 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
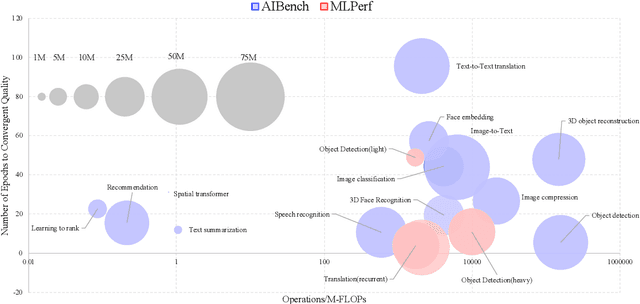
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020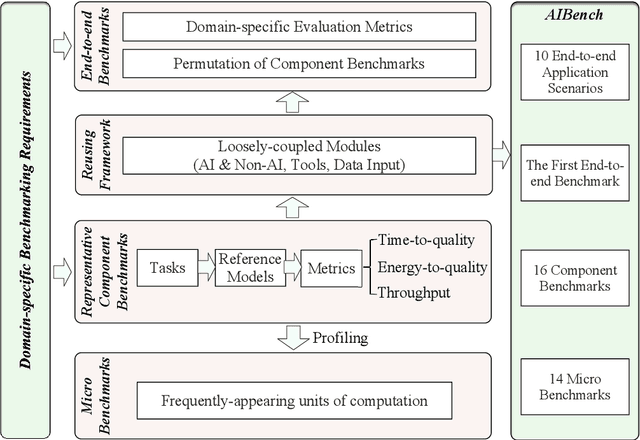
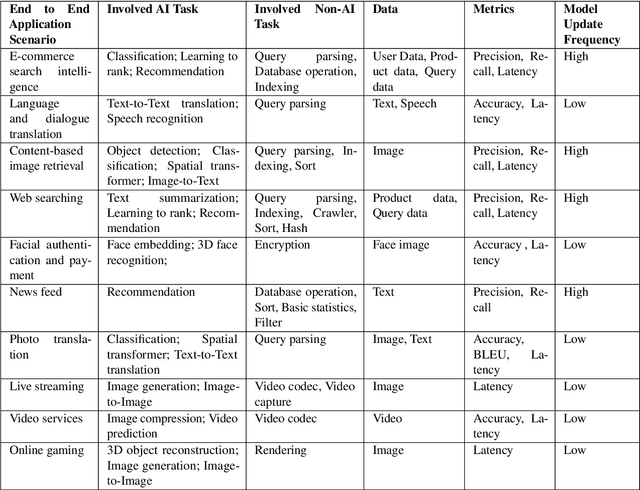

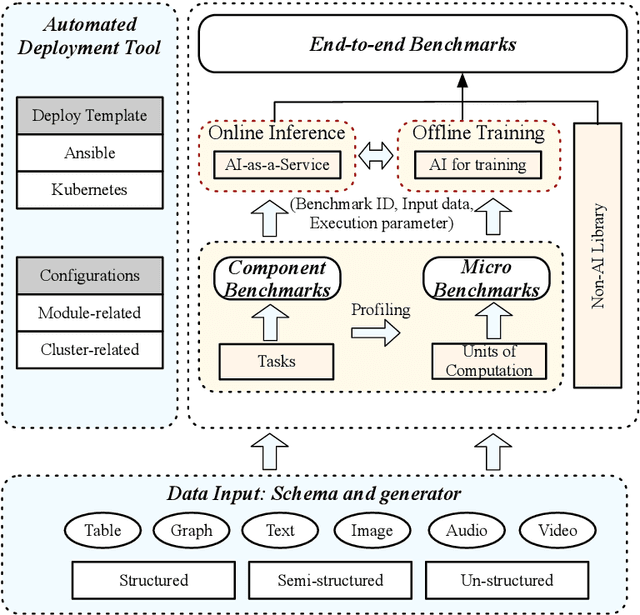
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
AIBench: An Industry Standard Internet Service AI Benchmark Suite
Aug 13, 2019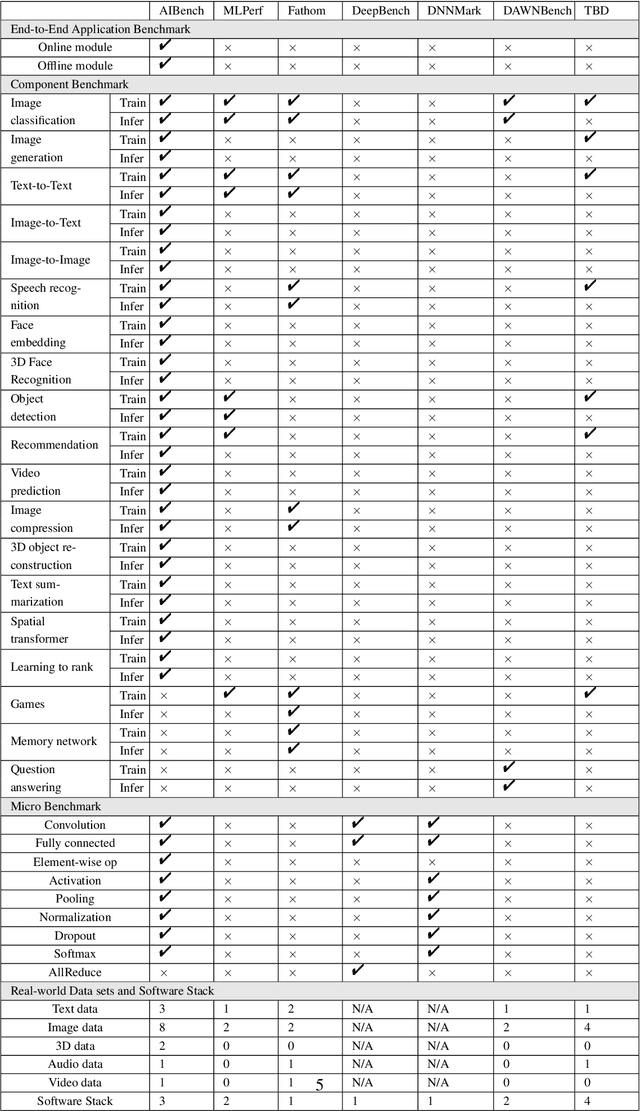
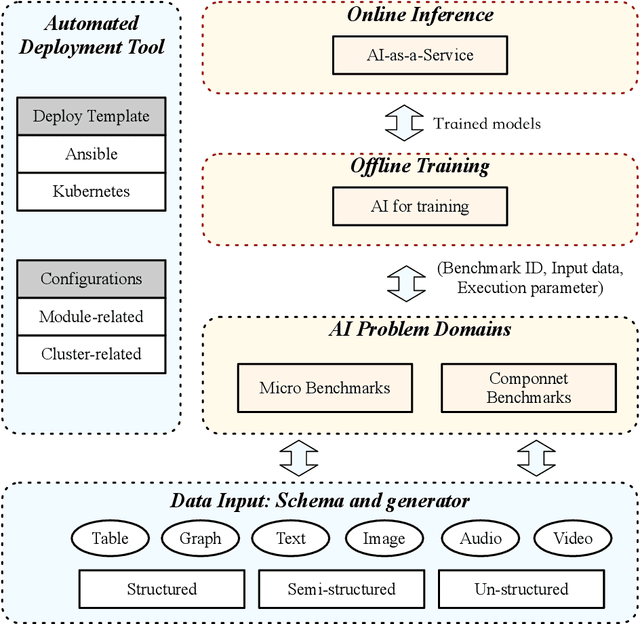
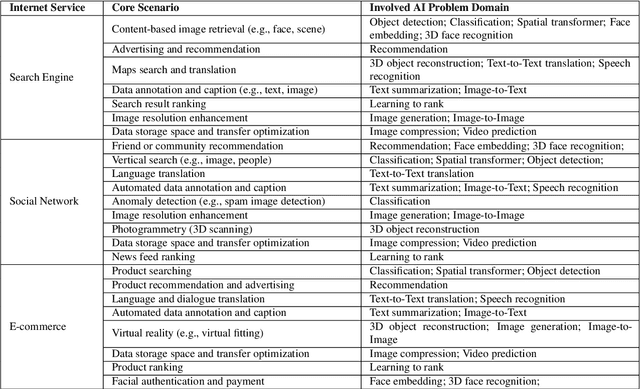
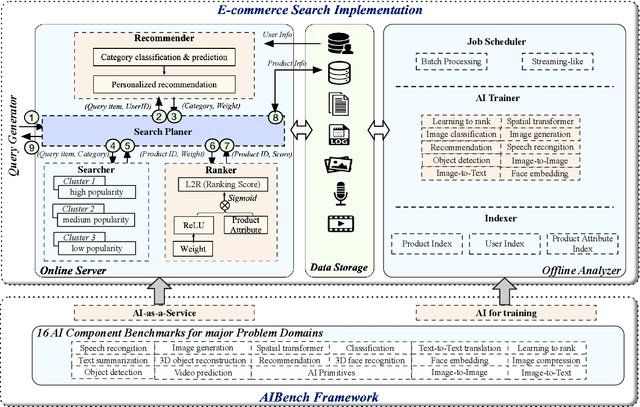
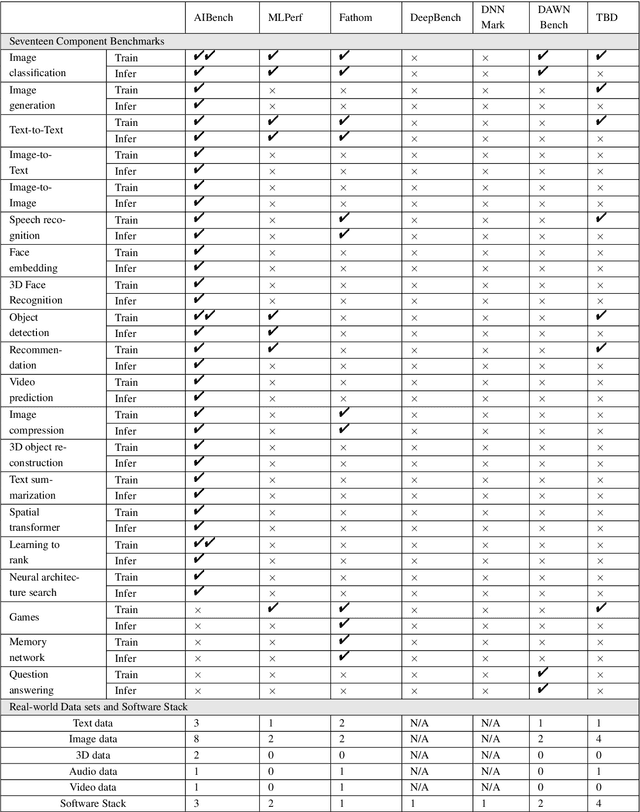
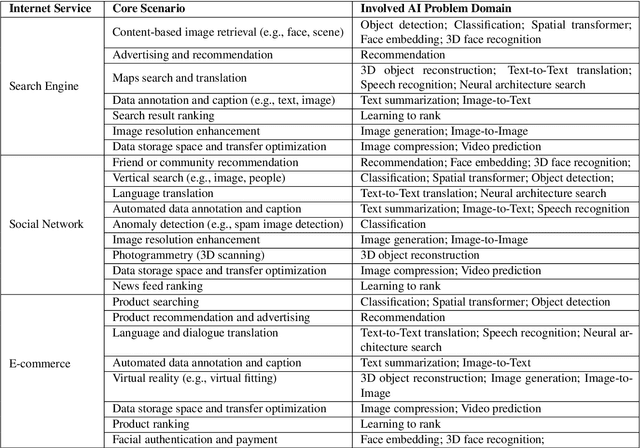
Today's Internet Services are undergoing fundamental changes and shifting to an intelligent computing era where AI is widely employed to augment services. In this context, many innovative AI algorithms, systems, and architectures are proposed, and thus the importance of benchmarking and evaluating them rises. However, modern Internet services adopt a microservice-based architecture and consist of various modules. The diversity of these modules and complexity of execution paths, the massive scale and complex hierarchy of datacenter infrastructure, the confidential issues of data sets and workloads pose great challenges to benchmarking. In this paper, we present the first industry-standard Internet service AI benchmark suite---AIBench with seventeen industry partners, including several top Internet service providers. AIBench provides a highly extensible, configurable, and flexible benchmark framework that contains loosely coupled modules. We identify sixteen prominent AI problem domains like learning to rank, each of which forms an AI component benchmark, from three most important Internet service domains: search engine, social network, and e-commerce, which is by far the most comprehensive AI benchmarking effort. On the basis of the AIBench framework, abstracting the real-world data sets and workloads from one of the top e-commerce providers, we design and implement the first end-to-end Internet service AI benchmark, which contains the primary modules in the critical paths of an industry scale application and is scalable to deploy on different cluster scales. The specifications, source code, and performance numbers are publicly available from the benchmark council web site http://www.benchcouncil.org/AIBench/index.html.
