 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockSwap: Fisher-guided Block Substitution for Network Compression
Jun 10, 2019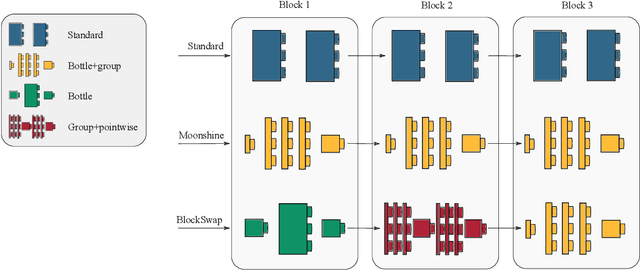

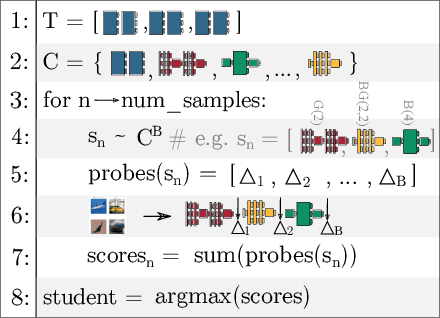
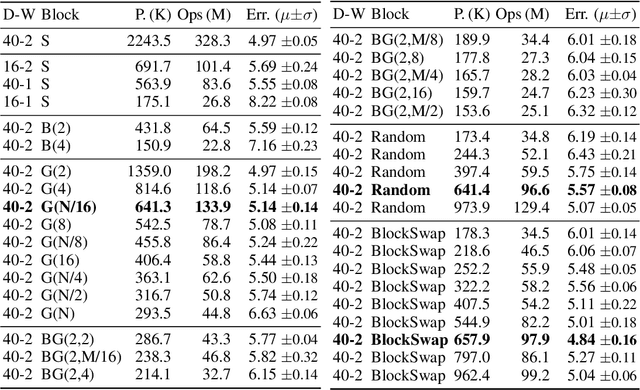
The desire to run neural networks on low-capacity edge devices has led to the development of a wealth of compression techniques. Moonshine is a simple and powerful example of this: one takes a large pre-trained network and substitutes each of its convolutional blocks with a selected cheap alternative block, then distills the resultant network with the original. However, not all blocks are created equally; for a required parameter budget there may exist a potent combination of many different cheap blocks. In this work, we find these by developing BlockSwap: an algorithm for choosing networks with interleaved block types by passing a single minibatch of training data through randomly initialised networks and gauging their Fisher potential. We show that block-wise cheapening yields more accurate networks than single block-type networks across a spectrum of parameter budgets. Code is available at https://github.com/BayesWatch/pytorch-blockswap.
Separable Layers Enable Structured Efficient Linear Substitutions
Jun 03, 2019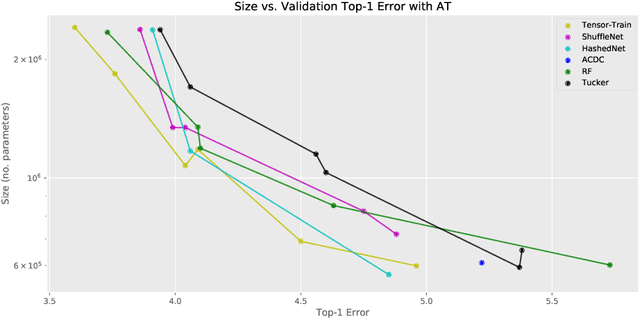
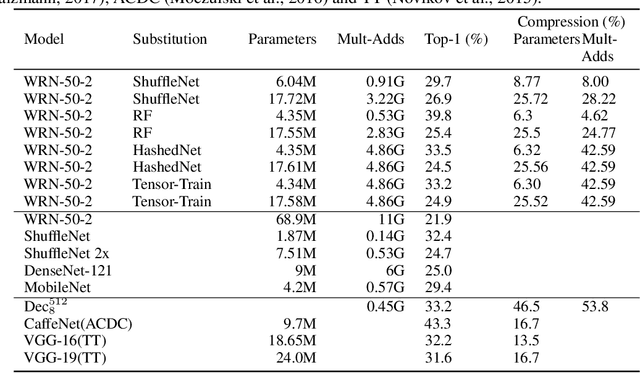
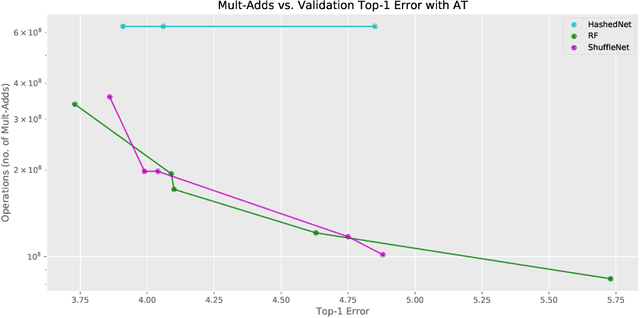
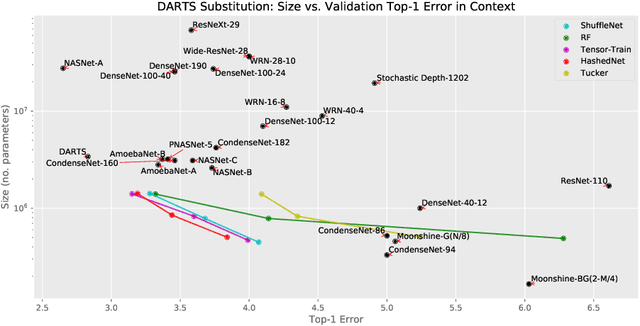
