 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Distributed Nonparametric Estimation: from Sparse to Dense Samples per Terminal
Jan 14, 2025
Consider the communication-constrained problem of nonparametric function estimation, in which each distributed terminal holds multiple i.i.d. samples. Under certain regularity assumptions, we characterize the minimax optimal rates for all regimes, and identify phase transitions of the optimal rates as the samples per terminal vary from sparse to dense. This fully solves the problem left open by previous works, whose scopes are limited to regimes with either dense samples or a single sample per terminal. To achieve the optimal rates, we design a layered estimation protocol by exploiting protocols for the parametric density estimation problem. We show the optimality of the protocol using information-theoretic methods and strong data processing inequalities, and incorporating the classic balls and bins model. The optimal rates are immediate for various special cases such as density estimation, Gaussian, binary, Poisson and heteroskedastic regression models.
Adaptive Refinement Protocols for Distributed Distribution Estimation under $\ell^p$-Losses
Oct 09, 2024

Consider the communication-constrained estimation of discrete distributions under $\ell^p$ losses, where each distributed terminal holds multiple independent samples and uses limited number of bits to describe the samples. We obtain the minimax optimal rates of the problem in most parameter regimes. An elbow effect of the optimal rates at $p=2$ is clearly identified. To show the optimal rates, we first design estimation protocols to achieve them. The key ingredient of these protocols is to introduce adaptive refinement mechanisms, which first generate rough estimate by partial information and then establish refined estimate in subsequent steps guided by the rough estimate. The protocols leverage successive refinement, sample compression and thresholding methods to achieve the optimal rates in different parameter regimes. The optimality of the protocols is shown by deriving compatible minimax lower bounds.
VMambaMorph: a Multi-Modality Deformable Image Registration Framework based on Visual State Space Model with Cross-Scan Module
Apr 14, 2024


Image registration, a critical process in medical imaging, involves aligning different sets of medical imaging data into a single unified coordinate system. Deep learning networks, such as the Convolutional Neural Network (CNN)-based VoxelMorph, Vision Transformer (ViT)-based TransMorph, and State Space Model (SSM)-based MambaMorph, have demonstrated effective performance in this domain. The recent Visual State Space Model (VMamba), which incorporates a cross-scan module with SSM, has exhibited promising improvements in modeling global-range dependencies with efficient computational cost in computer vision tasks. This paper hereby introduces an exploration of VMamba with image registration, named VMambaMorph. This novel hybrid VMamba-CNN network is designed specifically for 3D image registration. Utilizing a U-shaped network architecture, VMambaMorph computes the deformation field based on target and source volumes. The VMamba-based block with 2D cross-scan module is redesigned for 3D volumetric feature processing. To overcome the complex motion and structure on multi-modality images, we further propose a fine-tune recursive registration framework. We validate VMambaMorph using a public benchmark brain MR-CT registration dataset, comparing its performance against current state-of-the-art methods. The results indicate that VMambaMorph achieves competitive registration quality. The code for VMambaMorph with all baseline methods is available on GitHub.
MambaMorph: a Mamba-based Backbone with Contrastive Feature Learning for Deformable MR-CT Registration
Jan 25, 2024

