 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Topic Modeling in the Voynich Manuscript
Jul 06, 2021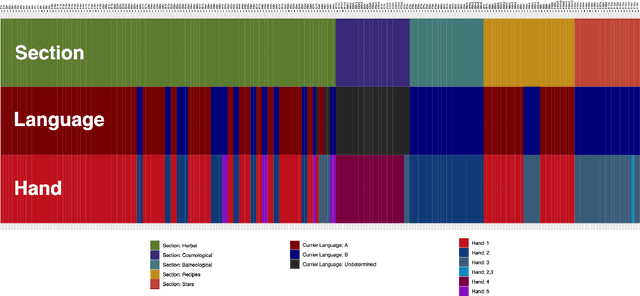
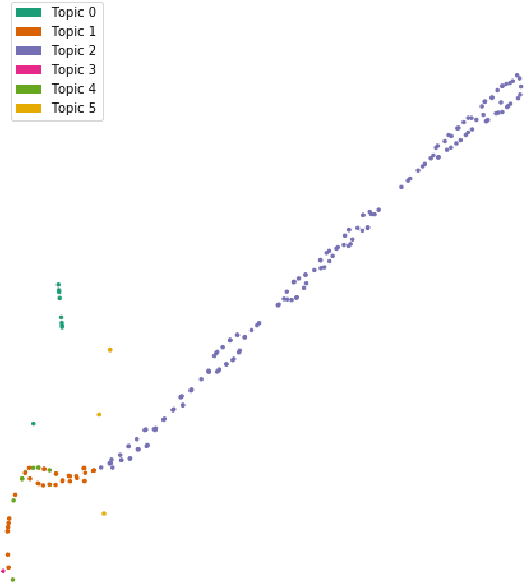
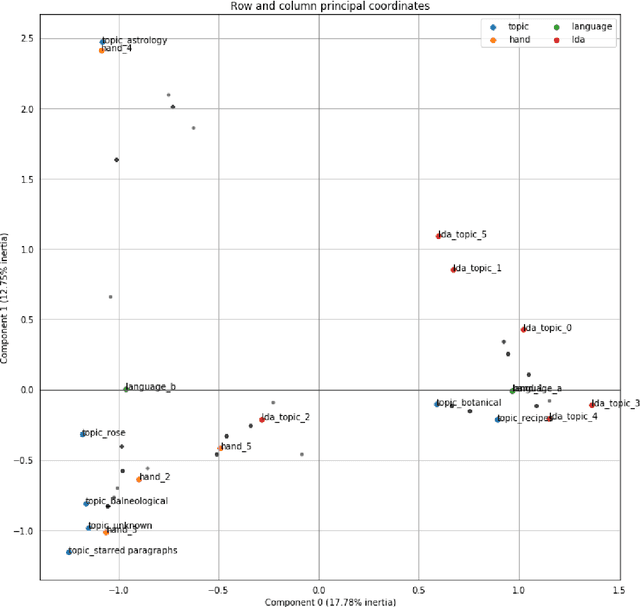
This article presents the results of investigations using topic modeling of the Voynich Manuscript (Beinecke MS408). Topic modeling is a set of computational methods which are used to identify clusters of subjects within text. We use latent dirichlet allocation, latent semantic analysis, and nonnegative matrix factorization to cluster Voynich pages into `topics'. We then compare the topics derived from the computational models to clusters derived from the Voynich illustrations and from paleographic analysis. We find that computationally derived clusters match closely to a conjunction of scribe and subject matter (as per the illustrations), providing further evidence that the Voynich Manuscript contains meaningful text.
