 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable and Scalable Robot Policy Evaluation with Imperfect Simulators
Oct 05, 2025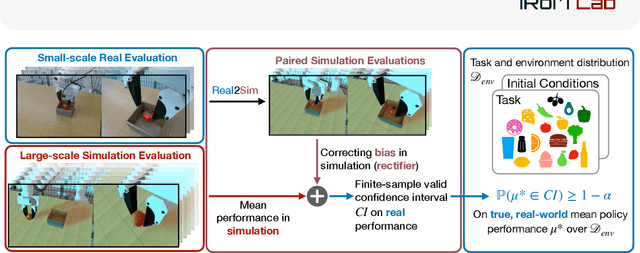



Rapid progress in imitation learning, foundation models, and large-scale datasets has led to robot manipulation policies that generalize to a wide-range of tasks and environments. However, rigorous evaluation of these policies remains a challenge. Typically in practice, robot policies are often evaluated on a small number of hardware trials without any statistical assurances. We present SureSim, a framework to augment large-scale simulation with relatively small-scale real-world testing to provide reliable inferences on the real-world performance of a policy. Our key idea is to formalize the problem of combining real and simulation evaluations as a prediction-powered inference problem, in which a small number of paired real and simulation evaluations are used to rectify bias in large-scale simulation. We then leverage non-asymptotic mean estimation algorithms to provide confidence intervals on mean policy performance. Using physics-based simulation, we evaluate both diffusion policy and multi-task fine-tuned \(\pi_0\) on a joint distribution of objects and initial conditions, and find that our approach saves over \(20-25\%\) of hardware evaluation effort to achieve similar bounds on policy performance.
An active inference model of car following: Advantages and applications
Mar 27, 2023



Driver process models play a central role in the testing, verification, and development of automated and autonomous vehicle technologies. Prior models developed from control theory and physics-based rules are limited in automated vehicle applications due to their restricted behavioral repertoire. Data-driven machine learning models are more capable than rule-based models but are limited by the need for large training datasets and their lack of interpretability, i.e., an understandable link between input data and output behaviors. We propose a novel car following modeling approach using active inference, which has comparable behavioral flexibility to data-driven models while maintaining interpretability. We assessed the proposed model, the Active Inference Driving Agent (AIDA), through a benchmark analysis against the rule-based Intelligent Driver Model, and two neural network Behavior Cloning models. The models were trained and tested on a real-world driving dataset using a consistent process. The testing results showed that the AIDA predicted driving controls significantly better than the rule-based Intelligent Driver Model and had similar accuracy to the data-driven neural network models in three out of four evaluations. Subsequent interpretability analyses illustrated that the AIDA's learned distributions were consistent with driver behavior theory and that visualizations of the distributions could be used to directly comprehend the model's decision making process and correct model errors attributable to limited training data. The results indicate that the AIDA is a promising alternative to black-box data-driven models and suggest a need for further research focused on modeling driving style and model training with more diverse datasets.
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
Dec 02, 2022



ML-based motion planning is a promising approach to produce agents that exhibit complex behaviors, and automatically adapt to novel environments. In the context of autonomous driving, it is common to treat all available training data equally. However, this approach produces agents that do not perform robustly in safety-critical settings, an issue that cannot be addressed by simply adding more data to the training set - we show that an agent trained using only a 10% subset of the data performs just as well as an agent trained on the entire dataset. We present a method to predict the inherent difficulty of a driving situation given data collected from a fleet of autonomous vehicles deployed on public roads. We then demonstrate that this difficulty score can be used in a zero-shot transfer to generate curricula for an imitation-learning based planning agent. Compared to training on the entire unbiased training dataset, we show that prioritizing difficult driving scenarios both reduces collisions by 15% and increases route adherence by 14% in closed-loop evaluation, all while using only 10% of the training data.
