, 2024Solving complex reasoning tasks is a key real-world application of agents. Thanks to the pretraining of Large Language Models (LLMs) on code data, recent approaches like CodeAct successfully use code as LLM agents' action, achieving good results. However, CodeAct greedily generates the next action's code block by relying on fragmented thoughts, resulting in inconsistency and instability. Moreover, CodeAct lacks action-related ground-truth (GT), making its supervision signals and termination conditions questionable in multi-turn interactions. To address these issues, we first introduce a simple yet effective end-to-end code generation paradigm, CodeProgram, which leverages code's systematic logic to align with global reasoning and enable cohesive problem-solving. Then, we propose Tree-of-Code (ToC), which self-grows CodeProgram nodes based on the executable nature of the code and enables self-supervision in a GT-free scenario. Experimental results on two datasets using ten popular zero-shot LLMs show ToC remarkably boosts accuracy by nearly 20% over CodeAct with less than 1/4 turns. Several LLMs even perform better on one-turn CodeProgram than on multi-turn CodeAct. To further investigate the trade-off between efficacy and efficiency, we test different ToC tree sizes and exploration mechanisms. We also highlight the potential of ToC's end-to-end data generation for supervised and reinforced fine-tuning.