Noise Sensitivity-Based Energy Efficient and Robust Adversary Detection in Neural Networks
Jan 05, 2021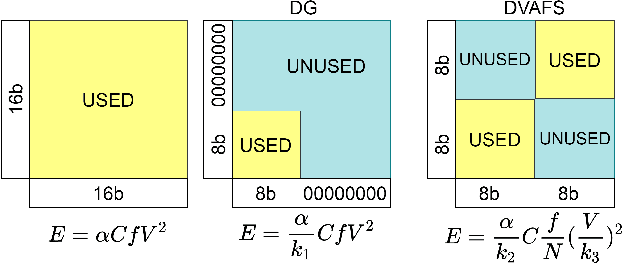
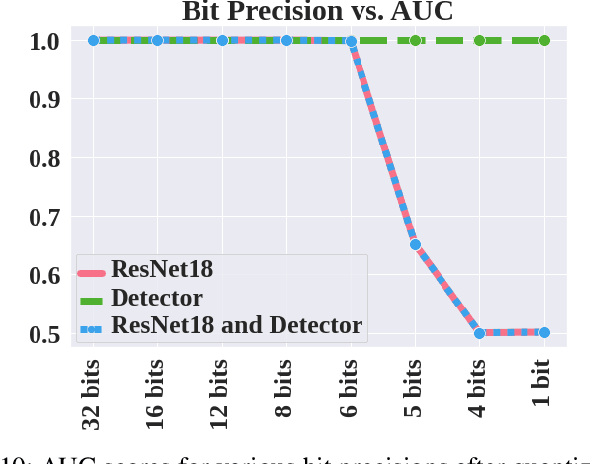
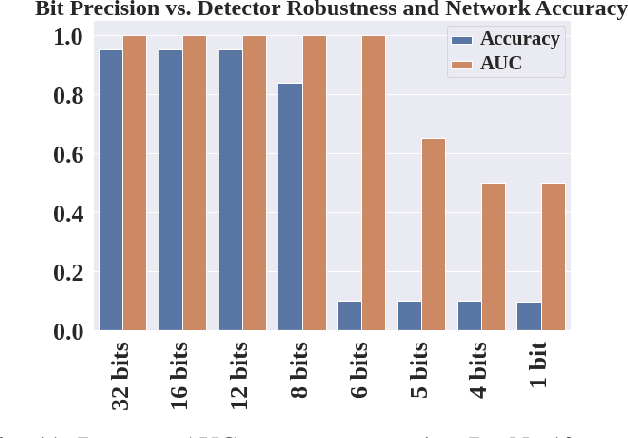
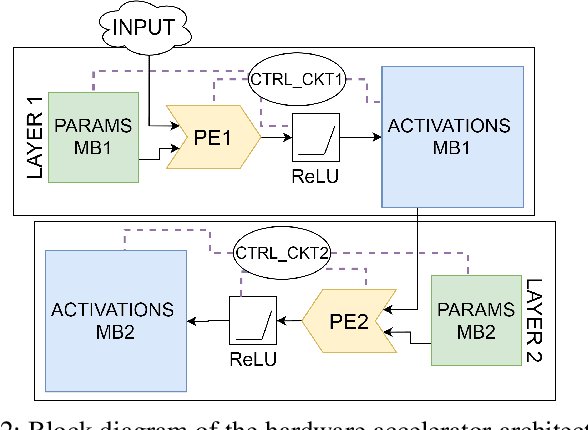
Neural networks have achieved remarkable performance in computer vision, however they are vulnerable to adversarial examples. Adversarial examples are inputs that have been carefully perturbed to fool classifier networks, while appearing unchanged to humans. Based on prior works on detecting adversaries, we propose a structured methodology of augmenting a deep neural network (DNN) with a detector subnetwork. We use $\textit{Adversarial Noise Sensitivity}$ (ANS), a novel metric for measuring the adversarial gradient contribution of different intermediate layers of a network. Based on the ANS value, we append a detector to the most sensitive layer. In prior works, more complex detectors were added to a DNN, increasing the inference computational cost of the model. In contrast, our structured and strategic addition of a detector to a DNN reduces the complexity of the model while making the overall network adversarially resilient. Through comprehensive white-box and black-box experiments on MNIST, CIFAR-10, and CIFAR-100, we show that our method improves state-of-the-art detector robustness against adversarial examples. Furthermore, we validate the energy efficiency of our proposed adversarial detection methodology through an extensive energy analysis on various hardware scalable CMOS accelerator platforms. We also demonstrate the effects of quantization on our detector-appended networks.
