 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiRID-ICU-Benchmark -- A Comprehensive Machine Learning Benchmark on High-resolution ICU Data
Nov 18, 2021
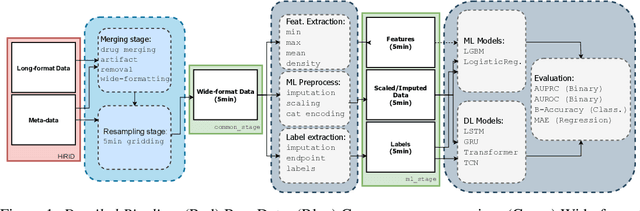
The recent success of machine learning methods applied to time series collected from Intensive Care Units (ICU) exposes the lack of standardized machine learning benchmarks for developing and comparing such methods. While raw datasets, such as MIMIC-IV or eICU, can be freely accessed on Physionet, the choice of tasks and pre-processing is often chosen ad-hoc for each publication, limiting comparability across publications. In this work, we aim to improve this situation by providing a benchmark covering a large spectrum of ICU-related tasks. Using the HiRID dataset, we define multiple clinically relevant tasks developed in collaboration with clinicians. In addition, we provide a reproducible end-to-end pipeline to construct both data and labels. Finally, we provide an in-depth analysis of current state-of-the-art sequence modeling methods, highlighting some limitations of deep learning approaches for this type of data. With this benchmark, we hope to give the research community the possibility of a fair comparison of their work.
Neighborhood Contrastive Learning Applied to Online Patient Monitoring
Jun 09, 2021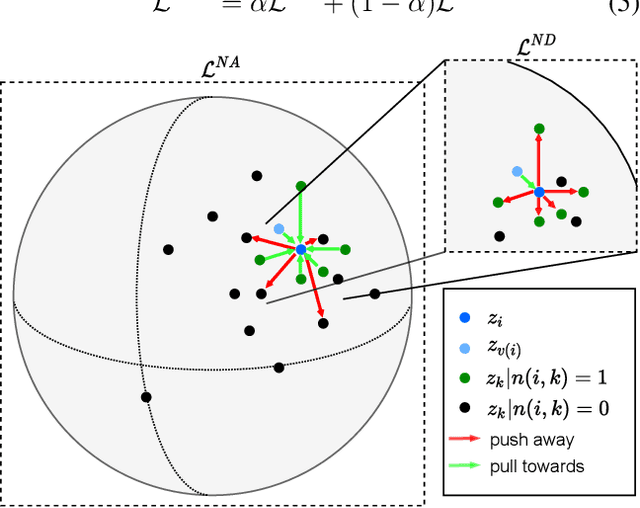
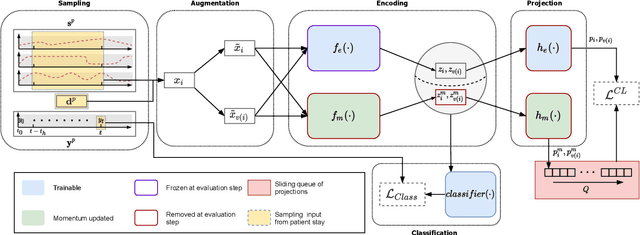
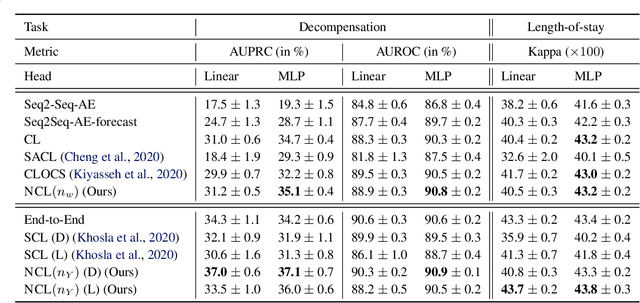
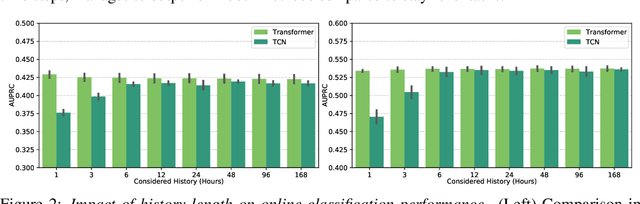
Intensive care units (ICU) are increasingly looking towards machine learning for methods to provide online monitoring of critically ill patients. In machine learning, online monitoring is often formulated as a supervised learning problem. Recently, contrastive learning approaches have demonstrated promising improvements over competitive supervised benchmarks. These methods rely on well-understood data augmentation techniques developed for image data which do not apply to online monitoring. In this work, we overcome this limitation by supplementing time-series data augmentation techniques with a novel contrastive learning objective which we call neighborhood contrastive learning (NCL). Our objective explicitly groups together contiguous time segments from each patient while maintaining state-specific information. Our experiments demonstrate a marked improvement over existing work applying contrastive methods to medical time-series.
