 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sound Demixing Challenge 2023 $\unicode{x2013}$ Cinematic Demixing Track
Aug 14, 2023
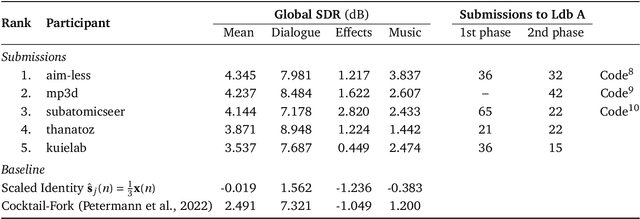


This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX'23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used. Especially, we detail CDXDB23, a new hidden dataset constructed from real movies that was used to rank the submissions. The paper also offers insights into the most successful approaches employed by participants. Compared to the cocktail-fork baseline, the best-performing system trained exclusively on the simulated Divide and Remaster (DnR) dataset achieved an improvement of 1.8dB in SDR whereas the top performing system on the open leaderboard, where any data could be used for training, saw a significant improvement of 5.7dB.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023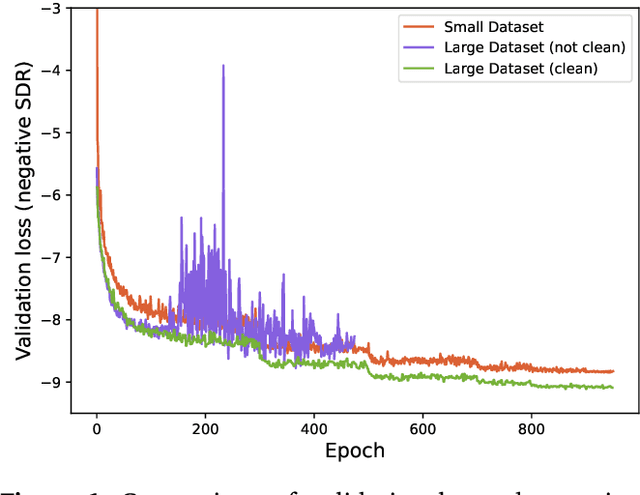
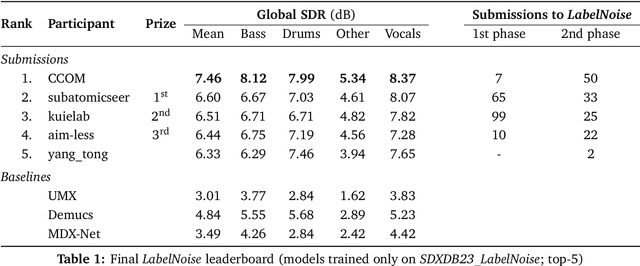

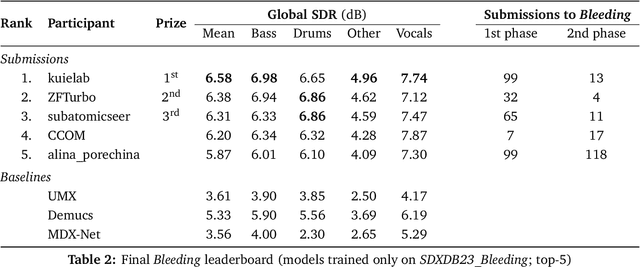
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Benchmarks and leaderboards for sound demixing tasks
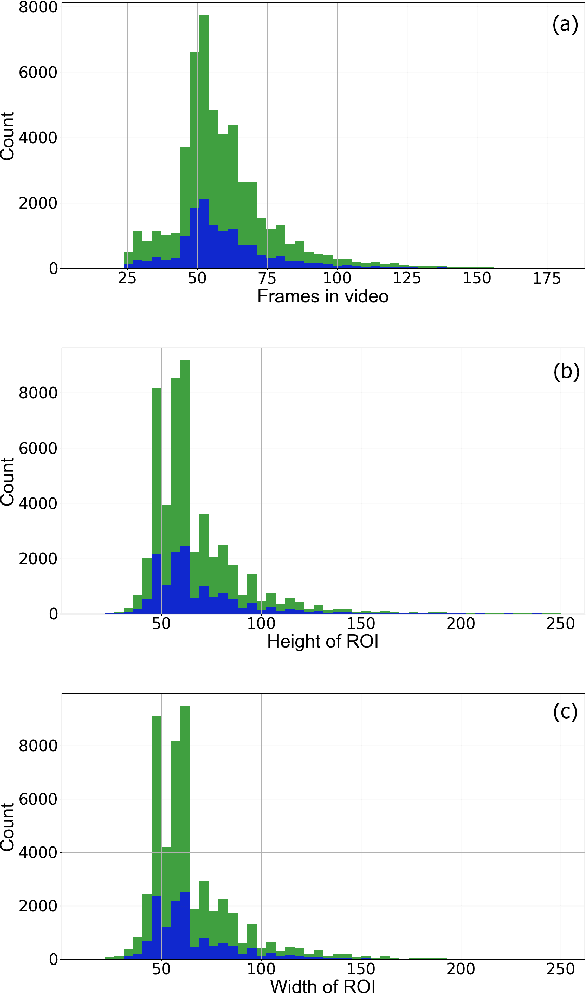
May 12, 2023Music demixing is the task of separating different tracks from the given single audio signal into components, such as drums, bass, and vocals from the rest of the accompaniment. Separation of sources is useful for a range of areas, including entertainment and hearing aids. In this paper, we introduce two new benchmarks for the sound source separation tasks and compare popular models for sound demixing, as well as their ensembles, on these benchmarks. For the models' assessments, we provide the leaderboard at https://mvsep.com/quality_checker/, giving a comparison for a range of models. The new benchmark datasets are available for download. We also develop a novel approach for audio separation, based on the ensembling of different models that are suited best for the particular stem. The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge. The code and the approach are open-sourced on GitHub.
