 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBE-MLZSL: A Group Bi-Enhancement Framework for Multi-Label Zero-Shot Learning
Sep 14, 2023



This paper investigates a challenging problem of zero-shot learning in the multi-label scenario (MLZSL), wherein, the model is trained to recognize multiple unseen classes within a sample (e.g., an image) based on seen classes and auxiliary knowledge, e.g., semantic information. Existing methods usually resort to analyzing the relationship of various seen classes residing in a sample from the dimension of spatial or semantic characteristics, and transfer the learned model to unseen ones. But they ignore the effective integration of local and global features. That is, in the process of inferring unseen classes, global features represent the principal direction of the image in the feature space, while local features should maintain uniqueness within a certain range. This integrated neglect will make the model lose its grasp of the main components of the image. Relying only on the local existence of seen classes during the inference stage introduces unavoidable bias. In this paper, we propose a novel and effective group bi-enhancement framework for MLZSL, dubbed GBE-MLZSL, to fully make use of such properties and enable a more accurate and robust visual-semantic projection. Specifically, we split the feature maps into several feature groups, of which each feature group can be trained independently with the Local Information Distinguishing Module (LID) to ensure uniqueness. Meanwhile, a Global Enhancement Module (GEM) is designed to preserve the principal direction. Besides, a static graph structure is designed to construct the correlation of local features. Experiments on large-scale MLZSL benchmark datasets NUS-WIDE and Open-Images-v4 demonstrate that the proposed GBE-MLZSL outperforms other state-of-the-art methods with large margins.
Vertical Machine Unlearning: Selectively Removing Sensitive Information From Latent Feature Space
Feb 27, 2022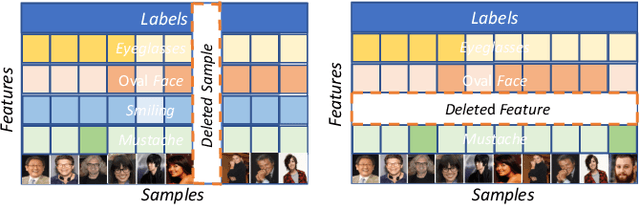
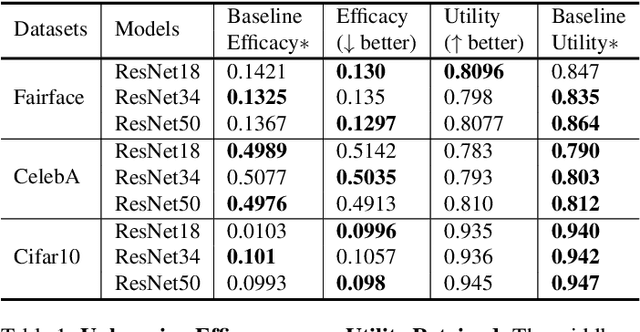
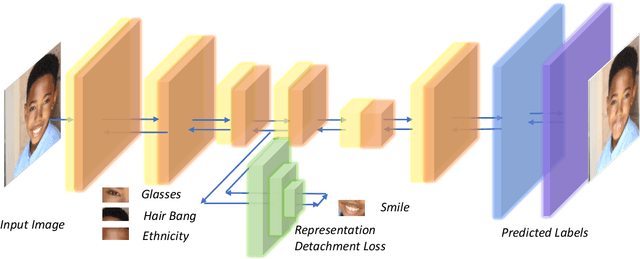
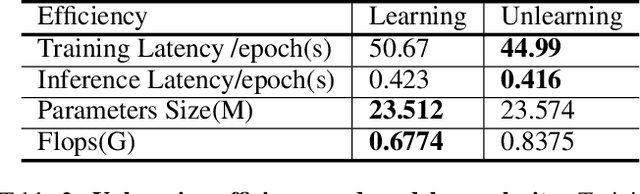
Recently, the enactment of privacy regulations has promoted the rise of machine unlearning paradigm. Most existing studies mainly focus on removing unwanted data samples from a learnt model. Yet we argue that they remove overmuch information of data samples from latent feature space, which is far beyond the sensitive feature scope that genuinely needs to be unlearned. In this paper, we investigate a vertical unlearning mode, aiming at removing only sensitive information from latent feature space. First, we introduce intuitive and formal definitions for this unlearning and show its orthogonal relationship with existing horizontal unlearning. Secondly, given the fact of lacking general solutions to vertical unlearning, we introduce a ground-breaking solution based on representation detachment, where the task-related information is encouraged to retain while the sensitive information is progressively forgotten. Thirdly, observing that some computation results during representation detachment are hard to obtain in practice, we propose an approximation with an upper bound to estimate it, with rigorous theoretical analysis. We validate our method by spanning several datasets and models with prevailing performance. We envision this work as a necessity for future machine unlearning system and an essential component of the latest privacy-related legislation.