 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting intracranial hypertension using multi-scale waveform metrics
Feb 25, 2019



Objective: Intracranial hypertension is an important risk factor of secondary brain damage after traumatic brain injury. Hypertensive episodes are often diagnosed reactively and time is lost before counteractive measures are taken. A pro-active approach that predicts critical events ahead of time could be beneficial for the patient. Methods: We developed a prediction framework that forecasts onsets of intracranial hypertension in the next 8 hours. Its main innovation is the joint use of cerebral auto-regulation indices, spectral energies and morphological pulse metrics to describe the neurological state. One-minute base windows were compressed by computing signal metrics, and then stored in a multi-scale history, from which physiological features were derived. Results: Our model predicted intracranial hypertension up to 8 hours in advance with alarm recall rates of 90% at a precision of 36% in the MIMIC-II waveform database, improving upon two baselines from the literature. We found that features derived from high-frequency waveforms substantially improved the prediction performance over simple statistical summaries, in which each of the three feature categories contributed to the performance gain. The inclusion of long-term history up to 8 hours was especially important. Conclusion: Our approach showed promising performance and enabled us to gain insights about the critical components of prediction models for intracranial hypertension. Significance: Our results highlight the importance of information contained in high-frequency waveforms in the neurological intensive care unit. They could motivate future studies on pre-hypertensive patterns and the design of new alarm algorithms for critical events in the injured brain.
Leveraging Large Amounts of Weakly Supervised Data for Multi-Language Sentiment Classification
Mar 07, 2017
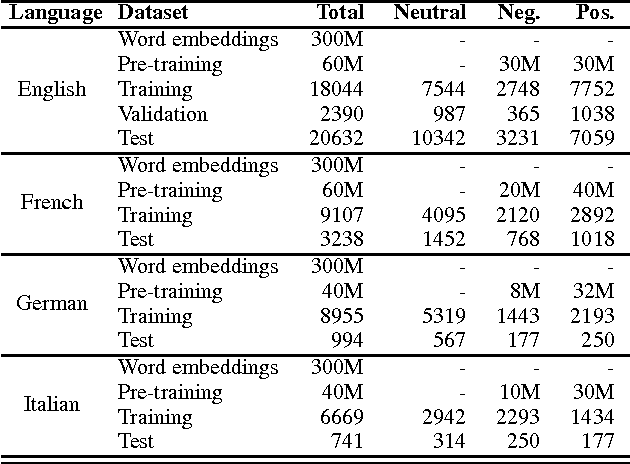

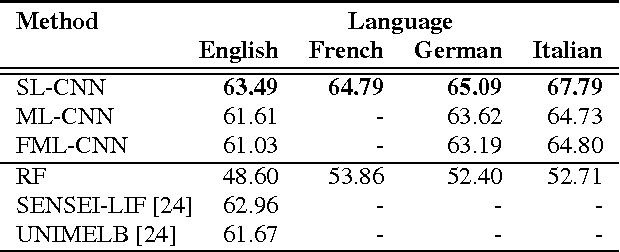
This paper presents a novel approach for multi-lingual sentiment classification in short texts. This is a challenging task as the amount of training data in languages other than English is very limited. Previously proposed multi-lingual approaches typically require to establish a correspondence to English for which powerful classifiers are already available. In contrast, our method does not require such supervision. We leverage large amounts of weakly-supervised data in various languages to train a multi-layer convolutional network and demonstrate the importance of using pre-training of such networks. We thoroughly evaluate our approach on various multi-lingual datasets, including the recent SemEval-2016 sentiment prediction benchmark (Task 4), where we achieved state-of-the-art performance. We also compare the performance of our model trained individually for each language to a variant trained for all languages at once. We show that the latter model reaches slightly worse - but still acceptable - performance when compared to the single language model, while benefiting from better generalization properties across languages.