Neural Bridge Sampling for Evaluating Safety-Critical Autonomous Systems
Aug 24, 2020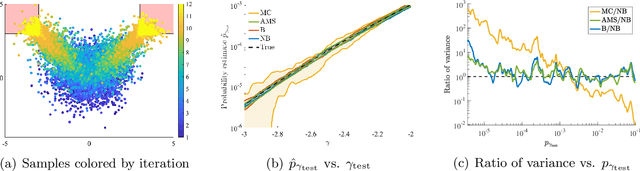
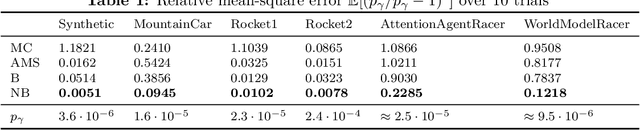
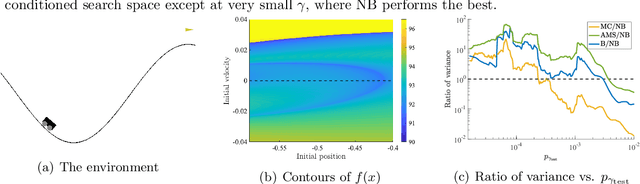
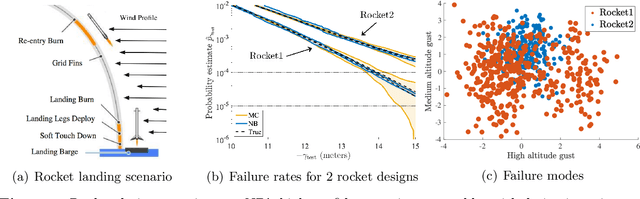
Learning-based methodologies increasingly find applications in safety-critical domains like autonomous driving and medical robotics. Due to the rare nature of dangerous events, real-world testing is prohibitively expensive and unscalable. In this work, we employ a probabilistic approach to safety evaluation in simulation, where we are concerned with computing the probability of dangerous events. We develop a novel rare-event simulation method that combines exploration, exploitation, and optimization techniques to find failure modes and estimate their rate of occurrence. We provide rigorous guarantees for the performance of our method in terms of both statistical and computational efficiency. Finally, we demonstrate the efficacy of our approach on a variety of scenarios, illustrating its usefulness as a tool for rapid sensitivity analysis and model comparison that are essential to developing and testing safety-critical autonomous systems.
FormulaZero: Distributionally Robust Online Adaptation via Offline Population Synthesis
Mar 09, 2020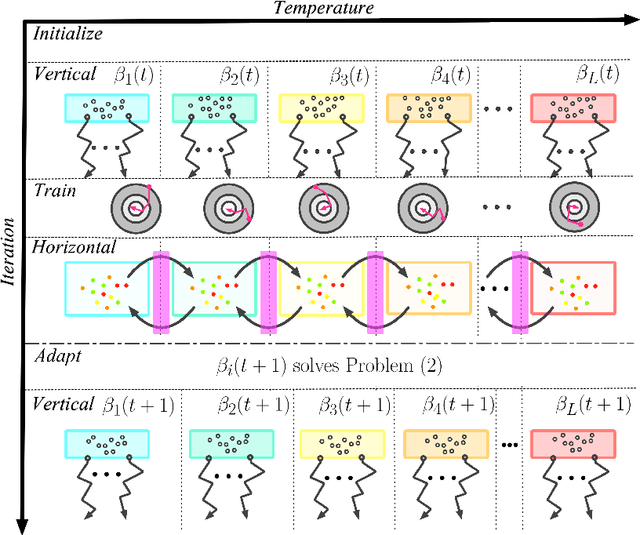
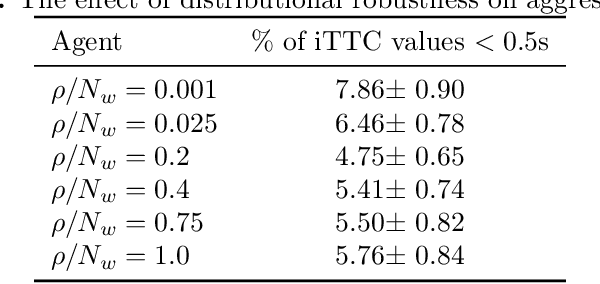

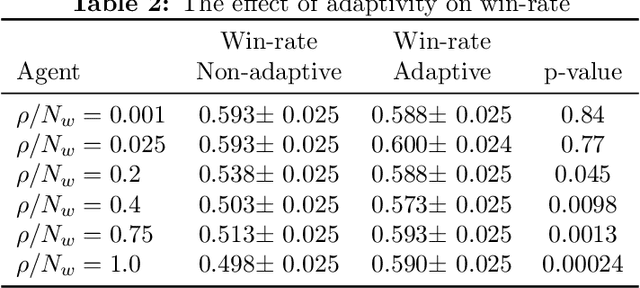
Balancing performance and safety is crucial to deploying autonomous vehicles in multi-agent environments. In particular, autonomous racing is a domain that penalizes safe but conservative policies, highlighting the need for robust, adaptive strategies. Current approaches either make simplifying assumptions about other agents or lack robust mechanisms for online adaptation. This work makes algorithmic contributions to both challenges. First, to generate a realistic, diverse set of opponents, we