 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLAS: An Exploration and Assessment of the Deep Learning Acceleration Stack
Nov 15, 2023



Deep Neural Networks (DNNs) are extremely computationally demanding, which presents a large barrier to their deployment on resource-constrained devices. Since such devices are where many emerging deep learning applications lie (e.g., drones, vision-based medical technology), significant bodies of work from both the machine learning and systems communities have attempted to provide optimizations to accelerate DNNs. To help unify these two perspectives, in this paper we combine machine learning and systems techniques within the Deep Learning Acceleration Stack (DLAS), and demonstrate how these layers can be tightly dependent on each other with an across-stack perturbation study. We evaluate the impact on accuracy and inference time when varying different parameters of DLAS across two datasets, seven popular DNN architectures, four DNN compression techniques, three algorithmic primitives with sparse and dense variants, untuned and auto-scheduled code generation, and four hardware platforms. Our evaluation highlights how perturbations across DLAS parameters can cause significant variation and across-stack interactions. The highest level observation from our evaluation is that the model size, accuracy, and inference time are not guaranteed to be correlated. Overall we make 13 key observations, including that speedups provided by compression techniques are very hardware dependent, and that compiler auto-tuning can significantly alter what the best algorithm to use for a given configuration is. With DLAS, we aim to provide a reference framework to aid machine learning and systems practitioners in reasoning about the context in which their respective DNN acceleration solutions exist in. With our evaluation strongly motivating the need for co-design, we believe that DLAS can be a valuable concept for exploring the next generation of co-designed accelerated deep learning solutions.
Neural Architecture Search as Program Transformation Exploration
Feb 12, 2021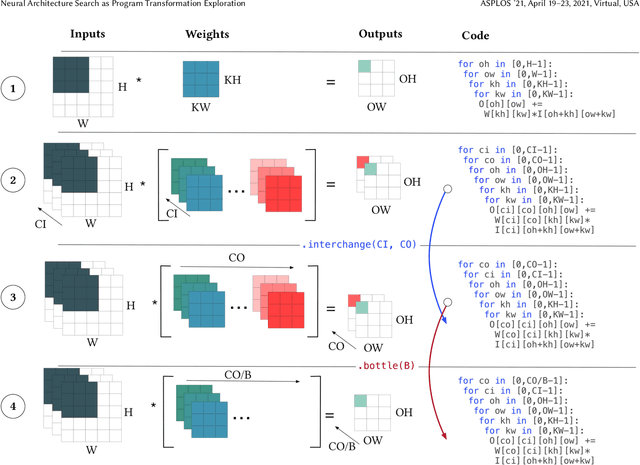

Improving the performance of deep neural networks (DNNs) is important to both the compiler and neural architecture search (NAS) communities. Compilers apply program transformations in order to exploit hardware parallelism and memory hierarchy. However, legality concerns mean they fail to exploit the natural robustness of neural networks. In contrast, NAS techniques mutate networks by operations such as the grouping or bottlenecking of convolutions, exploiting the resilience of DNNs. In this work, we express such neural architecture operations as program transformations whose legality depends on a notion of representational capacity. This allows them to be combined with existing transformations into a unified optimization framework. This unification allows us to express existing NAS operations as combinations of simpler transformations. Crucially, it allows us to generate and explore new tensor convolutions. We prototyped the combined framework in TVM and were able to find optimizations across different DNNs, that significantly reduce inference time - over 3$\times$ in the majority of cases. Furthermore, our scheme dramatically reduces NAS search time. Code is available at~\href{https://github.com/jack-willturner/nas-as-program-transformation-exploration}{this https url}.