In response to the development of recent efficient dense layers, this paper shows that something as simple as replacing linear components in pointwise convolutions with structured linear decompositions also produces substantial gains in the efficiency/accuracy tradeoff. Pointwise convolutions are fully connected layers and are thus prepared for replacement by structured transforms. Networks using such layers are able to learn the same tasks as those using standard convolutions, and provide Pareto-optimal benefits in efficiency/accuracy, both in terms of computation (mult-adds) and parameter count (and hence memory). Code is available at https://github.com/BayesWatch/deficient-efficient.
Moonshine: Distilling with Cheap Convolutions
Oct 22, 2018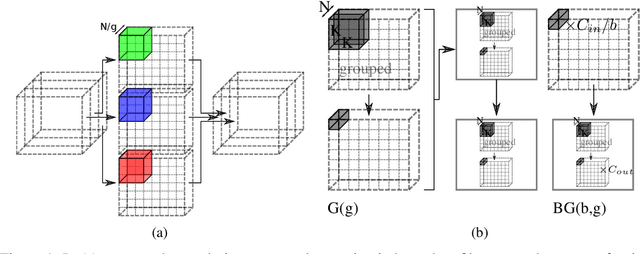


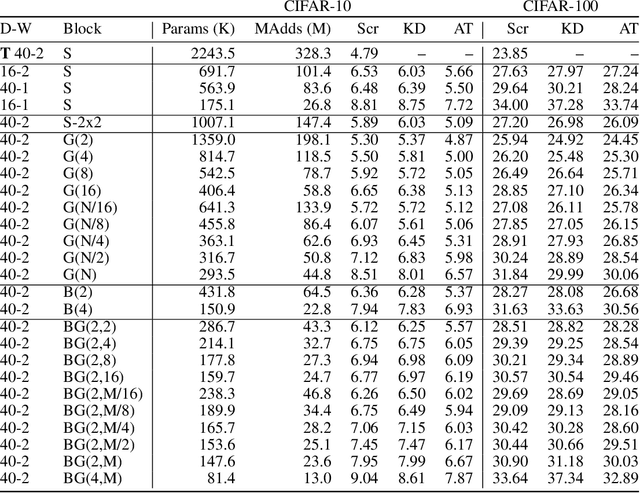
Many engineers wish to deploy modern neural networks in memory-limited settings; but the development of flexible methods for reducing memory use is in its infancy, and there is little knowledge of the resulting cost-benefit. We propose structural model distillation for memory reduction using a strategy that produces a student architecture that is a simple transformation of the teacher architecture: no redesign is needed, and the same hyperparameters can be used. Using attention transfer, we provide Pareto curves/tables for distillation of residual networks with four benchmark datasets, indicating the memory versus accuracy payoff. We show that substantial memory savings are possible with very little loss of accuracy, and confirm that distillation provides student network performance that is better than training that student architecture directly on data.