 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccluded Video Instance Segmentation
Paper and Code
Feb 08, 2021
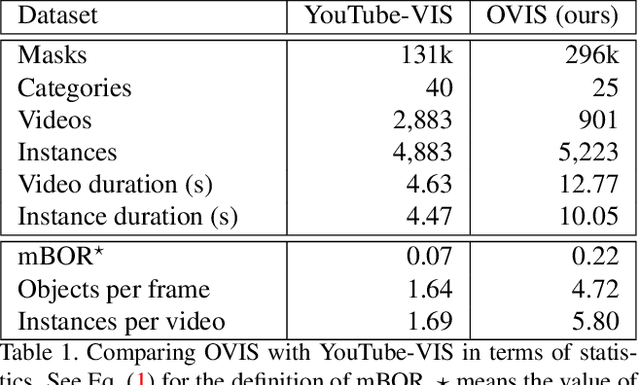

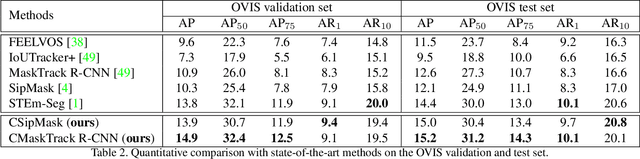
Can our video understanding systems perceive objects when a heavy occlusion exists in a scene? To answer this question, we collect a large scale dataset called OVIS for occluded video instance segmentation, that is, to simultaneously detect, segment, and track instances in occluded scenes. OVIS consists of 296k high-quality instance masks from 25 semantic categories, where object occlusions usually occur. While our human vision systems can understand those occluded instances by contextual reasoning and association, our experiments suggest that current video understanding systems are not satisfying. On the OVIS dataset, the highest AP achieved by state-of-the-art algorithms is only 14.4, which reveals that we are still at a nascent stage for understanding objects, instances, and videos in a real-world scenario. Moreover, to complement missing object cues caused by occlusion, we propose a plug-and-play module called temporal feature calibration. Built upon MaskTrack R-CNN and SipMask, we report an AP of 15.2 and 15.0 respectively. The OVIS dataset is released at http://songbai.site/ovis , and the project code will be available soon.