develop a novel method for self-play based on replica-exchange Markov chain Monte Carlo. Second, we propose a distributionally robust bandit optimization procedure that adaptively adjusts risk aversion relative to uncertainty in beliefs about opponents' behaviors. We rigorously quantify the tradeoffs in performance and robustness when approximating these computations in real-time motion-planning, and we demonstrate our methods experimentally on autonomous vehicles that achieve scaled speeds comparable to Formula One racecars.
Efficient Black-box Assessment of Autonomous Vehicle Safety
Dec 08, 2019
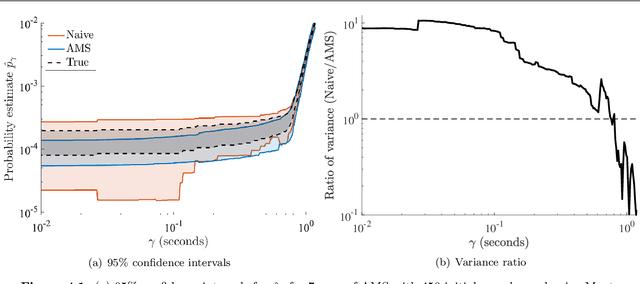
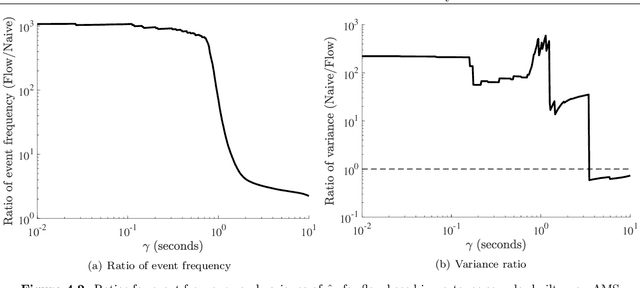
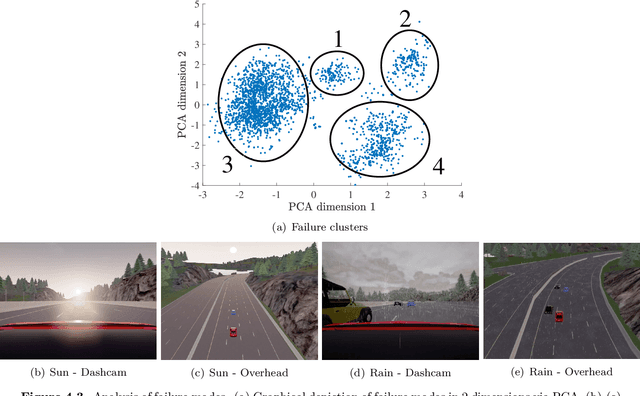
While autonomous vehicle (AV) technology has shown substantial progress, we still lack tools for rigorous and scalable testing. Real-world testing, the $\textit{de-facto}$ evaluation method, is dangerous to the public. Moreover, due to the rare nature of failures, billions of miles of driving are needed to statistically validate performance claims. Thus, the industry has largely turned to simulation to evaluate AV systems. However, having a simulation stack alone is not a solution. A simulation testing framework needs to prioritize which scenarios to run, learn how the chosen scenarios provide coverage of failure modes, and rank failure scenarios in order of importance. We implement a simulation testing framework that evaluates an entire modern AV system as a black box. This framework estimates the probability of accidents under a base distribution governing standard traffic behavior. In order to accelerate rare-event probability evaluation, we efficiently learn to identify and rank failure scenarios via adaptive importance-sampling methods. Using this framework, we conduct the first independent evaluation of a full-stack commercial AV system, Comma AI's OpenPilot.