Early prediction of respiratory failure in the intensive care unit
May 12, 2021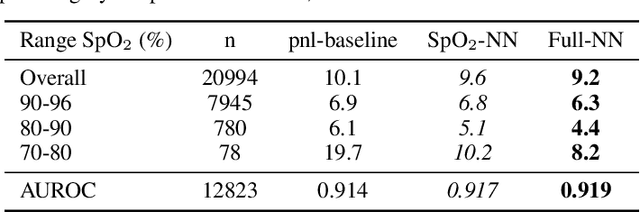
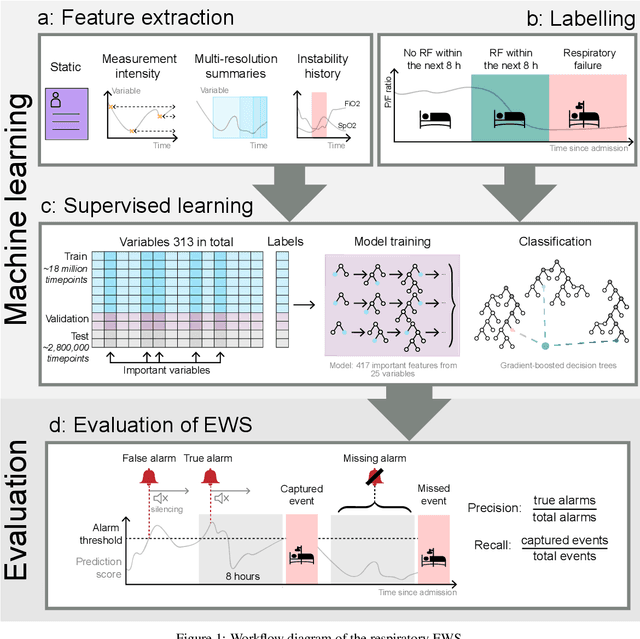
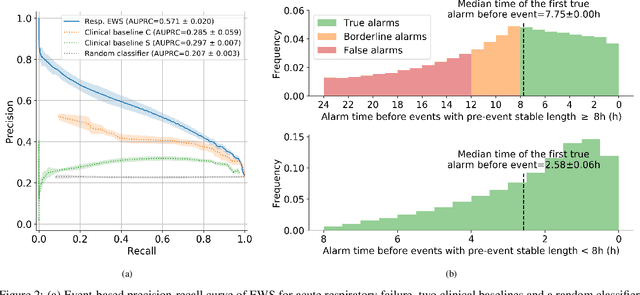
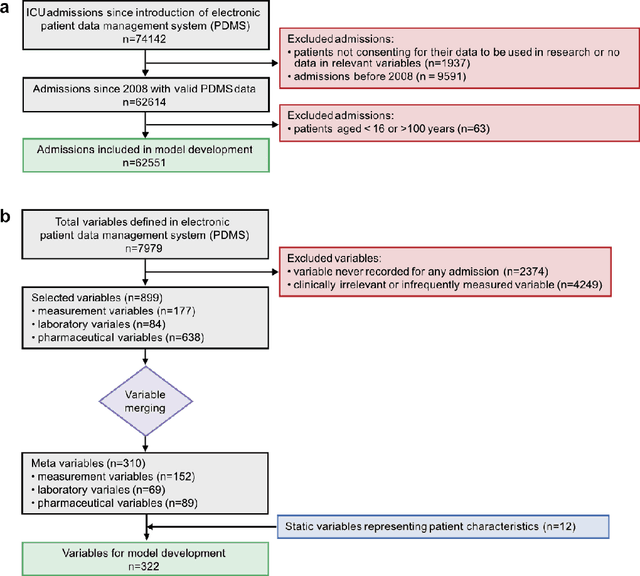
The development of respiratory failure is common among patients in intensive care units (ICU). Large data quantities from ICU patient monitoring systems make timely and comprehensive analysis by clinicians difficult but are ideal for automatic processing by machine learning algorithms. Early prediction of respiratory system failure could alert clinicians to patients at risk of respiratory failure and allow for early patient reassessment and treatment adjustment. We propose an early warning system that predicts moderate/severe respiratory failure up to 8 hours in advance. Our system was trained on HiRID-II, a data-set containing more than 60,000 admissions to a tertiary care ICU. An alarm is typically triggered several hours before the beginning of respiratory failure. Our system outperforms a clinical baseline mimicking traditional clinical decision-making based on pulse-oximetric oxygen saturation and the fraction of inspired oxygen. To provide model introspection and diagnostics, we developed an easy-to-use web browser-based system to explore model input data and predictions visually.
