 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation and Hyperparameter Tuning for Low-Resource MFA
Apr 09, 2025A continued issue for those working with computational tools and endangered and under-resourced languages is the lower accuracy of results for languages with smaller amounts of data. We attempt to ameliorate this issue by using data augmentation methods to increase corpus size, comparing augmentation to hyperparameter tuning for multilingual forced alignment. Unlike text augmentation methods, audio augmentation does not lead to substantially increased performance. Hyperparameter tuning, on the other hand, results in substantial improvement without (for this amount of data) infeasible additional training time. For languages with small to medium amounts of training data, this is a workable alternative to adapting models from high-resource languages.
Multilingual MFA: Forced Alignment on Low-Resource Related Languages
Apr 09, 2025



We compare the outcomes of multilingual and crosslingual training for related and unrelated Australian languages with similar phonological inventories. We use the Montreal Forced Aligner to train acoustic models from scratch and adapt a large English model, evaluating results against seen data, unseen data (seen language), and unseen data and language. Results indicate benefits of adapting the English baseline model for previously unseen languages.
Topic Modeling in the Voynich Manuscript
Jul 06, 2021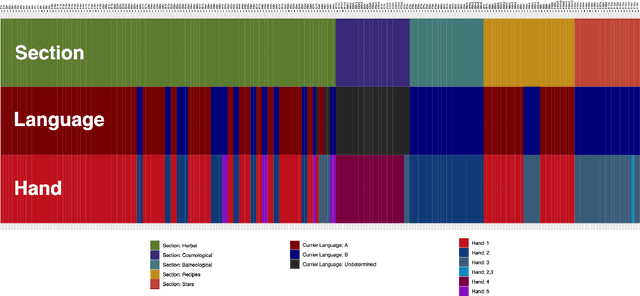
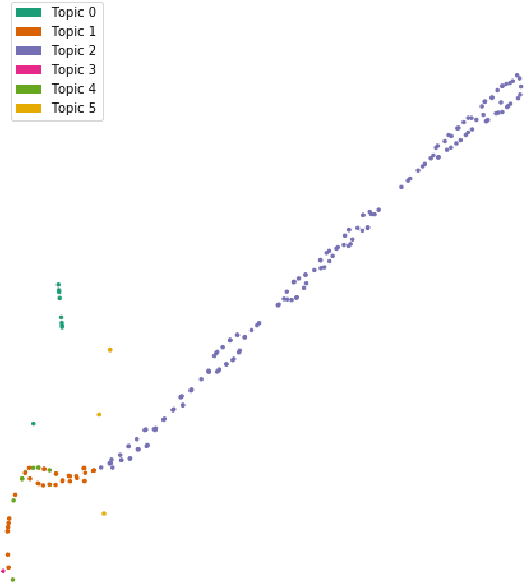
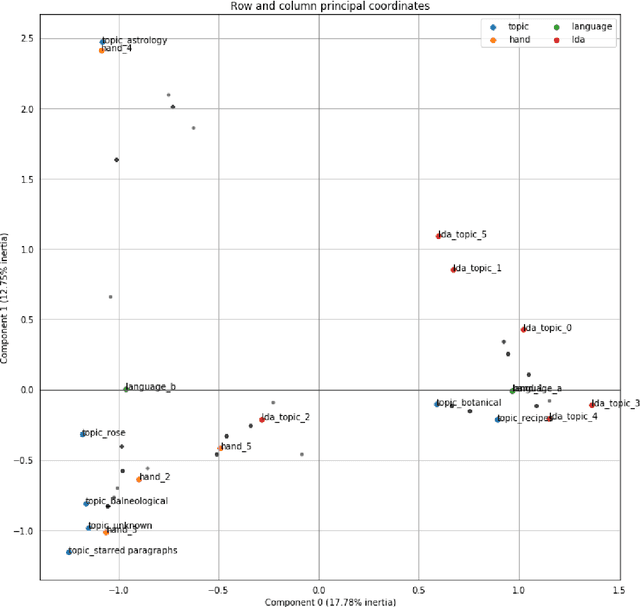
This article presents the results of investigations using topic modeling of the Voynich Manuscript (Beinecke MS408). Topic modeling is a set of computational methods which are used to identify clusters of subjects within text. We use latent dirichlet allocation, latent semantic analysis, and nonnegative matrix factorization to cluster Voynich pages into `topics'. We then compare the topics derived from the computational models to clusters derived from the Voynich illustrations and from paleographic analysis. We find that computationally derived clusters match closely to a conjunction of scribe and subject matter (as per the illustrations), providing further evidence that the Voynich Manuscript contains meaningful text.