F1/10: An Open-Source Autonomous Cyber-Physical Platform
Jan 24, 2019
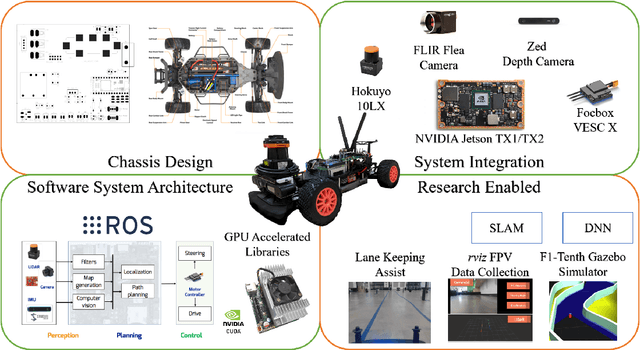
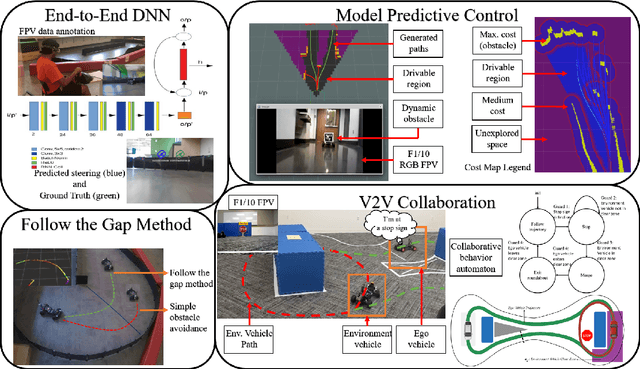
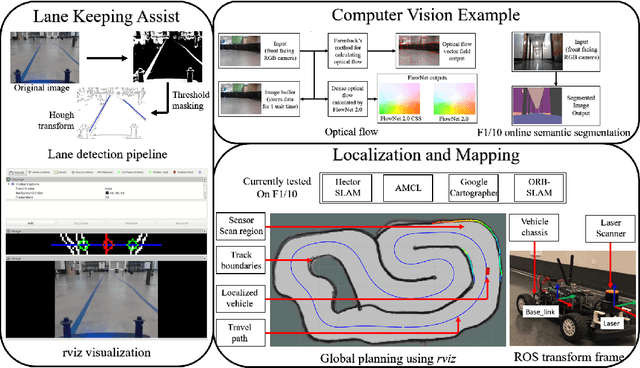
In 2005 DARPA labeled the realization of viable autonomous vehicles (AVs) a grand challenge; a short time later the idea became a moonshot that could change the automotive industry. Today, the question of safety stands between reality and solved. Given the right platform the CPS community is poised to offer unique insights. However, testing the limits of safety and performance on real vehicles is costly and hazardous. The use of such vehicles is also outside the reach of most researchers and students. In this paper, we present F1/10: an open-source, affordable, and high-performance 1/10 scale autonomous vehicle testbed. The F1/10 testbed carries a full suite of sensors, perception, planning, control, and networking software stacks that are similar to full scale solutions. We demonstrate key examples of the research enabled by the F1/10 testbed, and how the platform can be used to augment research and education in autonomous systems, making autonomy more accessible.
