 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSI-Policy: Learning Structured Scene Interfaces for Vision-Language Robotic Manipulation
Jun 25, 2026Real-world robotic manipulation demands spatial grounding, task-aware reasoning, and precise control. Learning such capabilities becomes particularly challenging in the low-data regime. Prior methods often trade off scalable task-level reasoning and explicit physical structure: video-based approaches can drift geometrically over long horizons, 3D approaches often require depth sensing, and many flow/trajectory interfaces emphasize motion without an explicit RGB-only geometric representation. We introduce SSI-Policy, a modular framework built around a Structured Scene Interface (SSI) -- a unified, RGB-only intermediate representation that jointly encodes monocular depth features, language-grounded object layouts, and instruction-conditioned 2D motion trajectories. Critically, SSI is robot-agnostic and trainable from action-free video, decoupling perception from control so that the downstream policy can learn from few demonstrations. On the LIBERO benchmark with only 10 demonstrations per task, SSI-Policy improves over the strongest prior method by nearly 15\% and remains competitive with 50-demo methods that leverage large-scale external pretraining. Ablations show that geometric and motion cues provide complementary benefits within the shared interface. We further validate on 13 real-world tasks spanning spatial reasoning, cross-embodiment transfer, and contact-rich manipulation.
HORIZON: Recoverability-Governed Curriculum for Physical-Domain Scaling
Jun 03, 2026Scaling robust robot policies requires more than broader randomization, because physical-domain experience must remain organized and learnable throughout training. We study when a policy can benefit from harder physics and identify recoverability as a central constraint in on-policy physical-domain scaling. In on-policy training, new dynamics are useful only insofar as they remain close enough to the current policy to generate corrective on-policy data, rather than collapsing rollouts into unrecoverable failures. Using quadruped locomotion as a physically demanding benchmark for embodied generalization, we introduce HORIZON, a checkpointed frontier curriculum that expands physical domains only within the current policy's recoverable boundary. HORIZON uses rollback and boundary refinement to govern each expansion step, turning fixed randomization into a continual process of physical-domain growth. Experiments reveal three regularities of physical-domain expansion. First, direct domain widening is uneven across physical axes and often unlearnable without staged ordering. Second, domain composition is non-monotonic, and adding more domains beyond a compact core can dilute recoverable joint samples and reduce overall robustness. Third, offline distillation of isolated experts cannot substitute for the joint interaction generated by on-policy curriculum. Together, these results frame physical-domain generalization as a continual growth problem for embodied control, with recoverability as the organizing principle for on-policy expansion.
Exploring Spatial Intelligence from a Generative Perspective
Apr 22, 2026Spatial intelligence is essential for multimodal large language models, yet current benchmarks largely assess it only from an understanding perspective. We ask whether modern generative or unified multimodal models also possess generative spatial intelligence (GSI), the ability to respect and manipulate 3D spatial constraints during image generation, and whether such capability can be measured or improved. We introduce GSI-Bench, the first benchmark designed to quantify GSI through spatially grounded image editing. It consists of two complementary components: GSI-Real, a high-quality real-world dataset built via a 3D-prior-guided generation and filtering pipeline, and GSI-Syn, a large-scale synthetic benchmark with controllable spatial operations and fully automated labeling. Together with a unified evaluation protocol, GSI-Bench enables scalable, model-agnostic assessment of spatial compliance and editing fidelity. Experiments show that fine-tuning unified multimodal models on GSI-Syn yields substantial gains on both synthetic and real tasks and, strikingly, also improves downstream spatial understanding. This provides the first clear evidence that generative training can tangibly strengthen spatial reasoning, establishing a new pathway for advancing spatial intelligence in multimodal models.
ODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
Aug 11, 2025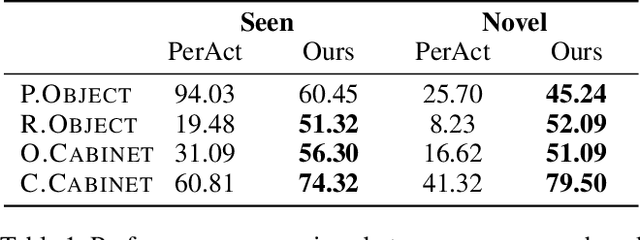


Language-guided long-horizon mobile manipulation has long been a grand challenge in embodied semantic reasoning, generalizable manipulation, and adaptive locomotion. Three fundamental limitations hinder progress: First, although large language models have improved spatial reasoning and task planning through semantic priors, existing implementations remain confined to tabletop scenarios, failing to address the constrained perception and limited actuation ranges of mobile platforms. Second, current manipulation strategies exhibit insufficient generalization when confronted with the diverse object configurations encountered in open-world environments. Third, while crucial for practical deployment, the dual requirement of maintaining high platform maneuverability alongside precise end-effector control in unstructured settings remains understudied. In this work, we present ODYSSEY, a unified mobile manipulation framework for agile quadruped robots equipped with manipulators, which seamlessly integrates high-level task planning with low-level whole-body control. To address the challenge of egocentric perception in language-conditioned tasks, we introduce a hierarchical planner powered by a vision-language model, enabling long-horizon instruction decomposition and precise action execution. At the control level, our novel whole-body policy achieves robust coordination across challenging terrains. We further present the first benchmark for long-horizon mobile manipulation, evaluating diverse indoor and outdoor scenarios. Through successful sim-to-real transfer, we demonstrate the system's generalization and robustness in real-world deployments, underscoring the practicality of legged manipulators in unstructured environments. Our work advances the feasibility of generalized robotic assistants capable of complex, dynamic tasks. Our project page: https://kaijwang.github.io/odyssey.github.io/
Fast and Robust Bin-picking System for Densely Piled Industrial Objects
Dec 04, 2020



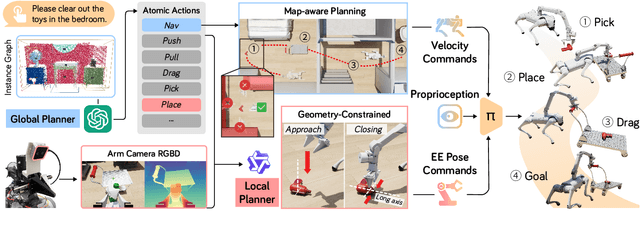
Objects grasping, also known as the bin-picking, is one of the most common tasks faced by industrial robots. While much work has been done in related topics, grasping randomly piled objects still remains a challenge because much of the existing work either lack robustness or costs too much resource. In this paper, we develop a fast and robust bin-picking system for grasping densely piled objects adaptively and safely. The proposed system starts with point cloud segmentation using improved density-based spatial clustering of application with noise (DBSCAN) algorithm, which is improved by combining the region growing algorithm and using Octree to speed up the calculation. The system then uses principle component analysis (PCA) for coarse registration and iterative closest point (ICP) for fine registration. We propose a grasp risk score (GRS) to evaluate each object by the collision probability, the stability of the object, and the whole pile's stability. Through real tests with the Anno robot, our method is verified to be advanced in speed and robustness.
