 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Ensemble Learning with Gaussian Copula for Load Forecasting
Aug 25, 2025Machine learning (ML) is capable of accurate Load Forecasting from complete data. However, there are many uncertainties that affect data collection, leading to sparsity. This article proposed a model called Adaptive Ensemble Learning with Gaussian Copula to deal with sparsity, which contains three modules: data complementation, ML construction, and adaptive ensemble. First, it applies Gaussian Copula to eliminate sparsity. Then, we utilise five ML models to make predictions individually. Finally, it employs adaptive ensemble to get final weighted-sum result. Experiments have demonstrated that our model are robust.
Robust Load Prediction of Power Network Clusters Based on Cloud-Model-Improved Transformer
Jul 30, 2024



Load data from power network clusters indicates economic development in each area, crucial for predicting regional trends and guiding power enterprise decisions. The Transformer model, a leading method for load prediction, faces challenges modeling historical data due to variables like weather, events, festivals, and data volatility. To tackle this, the cloud model's fuzzy feature is utilized to manage uncertainties effectively. Presenting an innovative approach, the Cloud Model Improved Transformer (CMIT) method integrates the Transformer model with the cloud model utilizing the particle swarm optimization algorithm, with the aim of achieving robust and precise power load predictions. Through comparative experiments conducted on 31 real datasets within a power network cluster, it is demonstrated that CMIT significantly surpasses the Transformer model in terms of prediction accuracy, thereby highlighting its effectiveness in enhancing forecasting capabilities within the power network cluster sector.
Boosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024

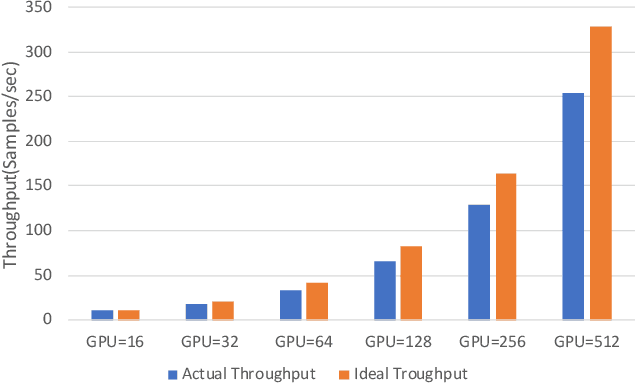

The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
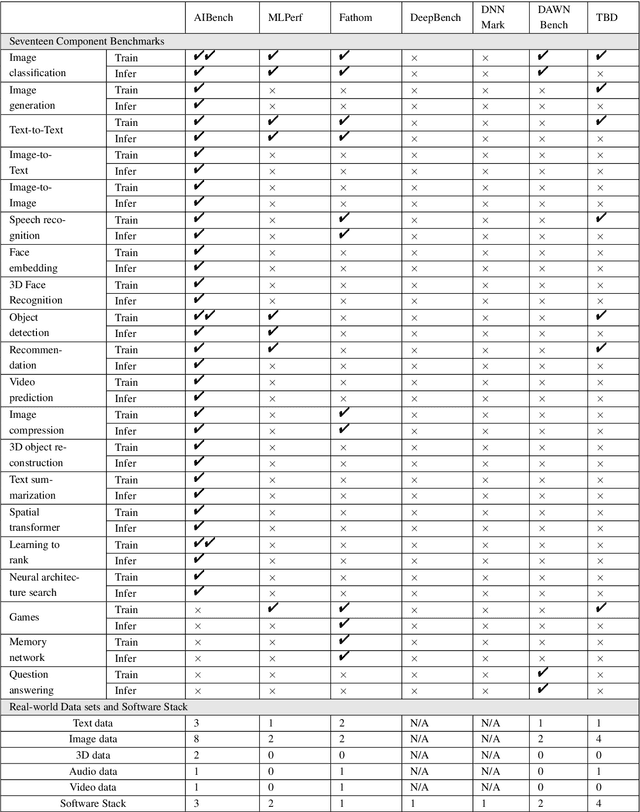
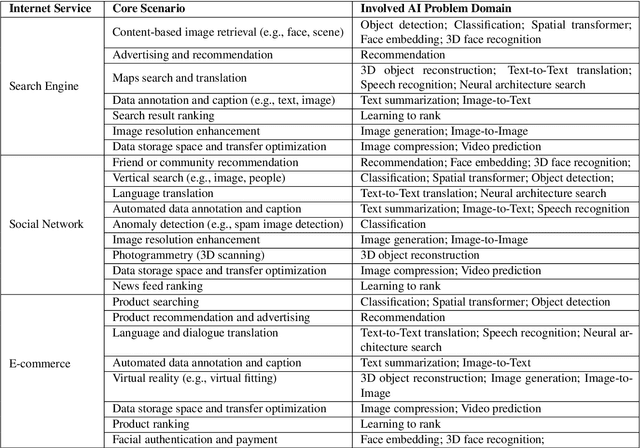
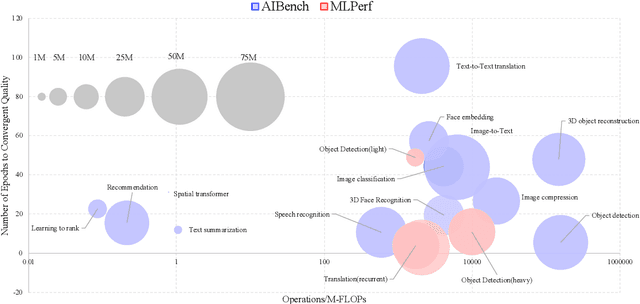
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020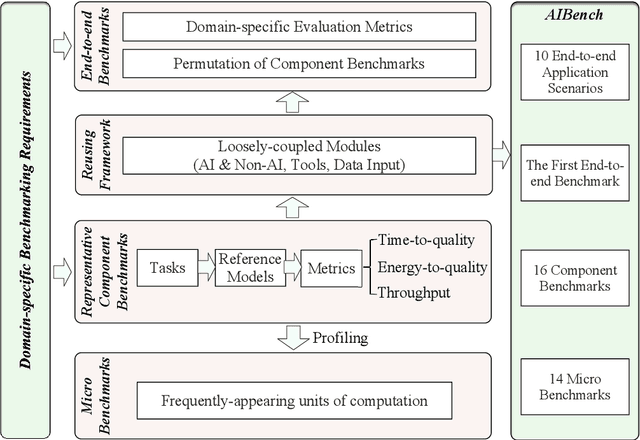
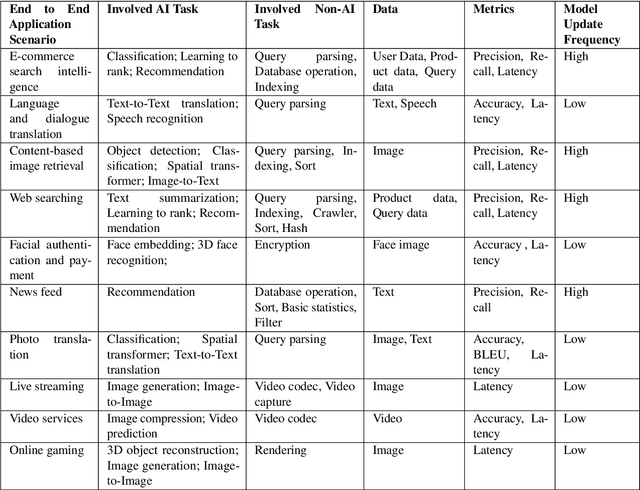

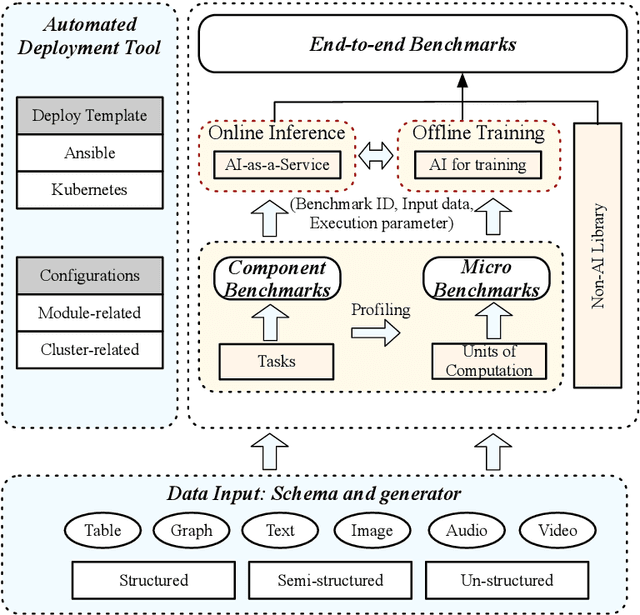
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
BigDataBench: A Dwarf-based Big Data and AI Benchmark Suite
Feb 23, 2018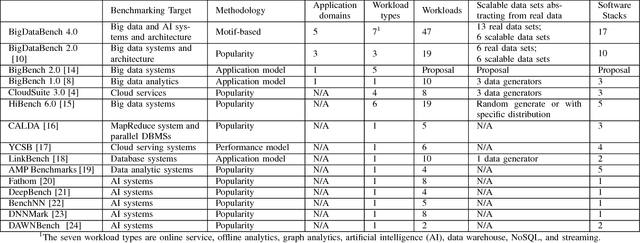
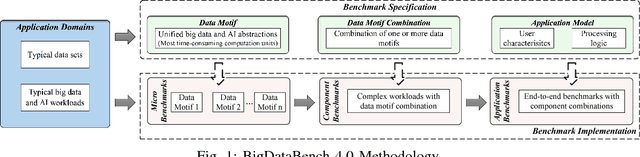
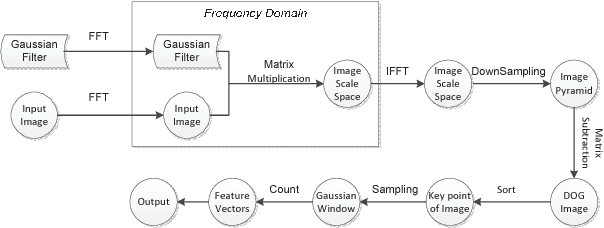
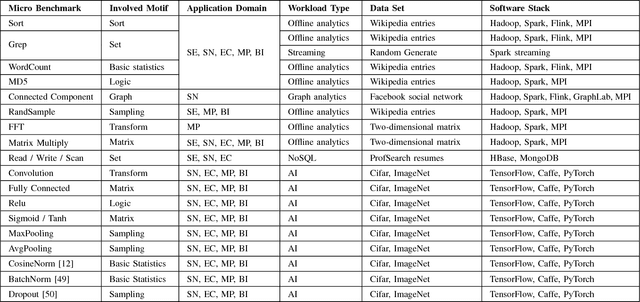
As architecture, system, data management, and machine learning communities pay greater attention to innovative big data and data-driven artificial intelligence (in short, AI) algorithms, architecture, and systems, the pressure of benchmarking rises. However, complexity, diversity, frequently changed workloads, and rapid evolution of big data, especially AI systems raise great challenges in benchmarking. First, for the sake of conciseness, benchmarking scalability, portability cost, reproducibility, and better interpretation of performance data, we need understand what are the abstractions of frequently-appearing units of computation, which we call dwarfs, among big data and AI workloads. Second, for the sake of fairness, the benchmarks must include diversity of data and workloads. Third, for co-design of software and hardware, the benchmarks should be consistent across different communities. Other than creating a new benchmark or proxy for every possible workload, we propose using dwarf-based benchmarks--the combination of eight dwarfs--to represent diversity of big data and AI workloads. The current version--BigDataBench 4.0 provides 13 representative real-world data sets and 47 big data and AI benchmarks, including seven workload types: online service, offline analytics, graph analytics, AI, data warehouse, NoSQL, and streaming. BigDataBench 4.0 is publicly available from http://prof.ict.ac.cn/BigDataBench. Also, for the first time, we comprehensively characterize the benchmarks of seven workload types in BigDataBench 4.0 in addition to traditional benchmarks like SPECCPU, PARSEC and HPCC in a hierarchical manner and drill down on five levels, using the Top-Down analysis from an architecture perspective.