Deep Data Flow Analysis
Nov 21, 2020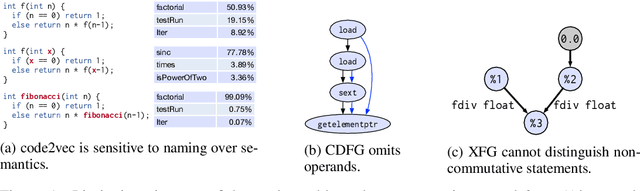

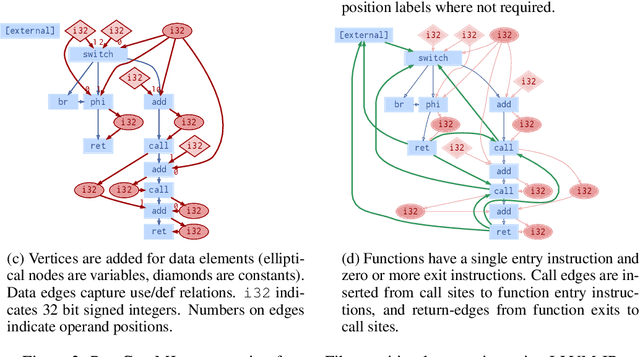
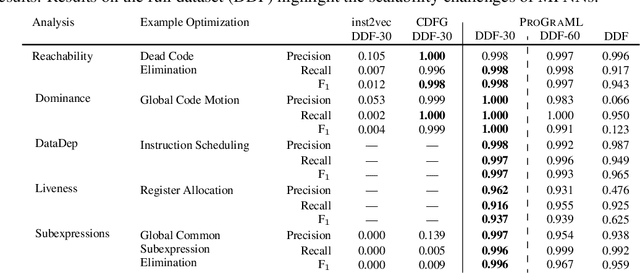
Compiler architects increasingly look to machine learning when building heuristics for compiler optimization. The promise of automatic heuristic design, freeing the compiler engineer from the complex interactions of program, architecture, and other optimizations, is alluring. However, most machine learning methods cannot replicate even the simplest of the abstract interpretations of data flow analysis that are critical to making good optimization decisions. This must change for machine learning to become the dominant technology in compiler heuristics. To this end, we propose ProGraML - Program Graphs for Machine Learning - a language-independent, portable representation of whole-program semantics for deep learning. To benchmark current and future learning techniques for compiler analyses we introduce an open dataset of 461k Intermediate Representation (IR) files for LLVM, covering five source programming languages, and 15.4M corresponding data flow results. We formulate data flow analysis as an MPNN and show that, using ProGraML, standard analyses can be learned, yielding improved performance on downstream compiler optimization tasks.
Optimizing Grouped Convolutions on Edge Devices
Jun 17, 2020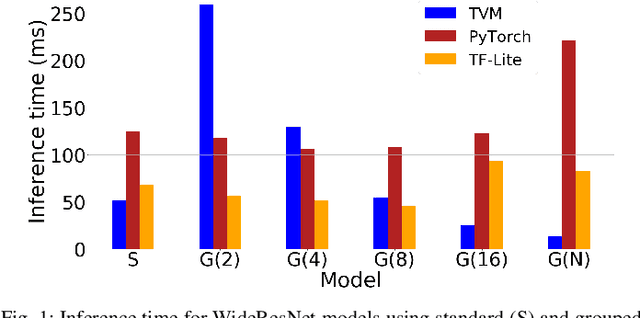
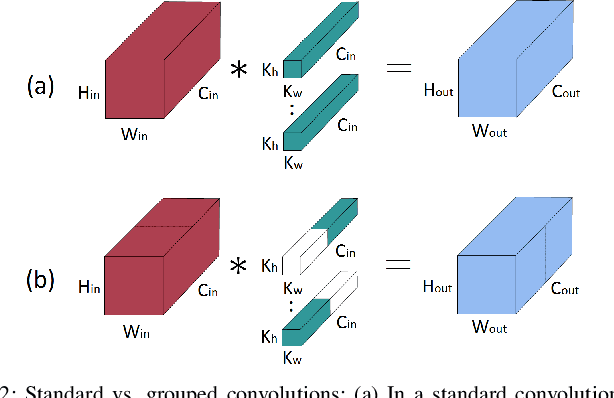
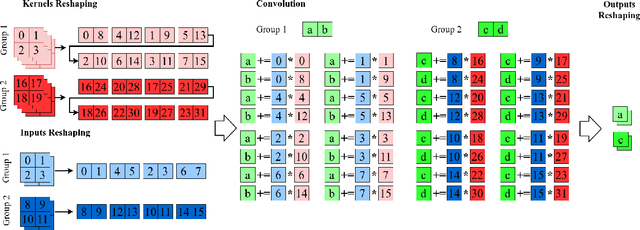
When deploying a deep neural network on constrained hardware, it is possible to replace the network's standard convolutions with grouped convolutions. This allows for substantial memory savings with minimal loss of accuracy. However, current implementations of grouped convolutions in modern deep learning frameworks are far from performing optimally in terms of speed. In this paper we propose Grouped Spatial Pack Convolutions (GSPC), a new implementation of grouped convolutions that outperforms existing solutions. We implement GSPC in TVM, which provides state-of-the-art performance on edge devices. We analyze a set of networks utilizing different types of grouped convolutions