3D Convolutional Neural Networks for Stalled Brain Capillary Detection
Apr 04, 2021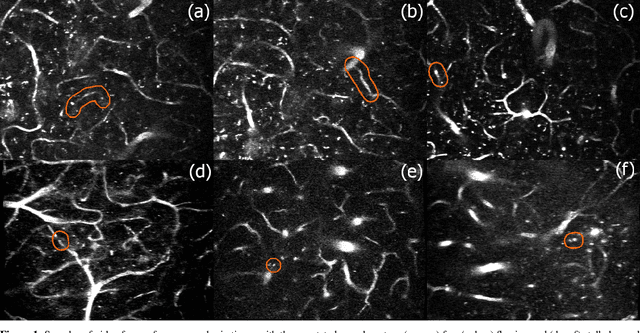


Adequate blood supply is critical for normal brain function. Brain vasculature dysfunctions such as stalled blood flow in cerebral capillaries are associated with cognitive decline and pathogenesis in Alzheimer's disease. Recent advances in imaging technology enabled generation of high-quality 3D images that can be used to visualize stalled blood vessels. However, localization of stalled vessels in 3D images is often required as the first step for downstream analysis, which can be tedious, time-consuming and error-prone, when done manually. Here, we describe a deep learning-based approach for automatic detection of stalled capillaries in brain images based on 3D convolutional neural networks. Our networks employed custom 3D data augmentations and were used weight transfer from pre-trained 2D models for initialization. We used an ensemble of several 3D models to produce the winning submission to the Clog Loss: Advance Alzheimer's Research with Stall Catchers machine learning competition that challenged the participants with classifying blood vessels in 3D image stacks as