 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Self-Supervised Pretraining with Part-Aware Representation Learning
Jan 27, 2023



In this paper, we are interested in understanding self-supervised pretraining through studying the capability that self-supervised representation pretraining methods learn part-aware representations. The study is mainly motivated by that random views, used in contrastive learning, and random masked (visible) patches, used in masked image modeling, are often about object parts. We explain that contrastive learning is a part-to-whole task: the projection layer hallucinates the whole object representation from the object part representation learned from the encoder, and that masked image modeling is a part-to-part task: the masked patches of the object are hallucinated from the visible patches. The explanation suggests that the self-supervised pretrained encoder is required to understand the object part. We empirically compare the off-the-shelf encoders pretrained with several representative methods on object-level recognition and part-level recognition. The results show that the fully-supervised model outperforms self-supervised models for object-level recognition, and most self-supervised contrastive learning and masked image modeling methods outperform the fully-supervised method for part-level recognition. It is observed that the combination of contrastive learning and masked image modeling further improves the performance.
Occluded Video Instance Segmentation: Dataset and ICCV 2021 Challenge
Nov 15, 2021


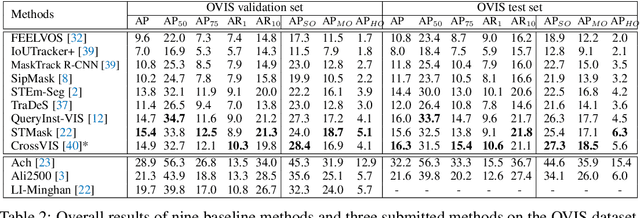
Although deep learning methods have achieved advanced video object recognition performance in recent years, perceiving heavily occluded objects in a video is still a very challenging task. To promote the development of occlusion understanding, we collect a large-scale dataset called OVIS for video instance segmentation in the occluded scenario. OVIS consists of 296k high-quality instance masks and 901 occluded scenes. While our human vision systems can perceive those occluded objects by contextual reasoning and association, our experiments suggest that current video understanding systems cannot. On the OVIS dataset, all baseline methods encounter a significant performance degradation of about 80% in the heavily occluded object group, which demonstrates that there is still a long way to go in understanding obscured objects and videos in a complex real-world scenario. To facilitate the research on new paradigms for video understanding systems, we launched a challenge based on the OVIS dataset. The submitted top-performing algorithms have achieved much higher performance than our baselines. In this paper, we will introduce the OVIS dataset and further dissect it by analyzing the results of baselines and submitted methods. The OVIS dataset and challenge information can be found at http://songbai.site/ovis .
You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
Jun 21, 2021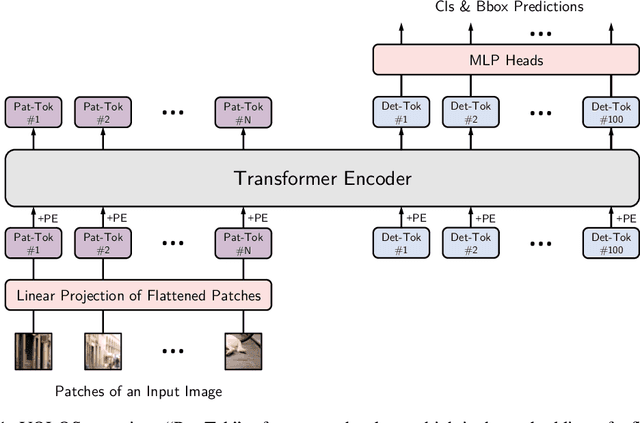
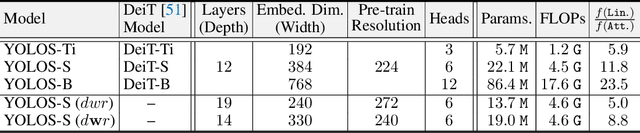
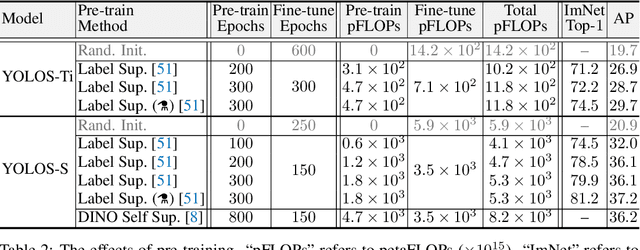