Character Entropy in Modern and Historical Texts: Comparison Metrics for an Undeciphered Manuscript
Oct 28, 2020
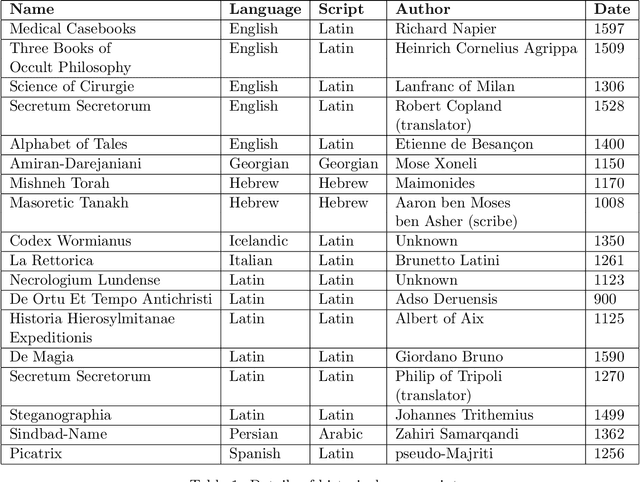

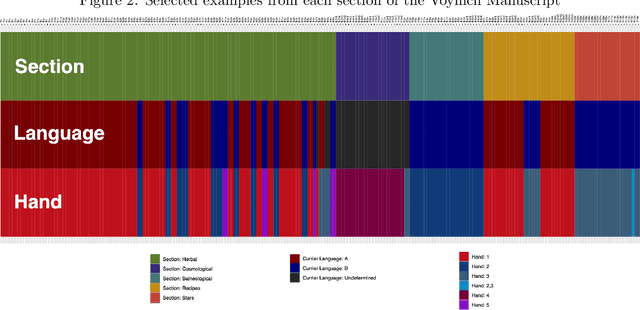
This paper outlines the creation of three corpora for multilingual comparison and analysis of the Voynich manuscript: a corpus of Voynich texts partitioned by Currier language, scribal hand, and transcription system, a corpus of 294 language samples compiled from Wikipedia, and a corpus of eighteen transcribed historical texts in eight languages. These corpora will be utilized in subsequent work by the Voynich Working Group at Yale University. We demonstrate the utility of these corpora for studying characteristics of the Voynich script and language, with an analysis of conditional character entropy in Voynichese. We discuss the interaction between character entropy and language, script size and type, glyph compositionality, scribal conventions and abbreviations, positional character variants, and bigram frequency. This analysis characterizes the interaction between script compositionality, character size, and predictability. We show that substantial manipulations of glyph composition are not sufficient to align conditional entropy levels with natural languages. The unusually predictable nature of the Voynichese script is not attributable to a particular script or transcription system, underlying language, or substitution cipher. Voynichese is distinct from every comparison text in our corpora because character placement is highly constrained within the word, and this may indicate the loss of phonemic distinctions from the underlying language.