stalled or flowing. In this setting, our approach outperformed other methods and demonstrated state-of-the-art results, achieving 0.85 Matthews correlation coefficient, 85% sensitivity, and 99.3% specificity. The source code for our solution is made publicly available.
Roof material classification from aerial imagery
Apr 23, 2020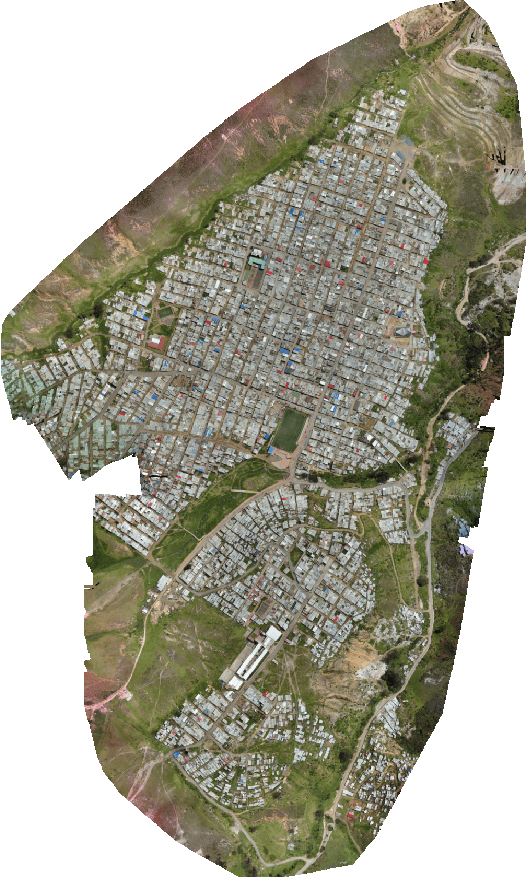
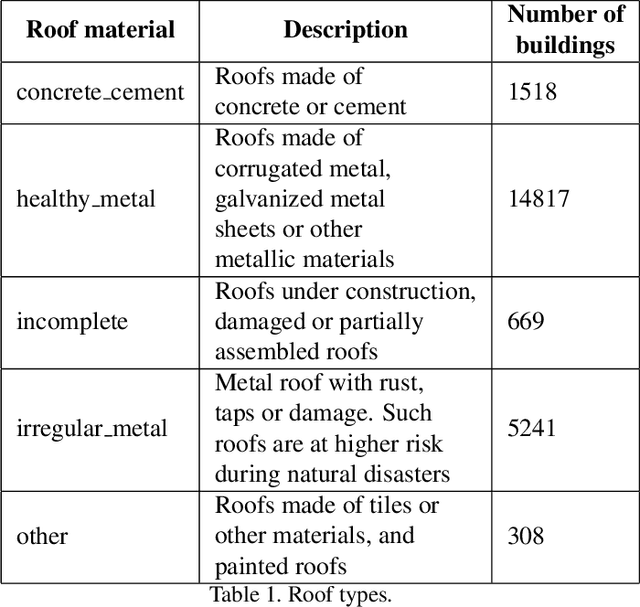

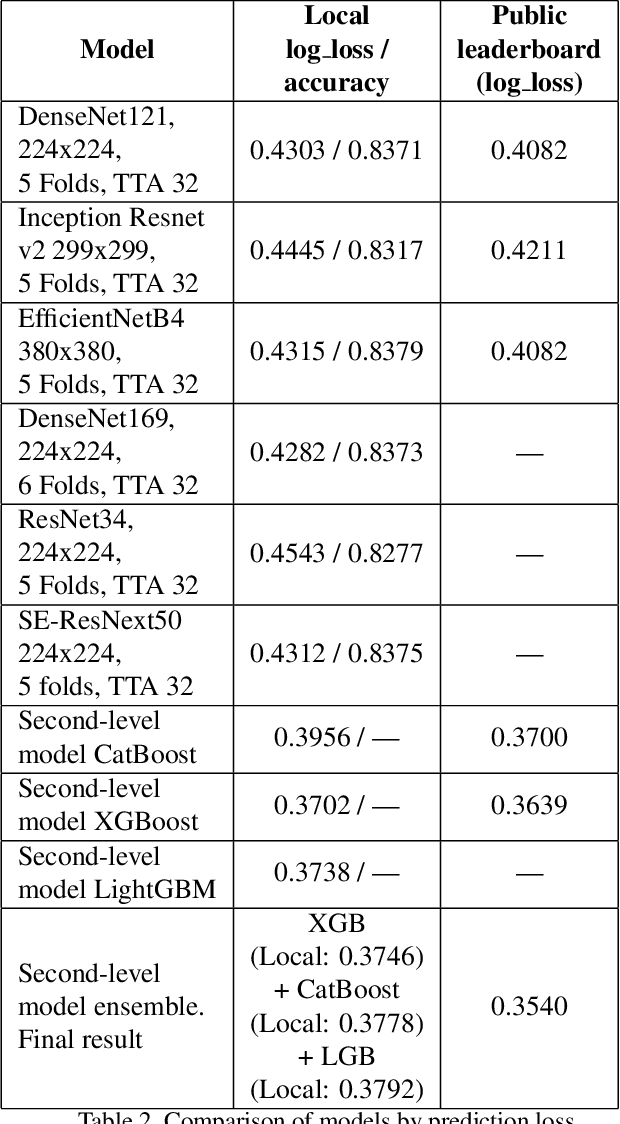
This paper describes an algorithm for classification of roof materials using aerial photographs. Main advantages of the algorithm are proposed methods to improve prediction accuracy. Proposed methods includes: method of converting ImageNet weights of neural networks for using multi-channel images; special set of features of second level models that are used in addition to specific predictions of neural networks; special set of image augmentations that improve training accuracy. In addition, complete flow for solving this problem is proposed. The following content is available in open access: solution code, weight sets and architecture of the used neural networks. The proposed solution achieved second place in the competition "Open AI Caribbean Challenge".