Can Transformer perform $2\mathrm{D}$ object-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the $2\mathrm{D}$ spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the na\"ive Vision Transformer with the fewest possible modifications as well as inductive biases. We find that YOLOS pre-trained on the mid-sized ImageNet-$1k$ dataset only can already achieve competitive object detection performance on COCO, \textit{e.g.}, YOLOS-Base directly adopted from BERT-Base can achieve $42.0$ box AP. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through object detection. Code and model weights are available at \url{https://github.com/hustvl/YOLOS}.
Occluded Video Instance Segmentation
Feb 08, 2021
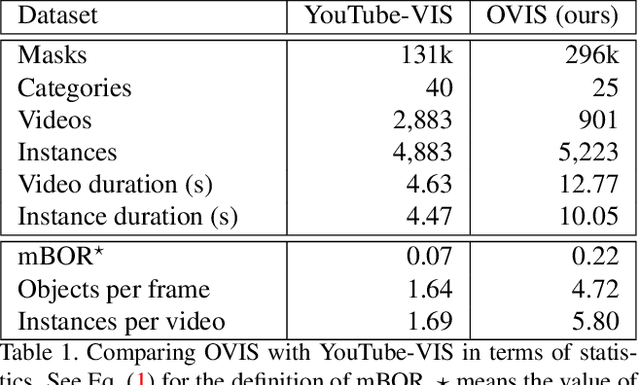

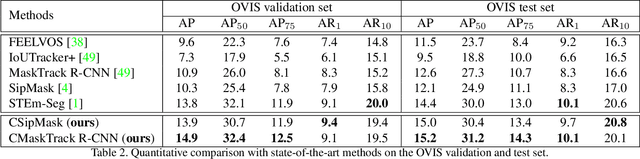
Can our video understanding systems perceive objects when a heavy occlusion exists in a scene? To answer this question, we collect a large scale dataset called OVIS for occluded video instance segmentation, that is, to simultaneously detect, segment, and track instances in occluded scenes. OVIS consists of 296k high-quality instance masks from 25 semantic categories, where object occlusions usually occur. While our human vision systems can understand those occluded instances by contextual reasoning and association, our experiments suggest that current video understanding systems are not satisfying. On the OVIS dataset, the highest AP achieved by state-of-the-art algorithms is only 14.4, which reveals that we are still at a nascent stage for understanding objects, instances, and videos in a real-world scenario. Moreover, to complement missing object cues caused by occlusion, we propose a plug-and-play module called temporal feature calibration. Built upon MaskTrack R-CNN and SipMask, we report an AP of 15.2 and 15.0 respectively. The OVIS dataset is released at http://songbai.site/ovis , and the project code will be available soon.
Multi-Granularity Modularized Network for Abstract Visual Reasoning
Jul 10, 2020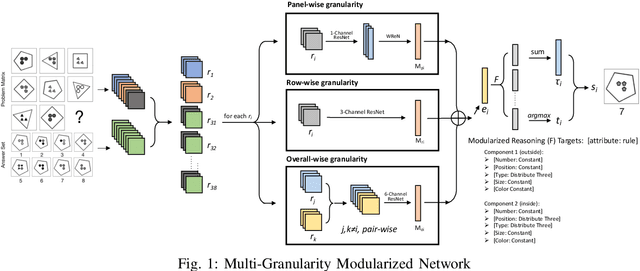
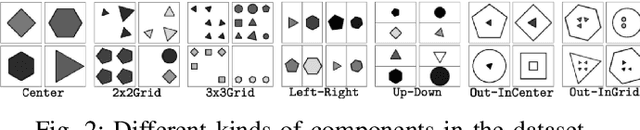
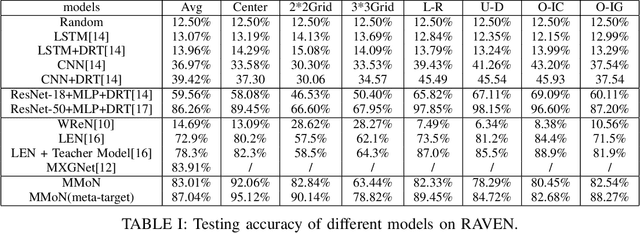

Abstract visual reasoning connects mental abilities to the physical world, which is a crucial factor in cognitive development. Most toddlers display sensitivity to this skill, but it is not easy for machines. Aimed at it, we focus on the Raven Progressive Matrices Test, designed to measure cognitive reasoning. Recent work designed some black-boxes to solve it in an end-to-end fashion, but they are incredibly complicated and difficult to explain. Inspired by cognitive studies, we propose a Multi-Granularity Modularized Network (MMoN) to bridge the gap between the processing of raw sensory information and symbolic reasoning. Specifically, it learns modularized reasoning functions to model the semantic rule from the visual grounding in a neuro-symbolic and semi-supervision way. To comprehensively evaluate MMoN, our experiments are conducted on the dataset of both seen and unseen reasoning rules. The result shows that MMoN is well suited for abstract visual reasoning and also explainable on the generalization test.