 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Predictions of People Perusing: Evaluating Metrics of Language Model Performance for Psycholinguistic Modeling
Sep 08, 2020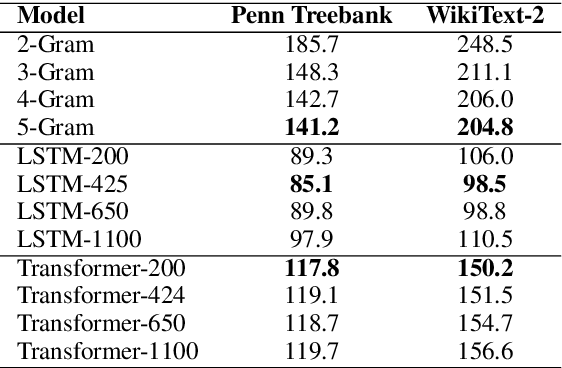
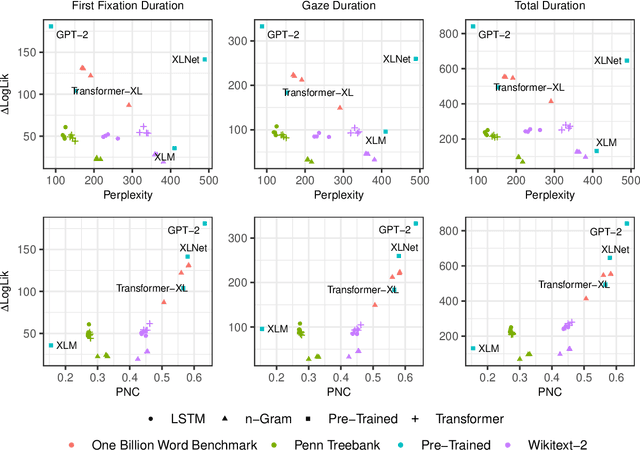
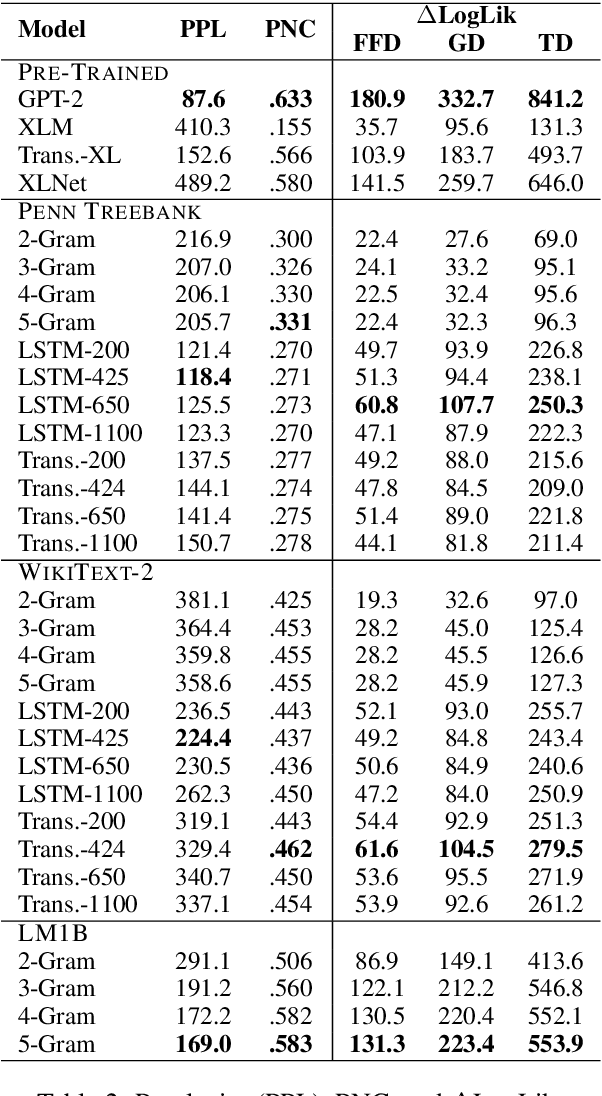
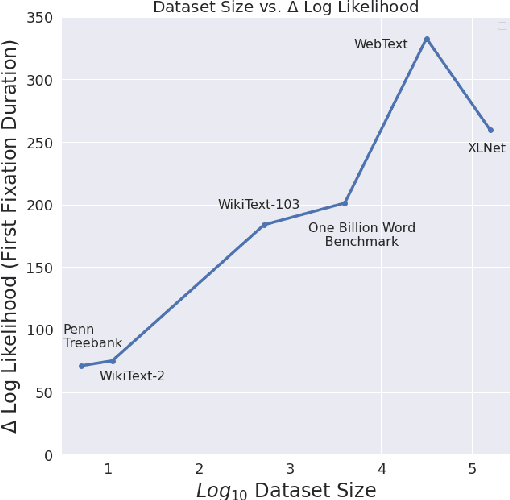
By positing a relationship between naturalistic reading times and information-theoretic surprisal, surprisal theory (Hale, 2001; Levy, 2008) provides a natural interface between language models and psycholinguistic models. This paper re-evaluates a claim due to Goodkind and Bicknell (2018) that a language model's ability to model reading times is a linear function of its perplexity. By extending Goodkind and Bicknell's analysis to modern neural architectures, we show that the proposed relation does not always hold for Long Short-Term Memory networks, Transformers, and pre-trained models. We introduce an alternate measure of language modeling performance called predictability norm correlation based on Cloze probabilities measured from human subjects. Our new metric yields a more robust relationship between language model quality and psycholinguistic modeling performance that allows for comparison between models with different training configurations.