Breiman's "Two Cultures" Revisited and Reconciled
May 27, 2020
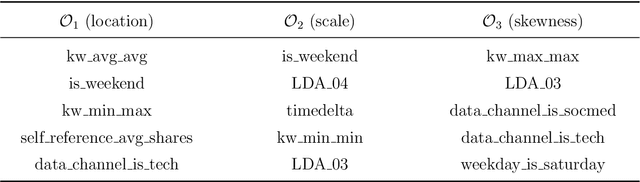
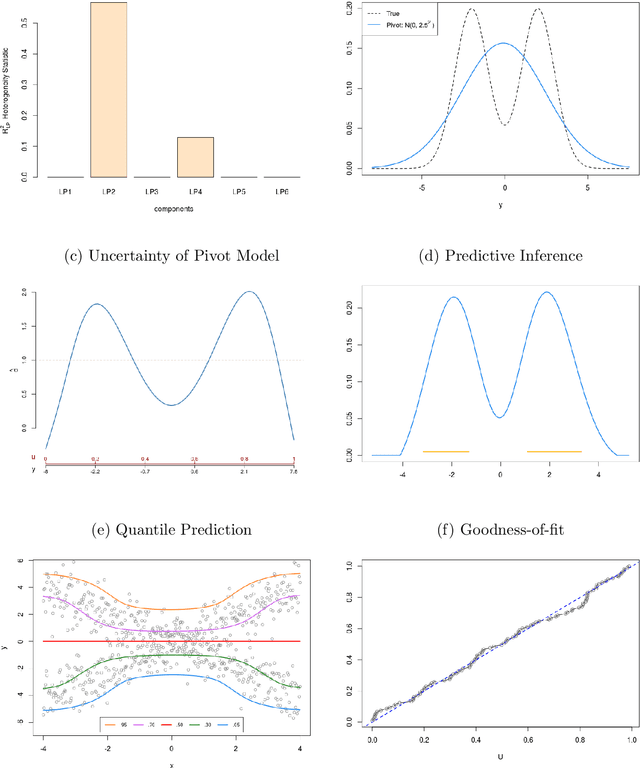
In a landmark paper published in 2001, Leo Breiman described the tense standoff between two cultures of data modeling: parametric statistical and algorithmic machine learning. The cultural division between these two statistical learning frameworks has been growing at a steady pace in recent years. What is the way forward? It has become blatantly obvious that this widening gap between "the two cultures" cannot be averted unless we find a way to blend them into a coherent whole. This article presents a solution by establishing a link between the two cultures. Through examples, we describe the challenges and potential gains of this new integrated statistical thinking.
On The Problem of Relevance in Statistical Inference
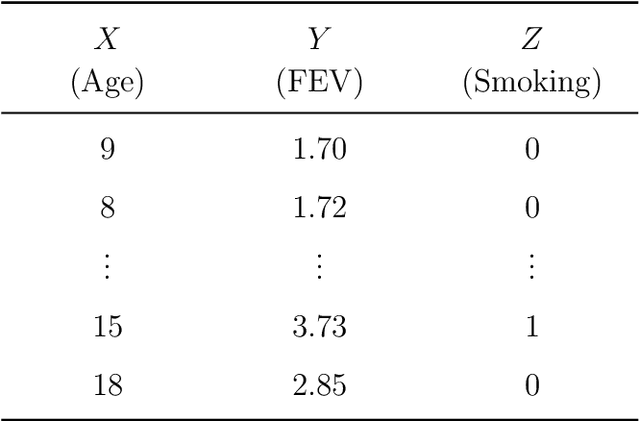
Apr 30, 2020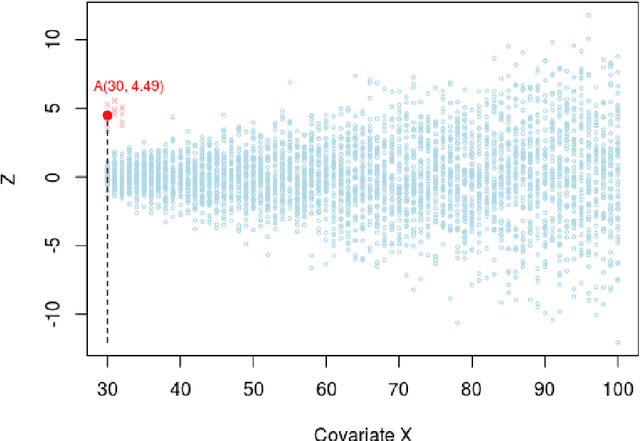
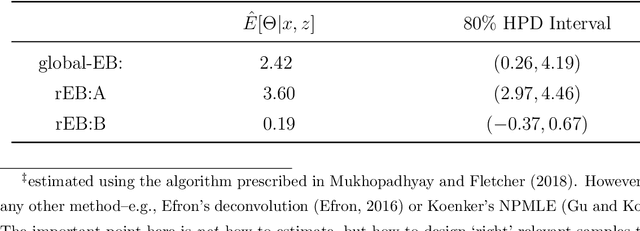
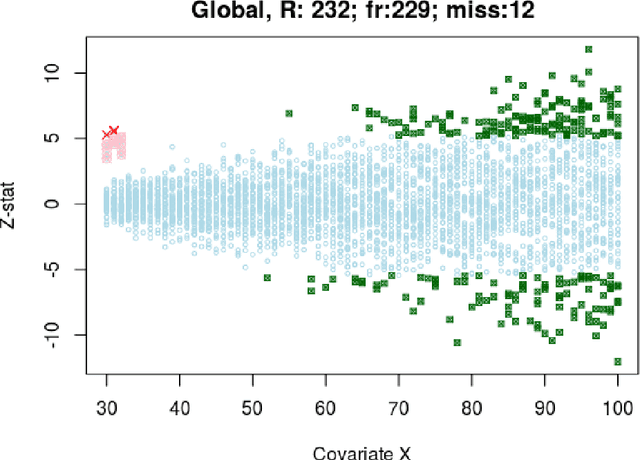

How many statistical inference tools we have for inference from massive data? A huge number, but only when we are ready to assume the given database is homogenous, consisting of a large cohort of "similar" cases. Why we need the homogeneity assumption? To make `learning from the experience of others' or `borrowing strength' possible. But, what if, we are dealing with a massive database of heterogeneous cases (which is a norm in almost all modern data-science applications including neuroscience, genomics, healthcare, and