Scalable End-to-End Autonomous Vehicle Testing via Rare-event Simulation
Jan 12, 2019

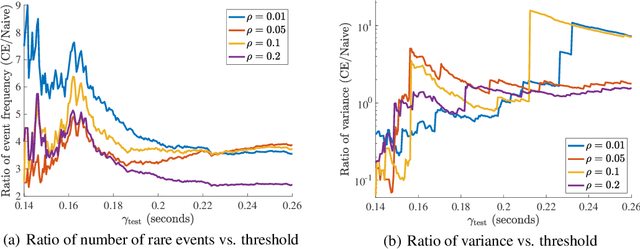

While recent developments in autonomous vehicle (AV) technology highlight substantial progress, we lack tools for rigorous and scalable testing. Real-world testing, the $\textit{de facto}$ evaluation environment, places the public in danger, and, due to the rare nature of accidents, will require billions of miles in order to statistically validate performance claims. We implement a simulation framework that can test an entire modern autonomous driving system, including, in particular, systems that employ deep-learning perception and control algorithms. Using adaptive importance-sampling methods to accelerate rare-event probability evaluation, we estimate the probability of an accident under a base distribution governing standard traffic behavior. We demonstrate our framework on a highway scenario, accelerating system evaluation by $2$-$20$ times over naive Monte Carlo sampling methods and $10$-$300 \mathsf{P}$ times (where $\mathsf{P}$ is the number of processors) over real-world testing.
In-silico Risk Analysis of Personalized Artificial Pancreas Controllers via Rare-event Simulation
Dec 02, 2018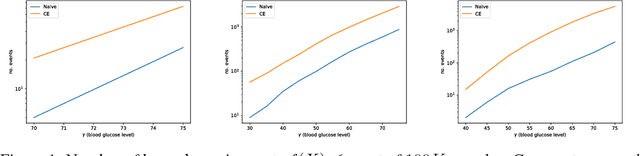
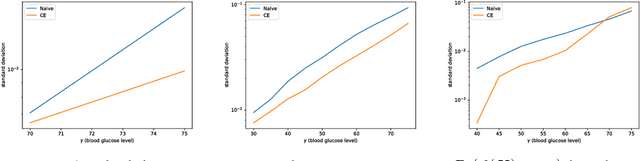
Modern treatments for Type 1 diabetes (T1D) use devices known as artificial pancreata (APs), which combine an insulin pump with a continuous glucose monitor (CGM) operating in a closed-loop manner to control blood glucose levels. In practice, poor performance of APs (frequent hyper- or hypoglycemic events) is common enough at a population level that many T1D patients modify the algorithms on existing AP systems with unregulated open-source software. Anecdotally, the patients in this group have shown superior outcomes compared with standard of care, yet we do not understand how safe any AP system is since adverse outcomes are rare. In this paper, we construct generative models of individual patients' physiological characteristics and eating behaviors. We then couple these models with a T1D simulator approved for pre-clinical trials by the FDA. Given the ability to simulate patient outcomes in-silico, we utilize techniques from rare-event simulation theory in order to efficiently quantify the performance of a device with respect to a particular patient. We show a 72,000$\times$ speedup in simulation speed over real-time and up to 2-10 times increase in the frequency which we are able to sample adverse conditions relative to standard Monte Carlo sampling. In practice our toolchain enables estimates of the likelihood of hypoglycemic events with approximately an order of magnitude fewer simulations.