Finding Syntactic Representations in Neural Stacks
Jun 04, 2019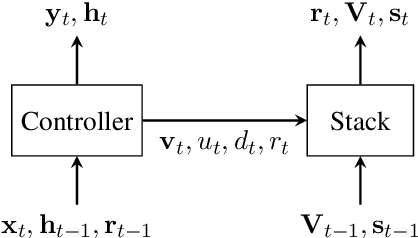
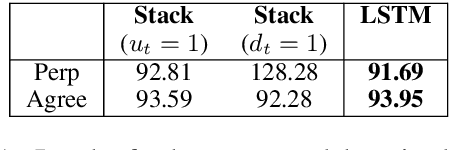
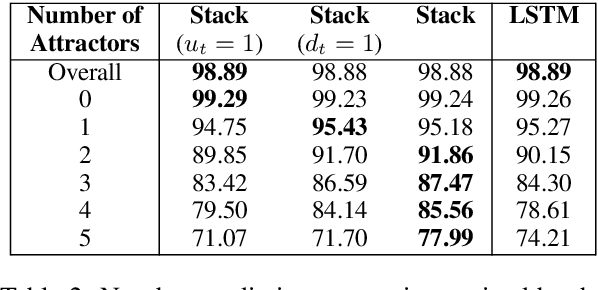
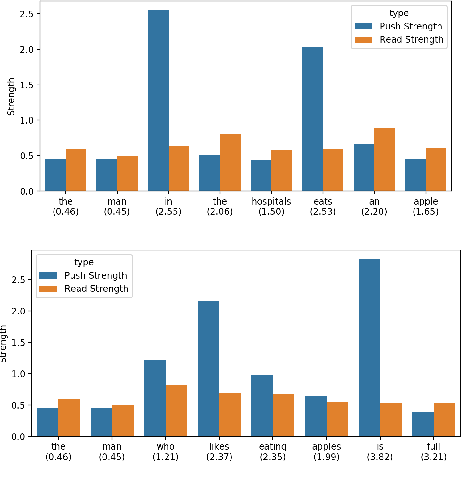
Neural network architectures have been augmented with differentiable stacks in order to introduce a bias toward learning hierarchy-sensitive regularities. It has, however, proven difficult to assess the degree to which such a bias is effective, as the operation of the differentiable stack is not always interpretable. In this paper, we attempt to detect the presence of latent representations of hierarchical structure through an exploration of the unsupervised learning of constituency structure. Using a technique due to Shen et al. (2018a,b), we extract syntactic trees from the pushing behavior of stack RNNs trained on language modeling and classification objectives. We find that our models produce parses that reflect natural language syntactic constituencies, demonstrating that stack RNNs do indeed infer linguistically relevant hierarchical structure.
Context-Free Transductions with Neural Stacks
Sep 08, 2018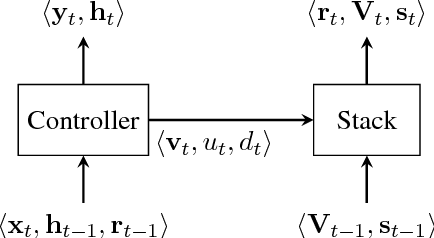
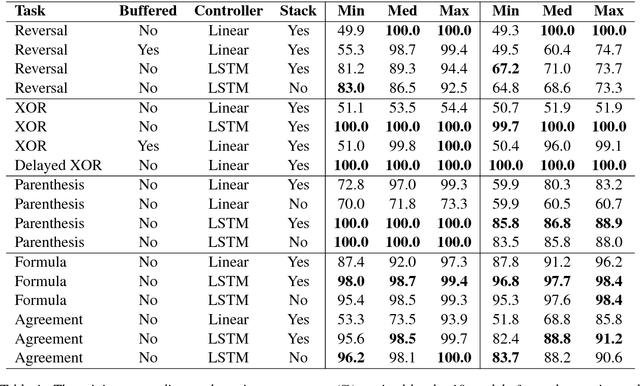
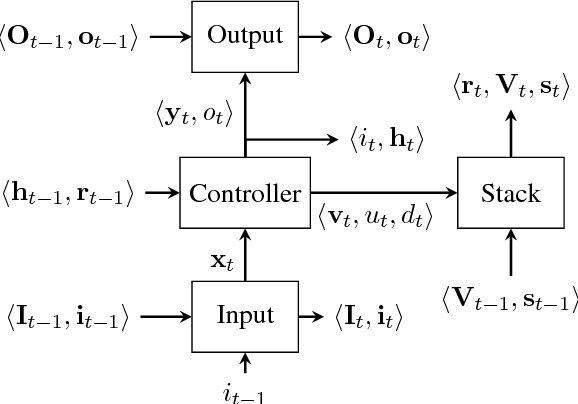
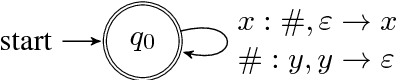
This paper analyzes the behavior of stack-augmented recurrent neural network (RNN) models. Due to the architectural similarity between stack RNNs and pushdown transducers, we train stack RNN models on a number of tasks, including string reversal, context-free language modelling, and cumulative XOR evaluation. Examining the behavior of our networks, we show that stack-augmented RNNs can discover intuitive stack-based strategies for solving our tasks. However, stack RNNs are more difficult to train than classical architectures such as LSTMs. Rather than employ stack-based strategies, more complex networks often find approximate solutions by using the stack as unstructured memory.