WRSE -- a non-parametric weighted-resolution ensemble for predicting individual survival distributions in the ICU
Nov 02, 2020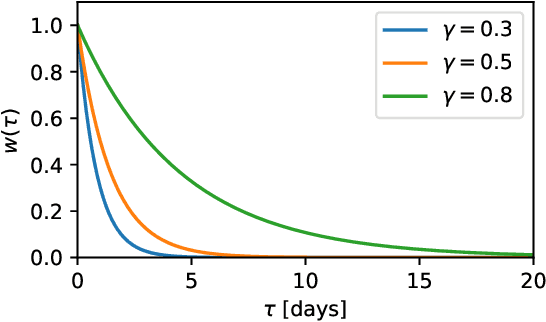

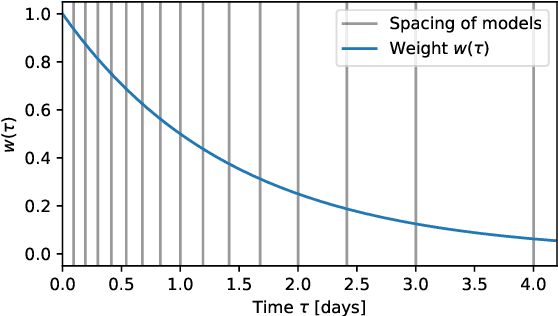

Dynamic assessment of mortality risk in the intensive care unit (ICU) can be used to stratify patients, inform about treatment effectiveness or serve as part of an early-warning system. Static risk scoring systems, such as APACHE or SAPS, have recently been supplemented with data-driven approaches that track the dynamic mortality risk over time. Recent works have focused on enhancing the information delivered to clinicians even further by producing full survival distributions instead of point predictions or fixed horizon risks. In this work, we propose a non-parametric ensemble model, Weighted Resolution Survival Ensemble (WRSE), tailored to estimate such dynamic individual survival distributions. Inspired by the simplicity and robustness of ensemble methods, the proposed approach combines a set of binary classifiers spaced according to a decay function reflecting the relevance of short-term mortality predictions. Models and baselines are evaluated under weighted calibration and discrimination metrics for individual survival distributions which closely reflect the utility of a model in ICU practice. We show competitive results with state-of-the-art probabilistic models, while greatly reducing training time by factors of 2-9x.
Variational PSOM: Deep Probabilistic Clustering with Self-Organizing Maps
Oct 03, 2019


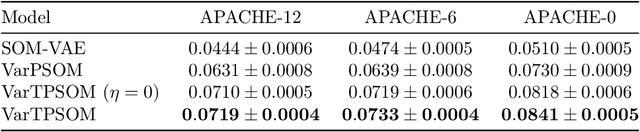
Generating visualizations and interpretations from high-dimensional data is a common problem in many fields. Two key approaches for tackling this problem are clustering and representation learning. There are very performant deep clustering models on the one hand and interpretable representation learning techniques, often relying on latent topological structures such as self-organizing maps, on the other hand. However, current methods do not yet successfully combine these two approaches. We present a new deep architecture for probabilistic clustering, VarPSOM, and its extension to time series data, VarTPSOM. We show that they achieve superior clustering performance compared to current deep clustering methods on static MNIST/Fashion-MNIST data as well as medical time series, while inducing an interpretable representation. Moreover, on the medical time series, VarTPSOM successfully predicts future trajectories in the original data space.