and evaluate their performance in terms of inference time on several edge devices. We observe that our new implementation scales well with the number of groups and provides the best inference times in all settings, improving the existing implementations of grouped convolutions in TVM, PyTorch and TensorFlow Lite by 3.4x, 8x and 4x on average respectively. Code is available at https://github.com/gecLAB/tvm-GSPC/
Performance Aware Convolutional Neural Network Channel Pruning for Embedded GPUs
Feb 20, 2020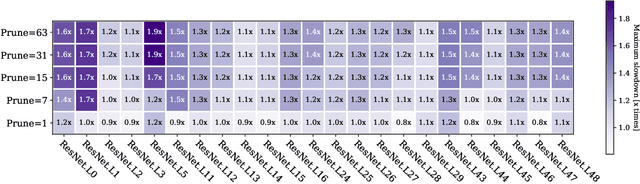

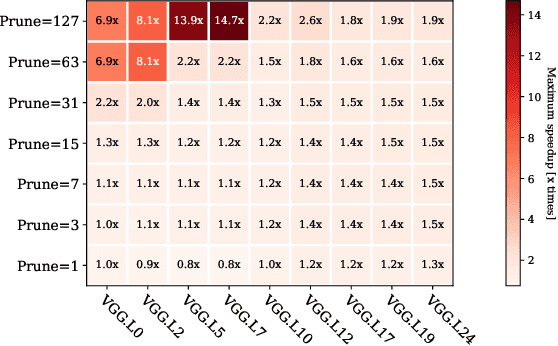

Convolutional Neural Networks (CNN) are becoming a common presence in many applications and services, due to their superior recognition accuracy. They are increasingly being used on mobile devices, many times just by porting large models designed for server space, although several model compression techniques have been considered. One model compression technique intended to reduce computations is channel pruning. Mobile and embedded systems now have GPUs which are ideal for the parallel computations of neural networks and for their lower energy cost per operation. Specialized libraries perform these neural network computations through highly optimized routines. As we find in our experiments, these libraries are optimized for the most common network shapes, making uninstructed channel pruning inefficient. We evaluate higher level libraries, which analyze the input characteristics of a convolutional layer, based on which they produce optimized OpenCL (Arm Compute Library and TVM) and CUDA (cuDNN) code. However, in reality, these characteristics and subsequent choices intended for optimization can have the opposite effect. We show that a reduction in the number of convolutional channels, pruning 12% of the initial size, is in some cases detrimental to performance, leading to 2x slowdown. On the other hand, we also find examples where performance-aware pruning achieves the intended results, with performance speedups of 3x with cuDNN and above 10x with Arm Compute Library and TVM. Our findings expose the need for hardware-instructed neural network pruning.