Phylogenetic signal in phonotactics
Feb 03, 2020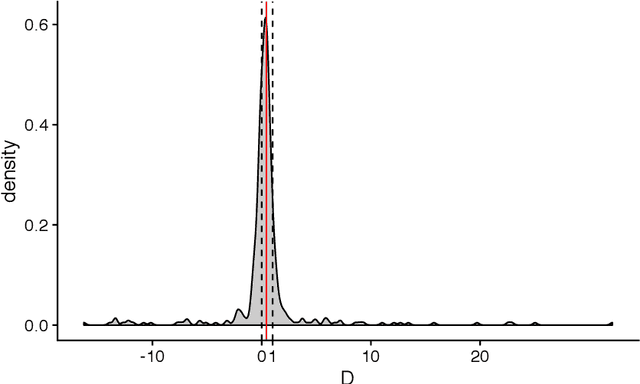

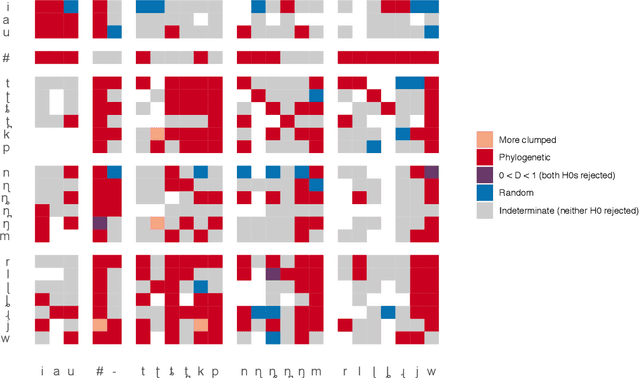
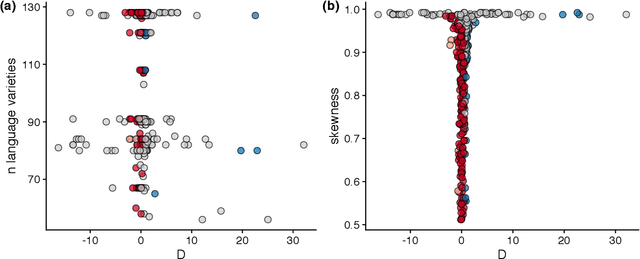
Phylogenetic methods have broad potential in linguistics beyond tree inference. Here, we show how a phylogenetic approach opens the possibility of gaining historical insights from entirely new kinds of linguistic data--in this instance, statistical phonotactics. We extract phonotactic data from 128 Pama-Nyungan vocabularies and apply tests for phylogenetic signal, quantifying the degree to which the data reflect phylogenetic history. We test three datasets: (1) binary variables recording the presence or absence of biphones (two-segment sequences) in a lexicon (2) frequencies of transitions between segments, and (3) frequencies of transitions between natural sound classes. Australian languages have been characterised as having a high degree of phonotactic homogeneity. Nevertheless, we detect phylogenetic signal in all datasets. Phylogenetic signal is higher in finer-grained frequency data than in binary data, and highest in natural-class-based data. These results demonstrate the viability of employing a new source of readily extractable data in historical and comparative linguistics.
Semantic Change and Semantic Stability: Variation is Key
Jun 13, 2019

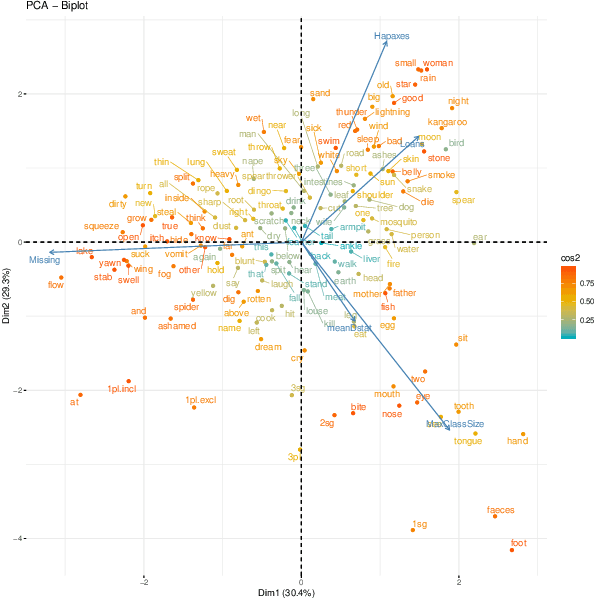
I survey some recent approaches to studying change in the lexicon, particularly change in meaning across phylogenies. I briefly sketch an evolutionary approach to language change and point out some issues in recent approaches to studying semantic change that rely on temporally stratified word embeddings. I draw illustrations from lexical cognate models in Pama-Nyungan to identify meaning classes most appropriate for lexical phylogenetic inference, particularly highlighting the importance of variation in studying change over time.