astronomy)? How many methods we have in this situation? Not much, if not ZERO. Why? It's not obvious how to go about gathering strength when each piece of information is fuzzy. The danger is that, if we include irrelevant cases, borrowing information might heavily damage the quality of the inference! This raises some fundamental questions for big data inference: When (not) to borrow? Whom (not) to borrow? How (not) to borrow? These questions are at the heart of the "Problem of Relevance" in statistical inference -- a puzzle that has remained too little addressed since its inception nearly half a century ago. Here we offer the first practical theory of relevance with precisely describable statistical formulation and algorithm. Through examples, we demonstrate how our new statistical perspective answers previously unanswerable questions in a realistic and feasible way.
Nonparametric High-dimensional K-sample Comparison
Oct 03, 2018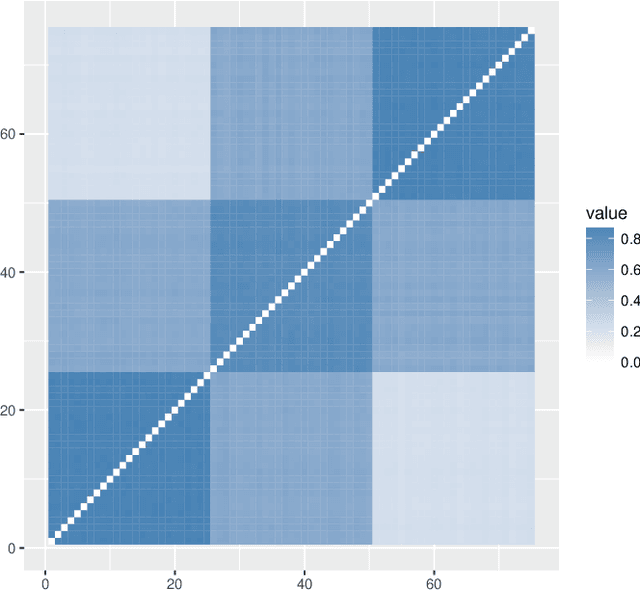
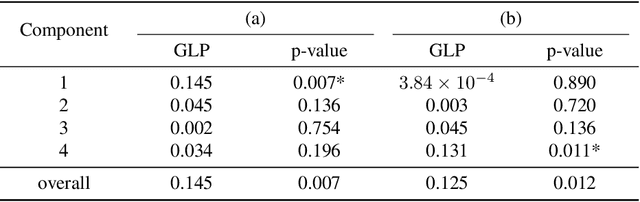
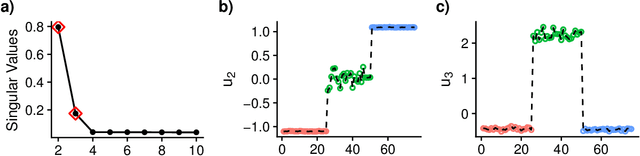

High-dimensional k-sample comparison is a common applied problem. We construct a class of easy-to-implement nonparametric distribution-free tests based on new tools and unexplored connections with spectral graph theory. The test is shown to possess various desirable properties along with a characteristic exploratory flavor that has practical consequences. The numerical examples show that our method works surprisingly well under a broad range of realistic situations.