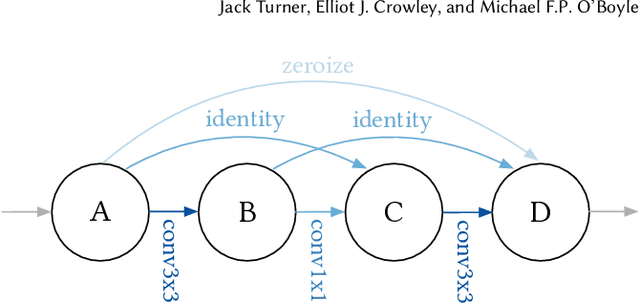
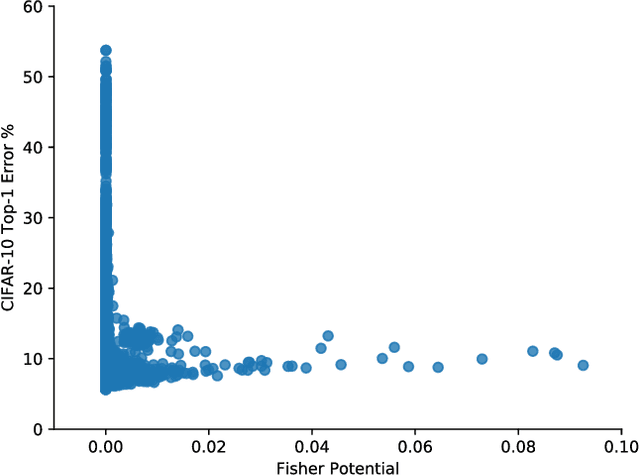
BlockSwap: Fisher-guided Block Substitution for Network Compression
Jun 10, 2019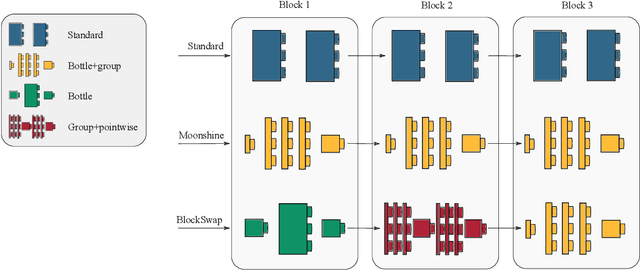

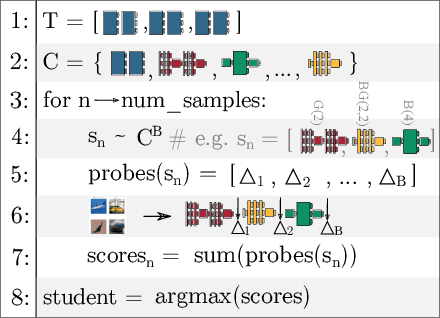
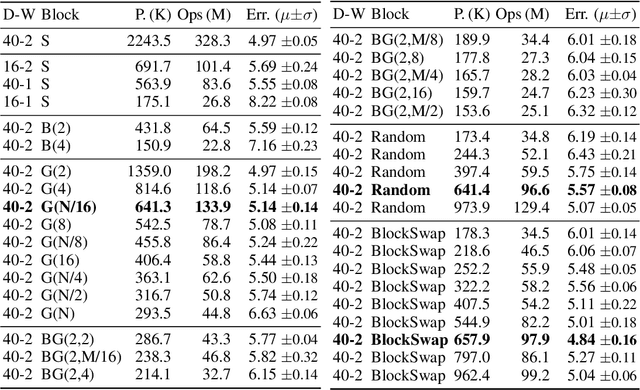
The desire to run neural networks on low-capacity edge devices has led to the development of a wealth of compression techniques. Moonshine is a simple and powerful example of this: one takes a large pre-trained network and substitutes each of its convolutional blocks with a selected cheap alternative block, then distills the resultant network with the original. However, not all blocks are created equally; for a required parameter budget there may exist a potent combination of many different cheap blocks. In this work, we find these by developing BlockSwap: an algorithm for choosing networks with interleaved block types by passing a single minibatch of training data through randomly initialised networks and gauging their Fisher potential. We show that block-wise cheapening yields more accurate networks than single block-type networks across a spectrum of parameter budgets. Code is available at https://github.com/BayesWatch/pytorch-blockswap.
