 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection
Paper and Code
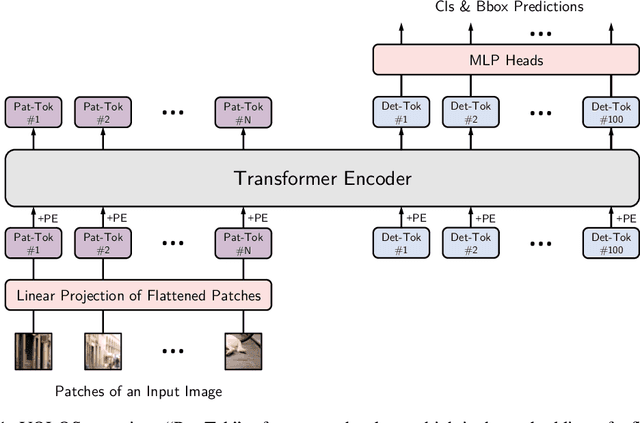
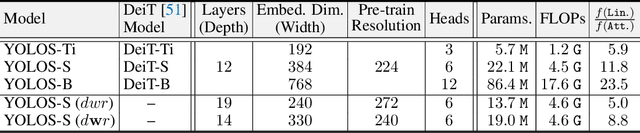
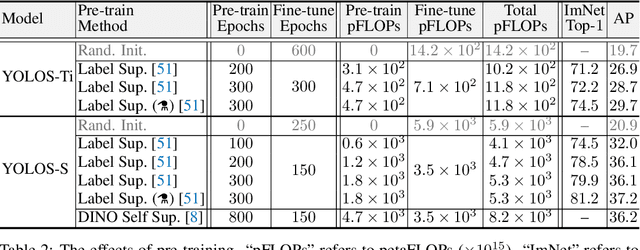

Can Transformer perform $2\mathrm{D}$ object-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the $2\mathrm{D}$ spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the na\"ive Vision Transformer with the fewest possible modifications as well as inductive biases. We find that YOLOS pre-trained on the mid-sized ImageNet-$1k$ dataset only can already achieve competitive object detection performance on COCO, \textit{e.g.}, YOLOS-Base directly adopted from BERT-Base can achieve $42.0$ box AP. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through object detection. Code and model weights are available at \url{https://github.com/hustvl/YOLOS}.