Weighted Boxes Fusion: ensembling boxes for object detection models
Oct 29, 2019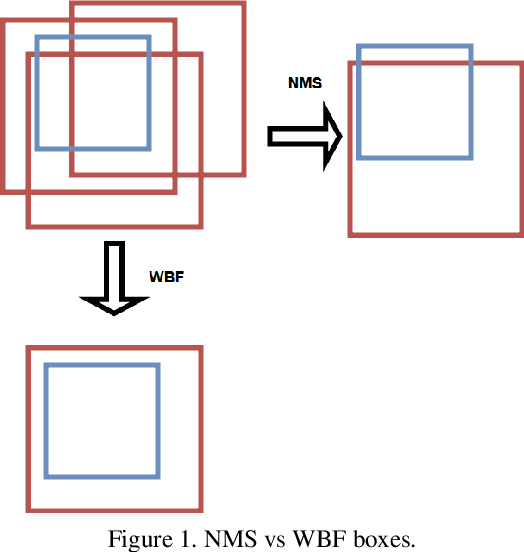


In this work, we introduce a novel Weighted Box Fusion (WBF) ensembling algorithm that boosts the performance by ensembling predictions from different object detection models. Method was tested on predictions of different models trained on large Open Images Dataset. The source code for our approach is publicly available at https://github.com/ZFTurbo/Weighted-Boxes-Fusion
Bayesian Feature Pyramid Networks for Automatic Multi-Label Segmentation of Chest X-rays and Assessment of Cardio-Thoratic Ratio
Aug 08, 2019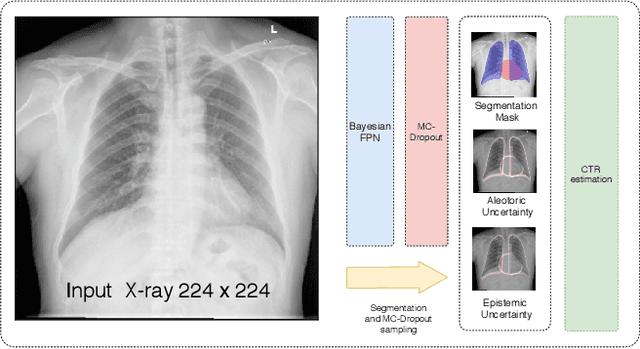
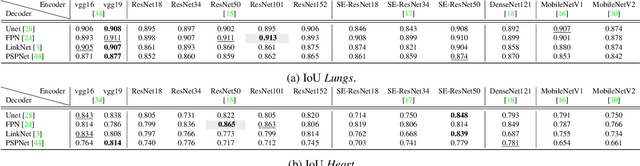
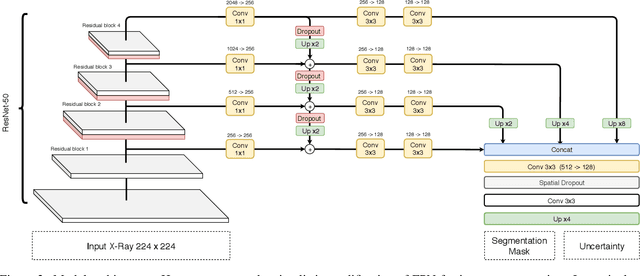
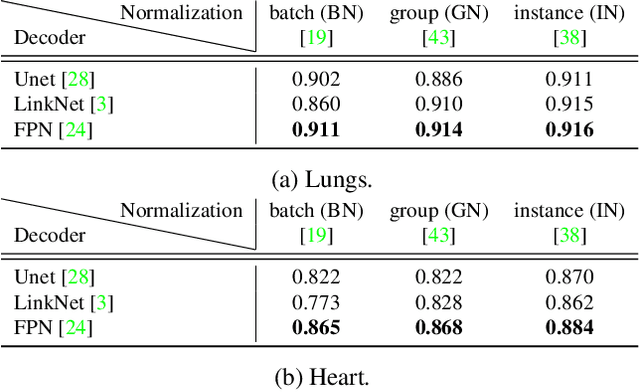
Cardiothoratic ratio (CTR) estimated from chest radiographs is a marker indicative of cardiomegaly, the presence of which is in the criteria for heart failure diagnosis. Existing methods for automatic assessment of CTR are driven by Deep Learning-based segmentation. However, these techniques produce only point estimates of CTR but clinical decision making typically assumes the uncertainty. In this paper, we propose a novel method for chest X-ray segmentation and CTR assessment in an automatic manner. In contrast to the previous art, we, for the first time, propose to estimate CTR with uncertainty bounds. Our method is based on Deep Convolutional Neural Network with Feature Pyramid Network (FPN) decoder. We propose two modifications of FPN: replace the batch normalization with instance normalization and inject the dropout which allows to obtain the Monte-Carlo estimates of the segmentation maps at test time. Finally, using the predicted segmentation mask samples, we estimate CTR with uncertainty. In our experiments we demonstrate that the proposed method generalizes well to three different test sets. Finally, we make the annotations produced by two radiologists for all our datasets publicly available.