HAKD: Hardware Aware Knowledge Distillation
Oct 24, 2018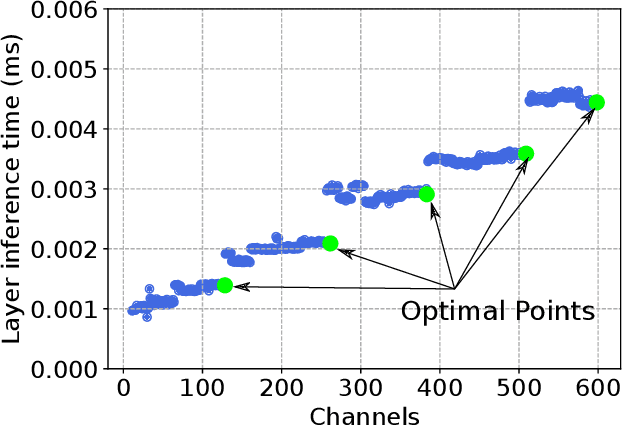

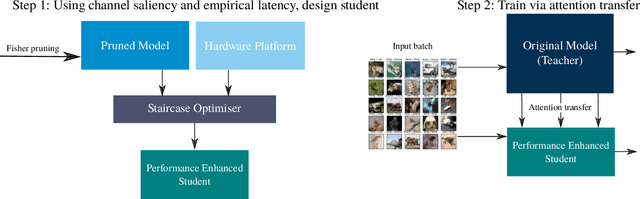
Despite recent developments, deploying deep neural networks on resource constrained general purpose hardware remains a significant challenge. There has been much work in developing methods for reshaping neural networks, usually with a focus on minimising total parameter count. These methods are typically developed in a hardware-agnostic manner and do not exploit hardware behaviour. In this paper we propose a new approach, Hardware Aware Knowledge Distillation (HAKD) which uses empirical observations of hardware behaviour to design efficient student networks which are then trained with knowledge distillation. This allows the trade-off between accuracy and performance to be managed explicitly. We have applied this approach across three platforms and evaluated it on two networks, MobileNet and DenseNet, on CIFAR-10. We show that HAKD outperforms Deep Compression and Fisher pruning in terms of size, accuracy and performance.
Pruning neural networks: is it time to nip it in the bud?
Oct 10, 2018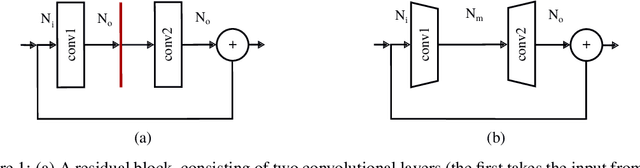
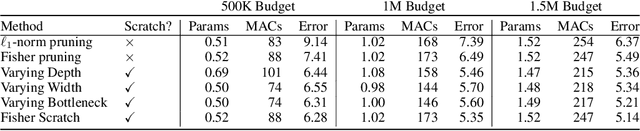
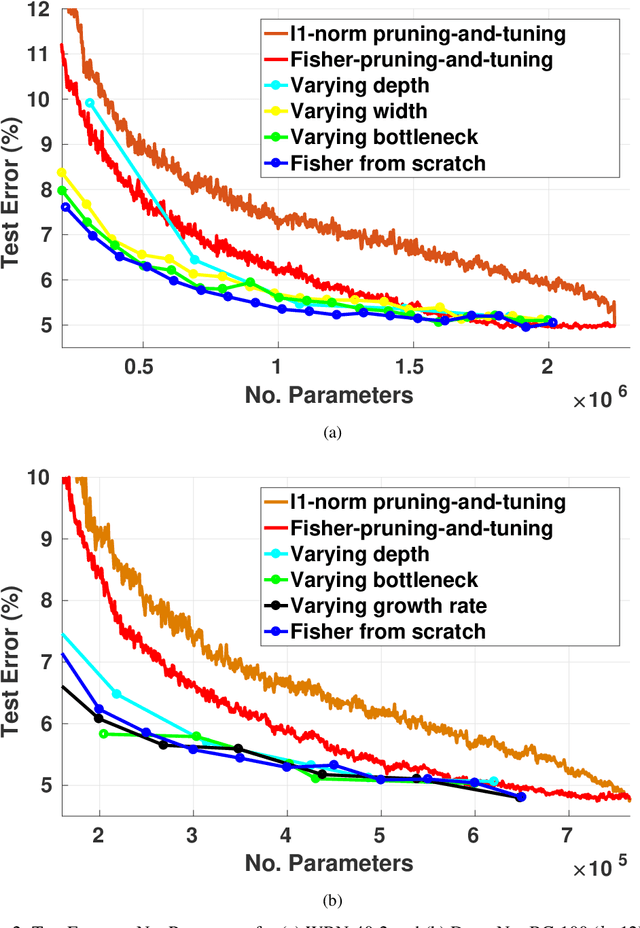
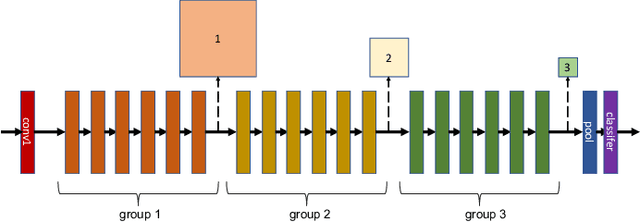
Pruning is a popular technique for compressing a neural network: a large pre-trained network is fine-tuned while connections are successively removed. However, the value of pruning has largely evaded scrutiny. In this extended abstract, we examine residual networks obtained through Fisher-pruning and make two interesting observations. First, when time-constrained, it is better to train a simple, smaller network from scratch than prune a large network. Second, it is the architectures obtained through the pruning process --- not the learnt weights ---that prove valuable. Such architectures are powerful when trained from scratch. Furthermore, these architectures are easy to approximate without any further pruning: we can prune once and obtain a family of new, scalable network architectures for different memory requirements.
