 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreiman's "Two Cultures" Revisited and Reconciled
May 27, 2020
In a landmark paper published in 2001, Leo Breiman described the tense standoff between two cultures of data modeling: parametric statistical and algorithmic machine learning. The cultural division between these two statistical learning frameworks has been growing at a steady pace in recent years. What is the way forward? It has become blatantly obvious that this widening gap between "the two cultures" cannot be averted unless we find a way to blend them into a coherent whole. This article presents a solution by establishing a link between the two cultures. Through examples, we describe the challenges and potential gains of this new integrated statistical thinking.
Nonparametric High-dimensional K-sample Comparison
Oct 03, 2018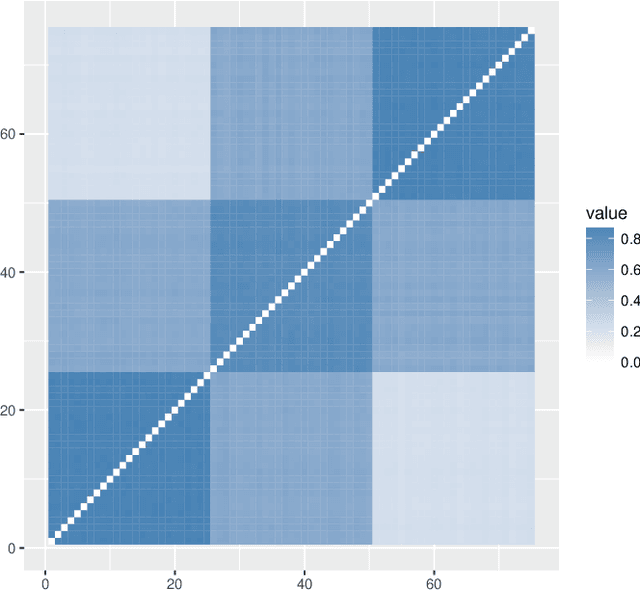
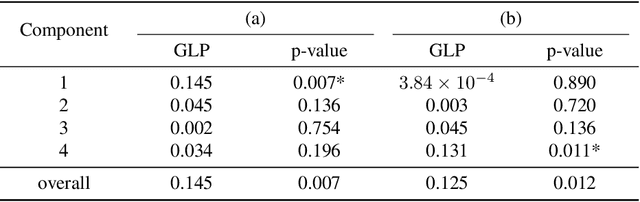
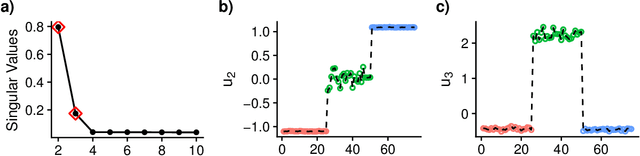

High-dimensional k-sample comparison is a common applied problem. We construct a class of easy-to-implement nonparametric distribution-free tests based on new tools and unexplored connections with spectral graph theory. The test is shown to possess various desirable properties along with a characteristic exploratory flavor that has practical consequences. The numerical examples show that our method works surprisingly well under a broad range of realistic situations.
Bayesian Modeling via Goodness-of-fit
Apr 16, 2018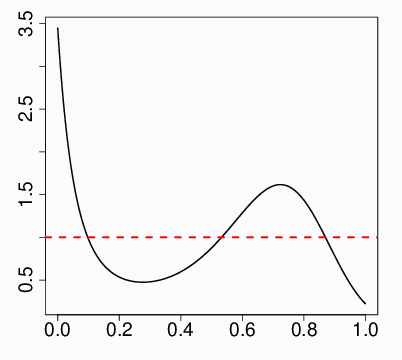

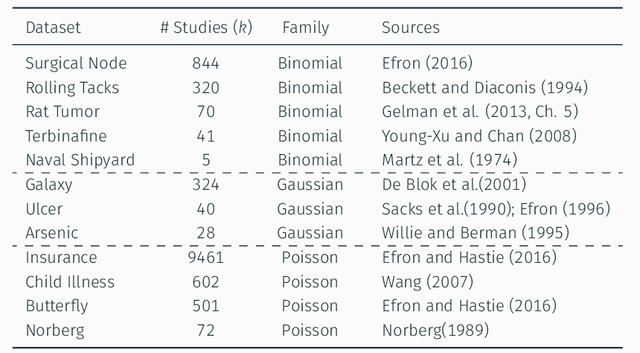
The two key issues of modern Bayesian statistics are: (i) establishing principled approach for distilling statistical prior that is consistent with the given data from an initial believable scientific prior; and (ii) development of a Bayes-frequentist consolidated data analysis workflow that is more effective than either of the two separately. In this paper, we propose the idea of "Bayes via goodness of fit" as a framework for exploring these fundamental questions, in a way that is general enough to embrace almost all of the familiar probability models. Several illustrative examples show the benefit of this new point of view as a practical data analysis tool. Relationship with other Bayesian cultures is also discussed.