Probabilistic Predictions of People Perusing: Evaluating Metrics of Language Model Performance for Psycholinguistic Modeling
Sep 08, 2020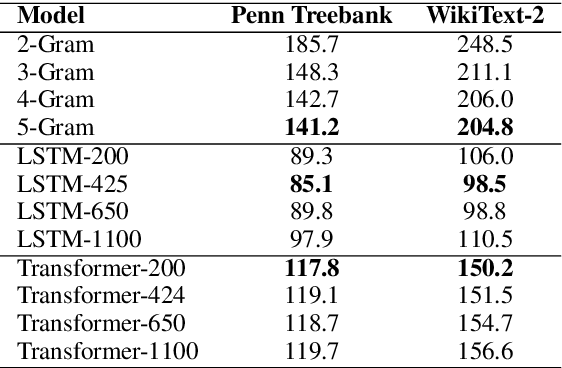
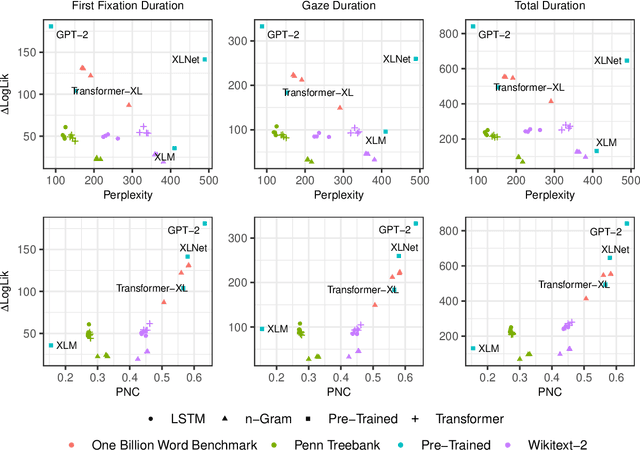
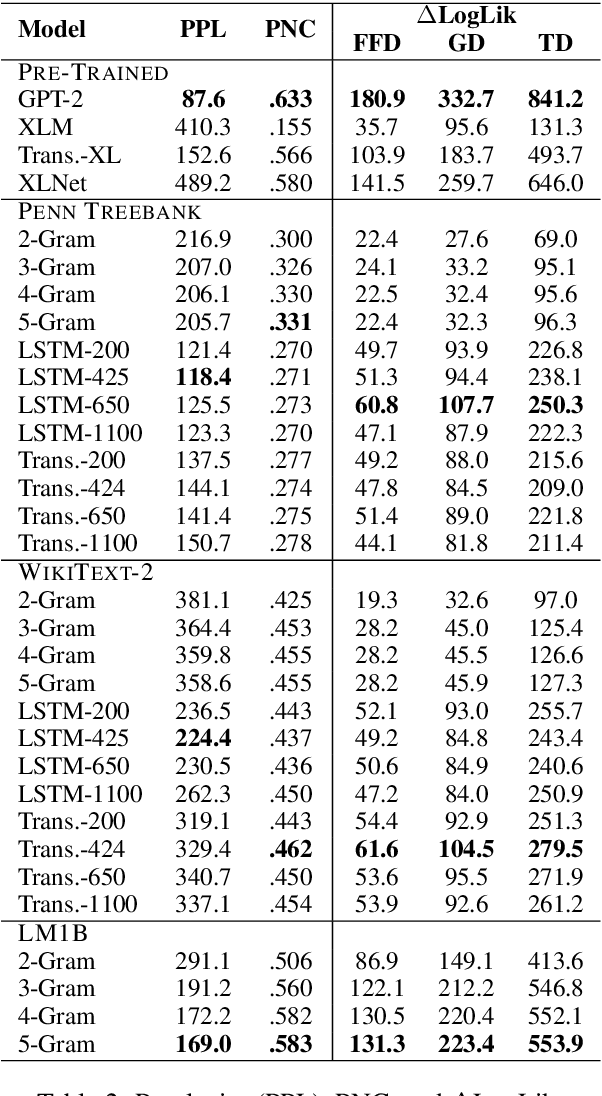
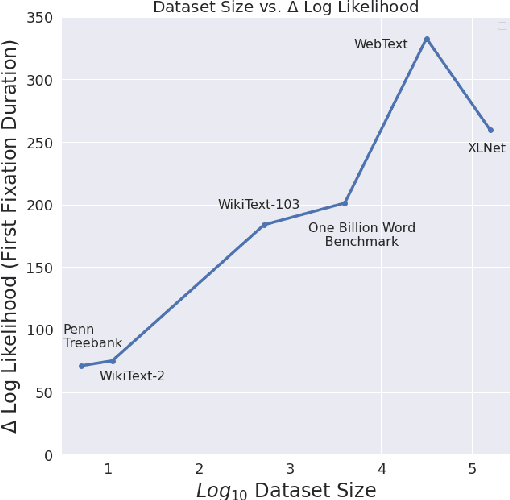
By positing a relationship between naturalistic reading times and information-theoretic surprisal, surprisal theory (Hale, 2001; Levy, 2008) provides a natural interface between language models and psycholinguistic models. This paper re-evaluates a claim due to Goodkind and Bicknell (2018) that a language model's ability to model reading times is a linear function of its perplexity. By extending Goodkind and Bicknell's analysis to modern neural architectures, we show that the proposed relation does not always hold for Long Short-Term Memory networks, Transformers, and pre-trained models. We introduce an alternate measure of language modeling performance called predictability norm correlation based on Cloze probabilities measured from human subjects. Our new metric yields a more robust relationship between language model quality and psycholinguistic modeling performance that allows for comparison between models with different training configurations.