Adaptive Affinity Propagation Clustering
May 08, 2008
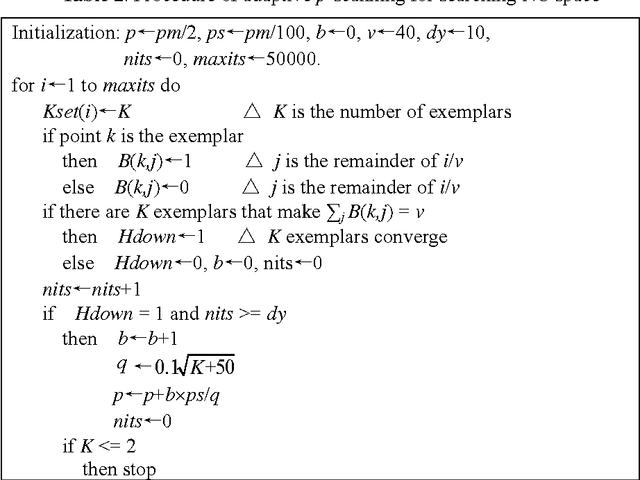
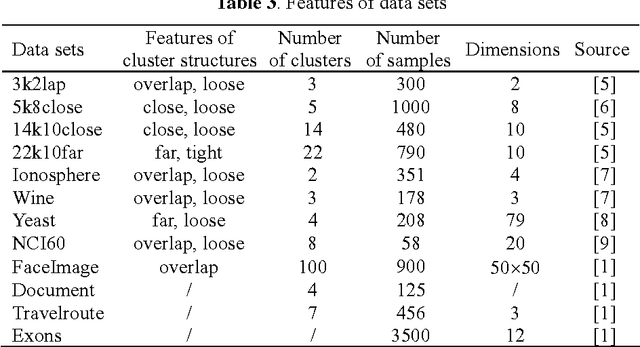
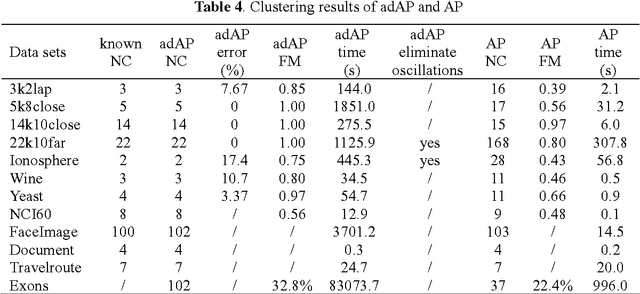
Affinity propagation clustering (AP) has two limitations: it is hard to know what value of parameter 'preference' can yield an optimal clustering solution, and oscillations cannot be eliminated automatically if occur. The adaptive AP method is proposed to overcome these limitations, including adaptive scanning of preferences to search space of the number of clusters for finding the optimal clustering solution, adaptive adjustment of damping factors to eliminate oscillations, and adaptive escaping from oscillations when the damping adjustment technique fails. Experimental results on simulated and real data sets show that the adaptive AP is effective and can outperform AP in quality of clustering results.
* an English version of original paper