Characterising Across-Stack Optimisations for Deep Convolutional Neural Networks
Sep 19, 2018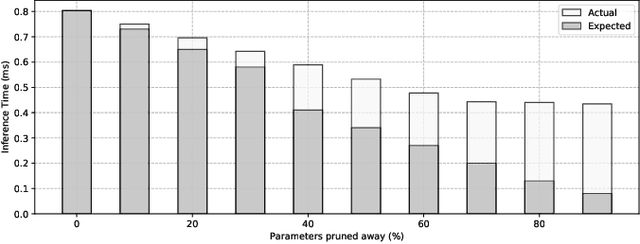

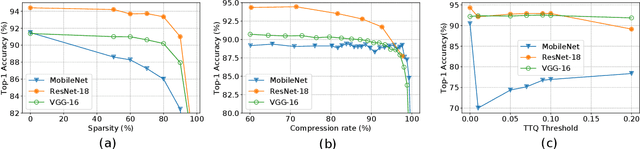

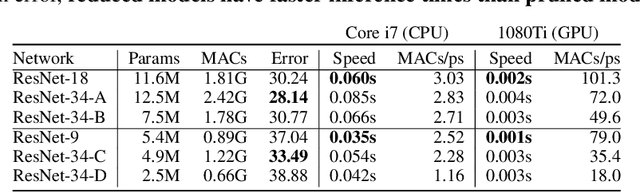
Convolutional Neural Networks (CNNs) are extremely computationally demanding, presenting a large barrier to their deployment on resource-constrained devices. Since such systems are where some of their most useful applications lie (e.g. obstacle detection for mobile robots, vision-based medical assistive technology), significant bodies of work from both machine learning and systems communities have attempted to provide optimisations that will make CNNs available to edge devices. In this paper we unify the two viewpoints in a Deep Learning Inference Stack and take an across-stack approach by implementing and evaluating the most common neural network compression techniques (weight pruning, channel pruning, and quantisation) and optimising their parallel execution with a range of programming approaches (OpenMP, OpenCL) and hardware architectures (CPU, GPU). We provide comprehensive Pareto curves to instruct trade-offs under constraints of accuracy, execution time, and memory space.
SLAMBench2: Multi-Objective Head-to-Head Benchmarking for Visual SLAM
Aug 21, 2018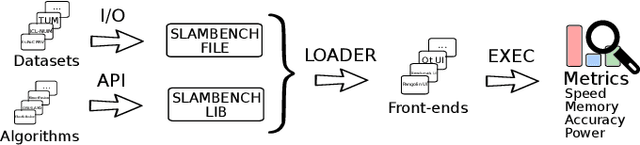


SLAM is becoming a key component of robotics and augmented reality (AR) systems. While a large number of SLAM algorithms have been presented, there has been little effort to unify the interface of such algorithms, or to perform a holistic comparison of their capabilities. This is a problem since different SLAM applications can have different functional and non-functional requirements. For example, a mobile phonebased AR application has a tight energy budget, while a UAV navigation system usually requires high accuracy. SLAMBench2 is a benchmarking framework to evaluate existing and future SLAM systems, both open and close source, over an extensible list of datasets, while using a comparable and clearly specified list of performance metrics. A wide variety of existing SLAM algorithms and datasets is supported, e.g. ElasticFusion, InfiniTAM, ORB-SLAM2, OKVIS, and integrating new ones is straightforward and clearly specified by the framework. SLAMBench2 is a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs across SLAM systems.