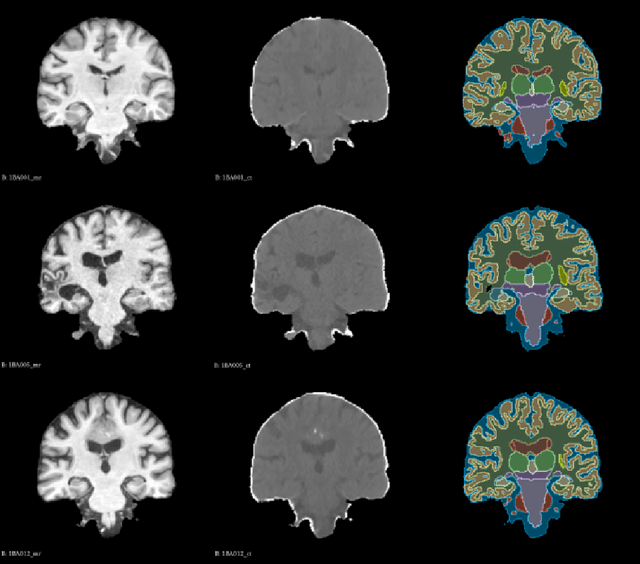

Deformable image registration is an essential approach for medical image analysis.This paper introduces MambaMorph, an innovative multi-modality deformable registration network, specifically designed for Magnetic Resonance (MR) and Computed Tomography (CT) image alignment. MambaMorph stands out with its Mamba-based registration module and a contrastive feature learning approach, addressing the prevalent challenges in multi-modality registration. The network leverages Mamba blocks for efficient long-range modeling and high-dimensional data processing, coupled with a feature extractor that learns fine-grained features for enhanced registration accuracy. Experimental results showcase MambaMorph's superior performance over existing methods in MR-CT registration, underlining its potential in clinical applications. This work underscores the significance of feature learning in multi-modality registration and positions MambaMorph as a trailblazing solution in this field. The code for MambaMorph is available at: https://github.com/Guo-Stone/MambaMorph.
1DFormer: Learning 1D Landmark Representations via Transformer for Facial Landmark Tracking
Nov 01, 2023Recently, heatmap regression methods based on 1D landmark representations have shown prominent performance on locating facial landmarks. However, previous methods ignored to make deep explorations on the good potentials of 1D landmark representations for sequential and structural modeling of multiple landmarks to track facial landmarks. To address this limitation, we propose a Transformer architecture, namely 1DFormer, which learns informative 1D landmark representations by capturing the dynamic and the geometric patterns of landmarks via token communications in both temporal and spatial dimensions for facial landmark tracking. For temporal modeling, we propose a recurrent token mixing mechanism, an axis-landmark-positional embedding mechanism, as well as a confidence-enhanced multi-head attention mechanism to adaptively and robustly embed long-term landmark dynamics into their 1D representations; for structure modeling, we design intra-group and inter-group structure modeling mechanisms to encode the component-level as well as global-level facial structure patterns as a refinement for the 1D representations of landmarks through token communications in the spatial dimension via 1D convolutional layers. Experimental results on the 300VW and the TF databases show that 1DFormer successfully models the long-range sequential patterns as well as the inherent facial structures to learn informative 1D representations of landmark sequences, and achieves state-of-the-art performance on facial landmark tracking.
PromptFL: Let Federated Participants Cooperatively Learn Prompts Instead of Models -- Federated Learning in Age of Foundation Model
Aug 24, 2022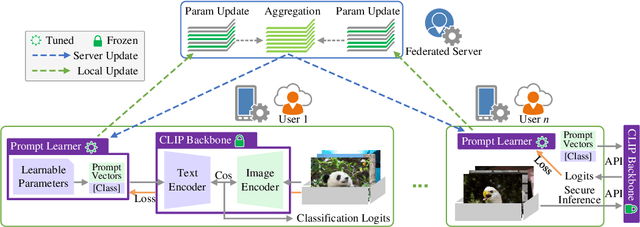
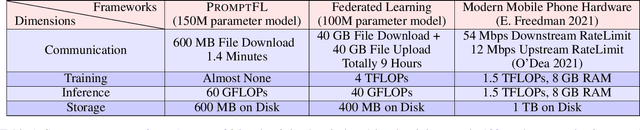
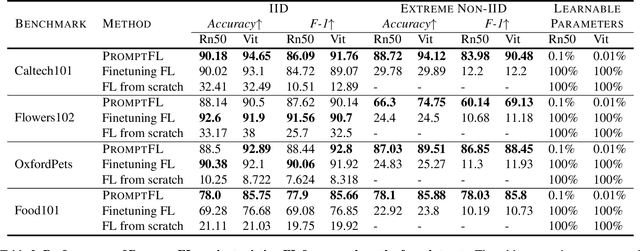
Quick global aggregation of effective distributed parameters is crucial to federated learning (FL), which requires adequate bandwidth for parameters communication and sufficient user data for local training. Otherwise, FL may cost excessive training time for convergence and produce inaccurate models. In this paper, we propose a brand-new FL framework, PromptFL, that replaces the federated model training with the federated prompt training, i.e., let federated participants train prompts instead of a shared model, to simultaneously achieve the efficient global aggregation and local training on insufficient data by exploiting the power of foundation models (FM) in a distributed way. PromptFL ships an off-the-shelf FM, i.e., CLIP, to distributed clients who would cooperatively train shared soft prompts based on very few local data. Since PromptFL only needs to update the prompts instead of the whole model, both the local training and the global aggregation can be significantly accelerated. And FM trained over large scale data can provide strong adaptation capability to distributed users tasks with the trained soft prompts. We empirically analyze the PromptFL via extensive experiments, and show its superiority in terms of system feasibility, user privacy, and performance.