BigDataBench: A Dwarf-based Big Data and AI Benchmark Suite
Feb 23, 2018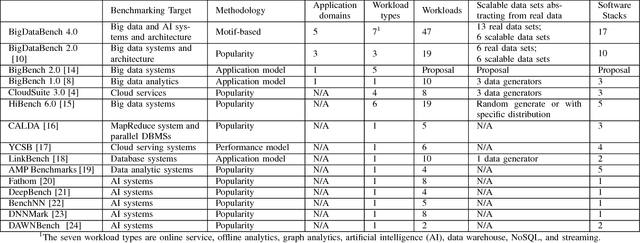
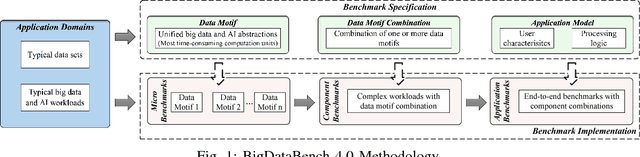
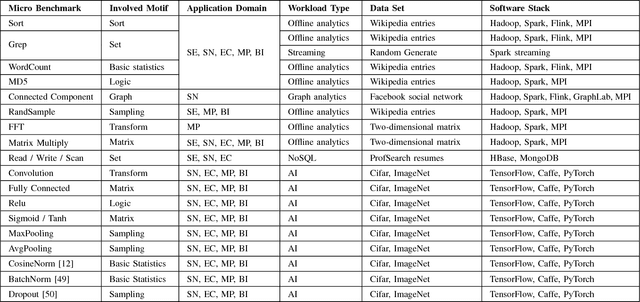
As architecture, system, data management, and machine learning communities pay greater attention to innovative big data and data-driven artificial intelligence (in short, AI) algorithms, architecture, and systems, the pressure of benchmarking rises. However, complexity, diversity, frequently changed workloads, and rapid evolution of big data, especially AI systems raise great challenges in benchmarking. First, for the sake of conciseness, benchmarking scalability, portability cost, reproducibility, and better interpretation of performance data, we need understand what are the abstractions of frequently-appearing units of computation, which we call dwarfs, among big data and AI workloads. Second, for the sake of fairness, the benchmarks must include diversity of data and workloads. Third, for co-design of software and hardware, the benchmarks should be consistent across different communities. Other than creating a new benchmark or proxy for every possible workload, we propose using dwarf-based benchmarks--the combination of eight dwarfs--to represent diversity of big data and AI workloads. The current version--BigDataBench 4.0 provides 13 representative real-world data sets and 47 big data and AI benchmarks, including seven workload types: online service, offline analytics, graph analytics, AI, data warehouse, NoSQL, and streaming. BigDataBench 4.0 is publicly available from http://prof.ict.ac.cn/BigDataBench. Also, for the first time, we comprehensively characterize the benchmarks of seven workload types in BigDataBench 4.0 in addition to traditional benchmarks like SPECCPU, PARSEC and HPCC in a hierarchical manner and drill down on five levels, using the Top-Down analysis from an architecture perspective.