 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sound Demixing Challenge 2023 $\unicode{x2013}$ Cinematic Demixing Track
Aug 14, 2023
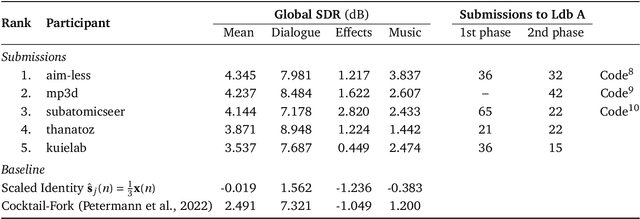


This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX'23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used. Especially, we detail CDXDB23, a new hidden dataset constructed from real movies that was used to rank the submissions. The paper also offers insights into the most successful approaches employed by participants. Compared to the cocktail-fork baseline, the best-performing system trained exclusively on the simulated Divide and Remaster (DnR) dataset achieved an improvement of 1.8dB in SDR whereas the top performing system on the open leaderboard, where any data could be used for training, saw a significant improvement of 5.7dB.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023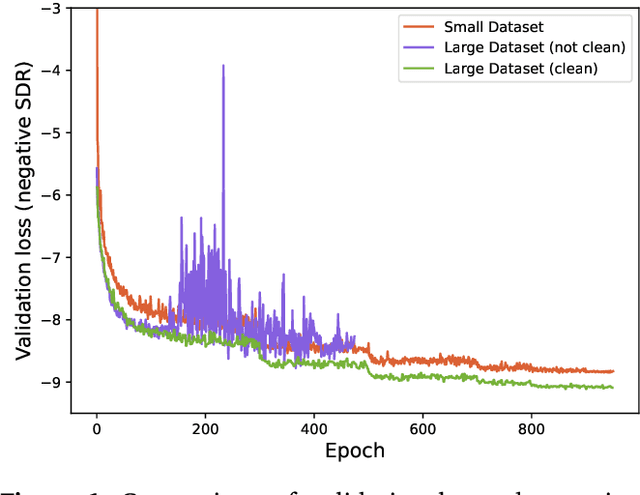
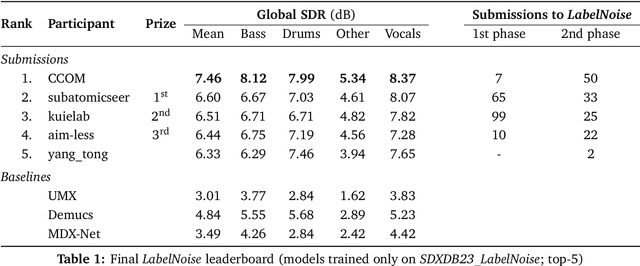

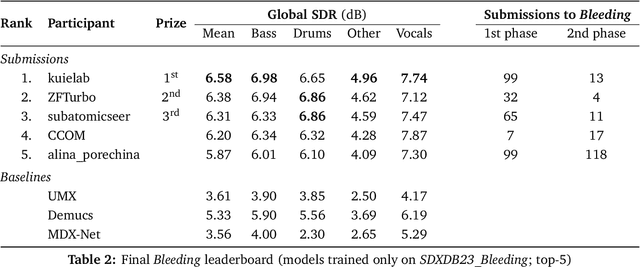
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Benchmarks and leaderboards for sound demixing tasks
May 12, 2023Music demixing is the task of separating different tracks from the given single audio signal into components, such as drums, bass, and vocals from the rest of the accompaniment. Separation of sources is useful for a range of areas, including entertainment and hearing aids. In this paper, we introduce two new benchmarks for the sound source separation tasks and compare popular models for sound demixing, as well as their ensembles, on these benchmarks. For the models' assessments, we provide the leaderboard at https://mvsep.com/quality_checker/, giving a comparison for a range of models. The new benchmark datasets are available for download. We also develop a novel approach for audio separation, based on the ensembling of different models that are suited best for the particular stem. The proposed solution was evaluated in the context of the Music Demixing Challenge 2023 and achieved top results in different tracks of the challenge. The code and the approach are open-sourced on GitHub.