Vertical Machine Unlearning: Selectively Removing Sensitive Information From Latent Feature Space
Feb 27, 2022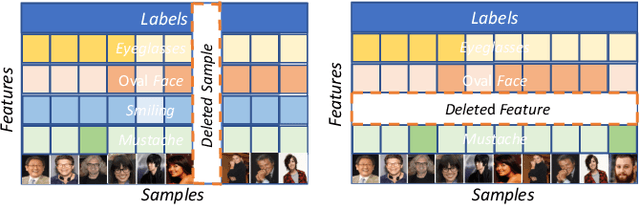
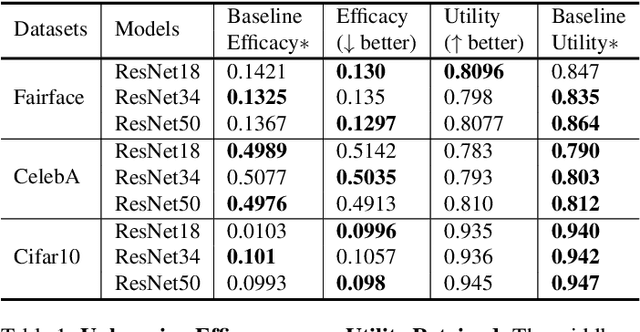
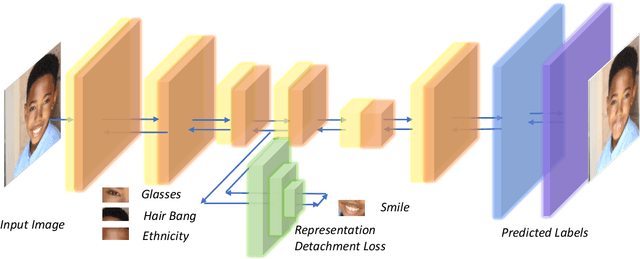
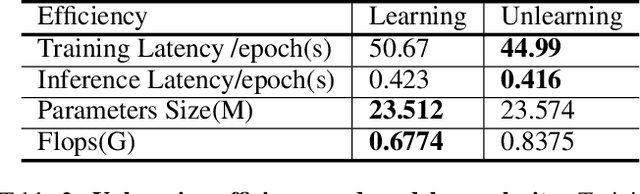
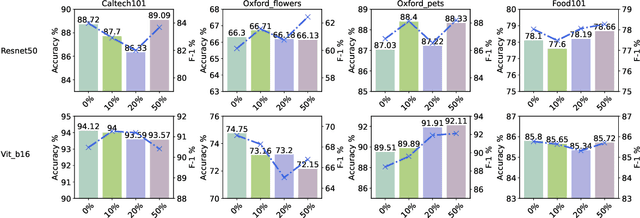
Recently, the enactment of privacy regulations has promoted the rise of machine unlearning paradigm. Most existing studies mainly focus on removing unwanted data samples from a learnt model. Yet we argue that they remove overmuch information of data samples from latent feature space, which is far beyond the sensitive feature scope that genuinely needs to be unlearned. In this paper, we investigate a vertical unlearning mode, aiming at removing only sensitive information from latent feature space. First, we introduce intuitive and formal definitions for this unlearning and show its orthogonal relationship with existing horizontal unlearning. Secondly, given the fact of lacking general solutions to vertical unlearning, we introduce a ground-breaking solution based on representation detachment, where the task-related information is encouraged to retain while the sensitive information is progressively forgotten. Thirdly, observing that some computation results during representation detachment are hard to obtain in practice, we propose an approximation with an upper bound to estimate it, with rigorous theoretical analysis. We validate our method by spanning several datasets and models with prevailing performance. We envision this work as a necessity for future machine unlearning system and an essential component of the latest privacy-related legislation.
DialogueBERT: A Self-Supervised Learning based Dialogue Pre-training Encoder
Sep 22, 2021
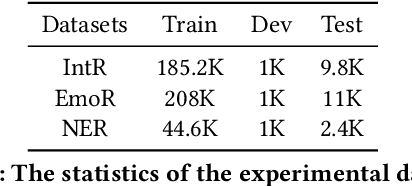


With the rapid development of artificial intelligence, conversational bots have became prevalent in mainstream E-commerce platforms, which can provide convenient customer service timely. To satisfy the user, the conversational bots need to understand the user's intention, detect the user's emotion, and extract the key entities from the conversational utterances. However, understanding dialogues is regarded as a very challenging task. Different from common language understanding, utterances in dialogues appear alternately from different roles and are usually organized as hierarchical structures. To facilitate the understanding of dialogues, in this paper, we propose a novel contextual dialogue encoder (i.e. DialogueBERT) based on the popular pre-trained language model BERT. Five self-supervised learning pre-training tasks are devised for learning the particularity of dialouge utterances. Four different input embeddings are integrated to catch the relationship between utterances, including turn embedding, role embedding, token embedding and position embedding. DialogueBERT was pre-trained with 70 million dialogues in real scenario, and then fine-tuned in three different downstream dialogue understanding tasks. Experimental results show that DialogueBERT achieves exciting results with 88.63% accuracy for intent recognition, 94.25% accuracy for emotion recognition and 97.04% F1 score for named entity recognition, which outperforms several strong baselines by a large margin.