 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Entropy in Modern and Historical Texts: Comparison Metrics for an Undeciphered Manuscript
Paper and Code

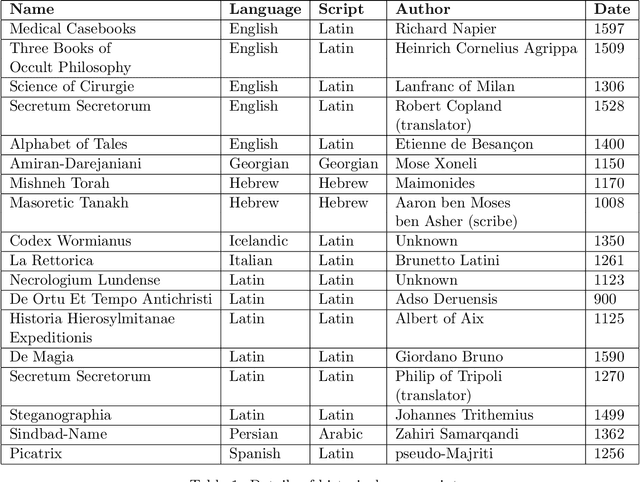

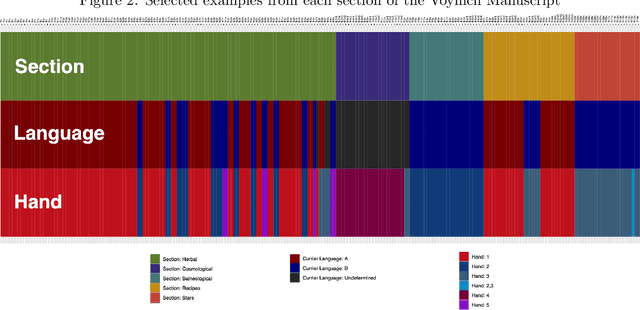
This paper outlines the creation of three corpora for multilingual comparison and analysis of the Voynich manuscript: a corpus of Voynich texts partitioned by Currier language, scribal hand, and transcription system, a corpus of 294 language samples compiled from Wikipedia, and a corpus of eighteen transcribed historical texts in eight languages. These corpora will be utilized in subsequent work by the Voynich Working Group at Yale University. We demonstrate the utility of these corpora for studying characteristics of the Voynich script and language, with an analysis of conditional character entropy in Voynichese. We discuss the interaction between character entropy and language, script size and type, glyph compositionality, scribal conventions and abbreviations, positional character variants, and bigram frequency. This analysis characterizes the interaction between script compositionality, character size, and predictability. We show that substantial manipulations of glyph composition are not sufficient to align conditional entropy levels with natural languages. The unusually predictable nature of the Voynichese script is not attributable to a particular script or transcription system, underlying language, or substitution cipher. Voynichese is distinct from every comparison text in our corpora because character placement is highly constrained within the word, and this may indicate the loss of phonemic distinctions from the underlying language.