Machine learning for early prediction of circulatory failure in the intensive care unit
Apr 19, 2019
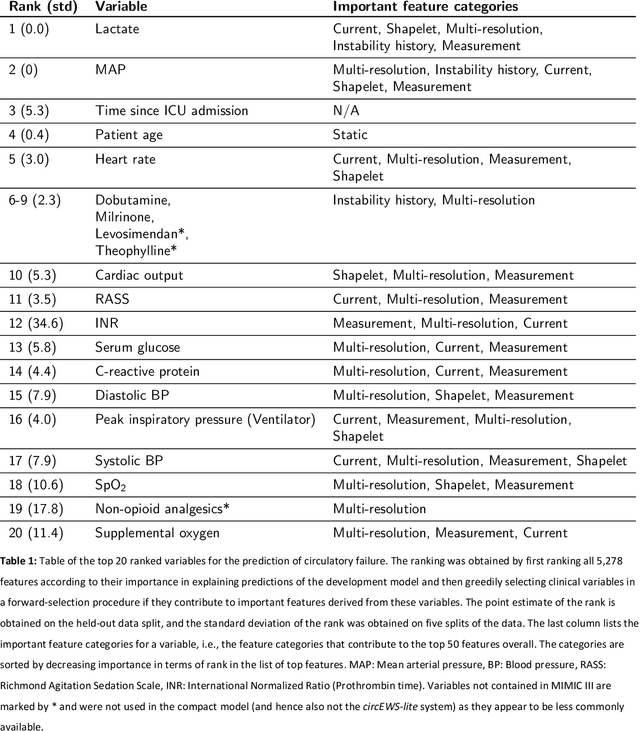

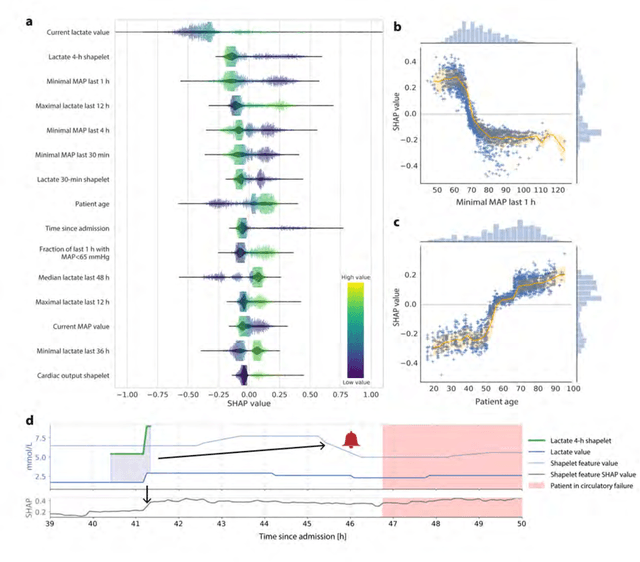
Intensive care clinicians are presented with large quantities of patient information and measurements from a multitude of monitoring systems. The limited ability of humans to process such complex information hinders physicians to readily recognize and act on early signs of patient deterioration. We used machine learning to develop an early warning system for circulatory failure based on a high-resolution ICU database with 240 patient years of data. This automatic system predicts 90.0% of circulatory failure events (prevalence 3.1%), with 81.8% identified more than two hours in advance, resulting in an area under the receiver operating characteristic curve of 94.0% and area under the precision-recall curve of 63.0%. The model was externally validated in a large independent patient cohort.
Forecasting intracranial hypertension using multi-scale waveform metrics
Feb 25, 2019



Objective: Intracranial hypertension is an important risk factor of secondary brain damage after traumatic brain injury. Hypertensive episodes are often diagnosed reactively and time is lost before counteractive measures are taken. A pro-active approach that predicts critical events ahead of time could be beneficial for the patient. Methods: We developed a prediction framework that forecasts onsets of intracranial hypertension in the next 8 hours. Its main innovation is the joint use of cerebral auto-regulation indices, spectral energies and morphological pulse metrics to describe the neurological state. One-minute base windows were compressed by computing signal metrics, and then stored in a multi-scale history, from which physiological features were derived. Results: Our model predicted intracranial hypertension up to 8 hours in advance with alarm recall rates of 90% at a precision of 36% in the MIMIC-II waveform database, improving upon two baselines from the literature. We found that features derived from high-frequency waveforms substantially improved the prediction performance over simple statistical summaries, in which each of the three feature categories contributed to the performance gain. The inclusion of long-term history up to 8 hours was especially important. Conclusion: Our approach showed promising performance and enabled us to gain insights about the critical components of prediction models for intracranial hypertension. Significance: Our results highlight the importance of information contained in high-frequency waveforms in the neurological intensive care unit. They could motivate future studies on pre-hypertensive patterns and the design of new alarm algorithms for critical events in the injured brain.
Deep Self-Organization: Interpretable Discrete Representation Learning on Time Series
Oct 05, 2018



High-dimensional time series are common in many domains. Since human cognition is not optimized to work well in high-dimensional spaces, these areas could benefit from interpretable low-dimensional representations. However, most representation learning algorithms for time series data are difficult to interpret. This is due to non-intuitive mappings from data features to salient properties of the representation and non-smoothness over time. To address this problem, we propose a new representation learning framework building on ideas from interpretable discrete dimensionality reduction and deep generative modeling. This framework allows us to learn discrete representations of time series, which give rise to smooth and interpretable embeddings with superior clustering performance. We introduce a new way to overcome the non-differentiability in discrete representation learning and present a gradient-based version of the traditional self-organizing map algorithm that is more performant than the original. Furthermore, to allow for a probabilistic interpretation of our method, we integrate a Markov model in the representation space. This model uncovers the temporal transition structure, improves clustering performance even further and provides additional explanatory insights as well as a natural representation of uncertainty. We evaluate our model in terms of clustering performance and interpretability on static (Fashion-)MNIST data, a time series of linearly interpolated (Fashion-)MNIST images, a chaotic Lorenz attractor system with two macro states, as well as on a challenging real world medical time series application on the eICU data set. Our learned representations compare favorably with competitor methods and facilitate downstream tasks on the real world data.