 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForkKV: Scaling Multi-LoRA Agent Serving via Copy-on-Write Disaggregated KV Cache
Apr 07, 2026The serving paradigm of large language models (LLMs) is rapidly shifting towards complex multi-agent workflows where specialized agents collaborate over massive shared contexts. While Low-Rank Adaptation (LoRA) enables the efficient co-hosting of these specialized agents on a single base model, it introduces a critical memory footprint bottleneck during serving. Specifically, unique LoRA activations cause Key-Value (KV) cache divergence across agents, rendering traditional prefix caching ineffective for shared contexts. This forces redundant KV cache maintenance, rapidly saturating GPU capacity and degrading throughput. To address this challenge, we introduce ForkKV, a serving system for multi-LoRA agent workflows centered around a novel memory management paradigm in OS: fork with copy-on-write (CoW). By exploiting the structural properties of LoRA, ForkKV physically decouples the KV cache into a massive shared component (analogous to the parent process's memory pages) and lightweight agent-specific components (the child process's pages). To support this mechanism, we propose a DualRadixTree architecture that allows newly forked agents to inherit the massive shared cache and apply CoW semantics for their lightweight unique cache. Furthermore, to guarantee efficient execution, we design ResidualAttention, a specialized kernel that reconstructs the disaggregated KV cache directly within on-chip SRAM. Comprehensive evaluations across diverse language models and practical datasets of different tasks demonstrate that ForkKV achieves up to 3.0x the throughput of state-of-the-art multi-LoRA serving systems with a negligible impact on generation quality.
SLIM: a Scalable Light-weight Root Cause Analysis for Imbalanced Data in Microservice
May 31, 2024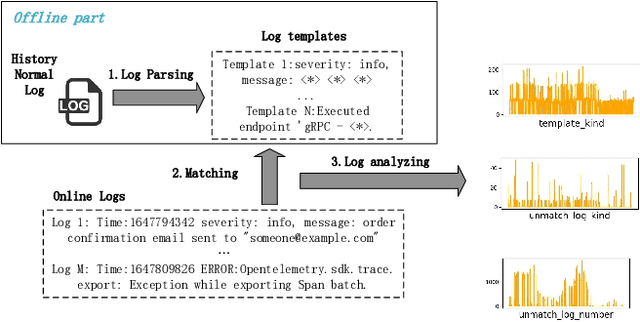
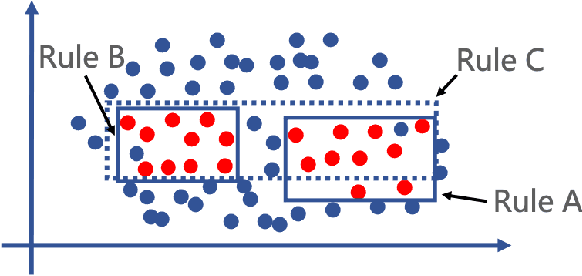
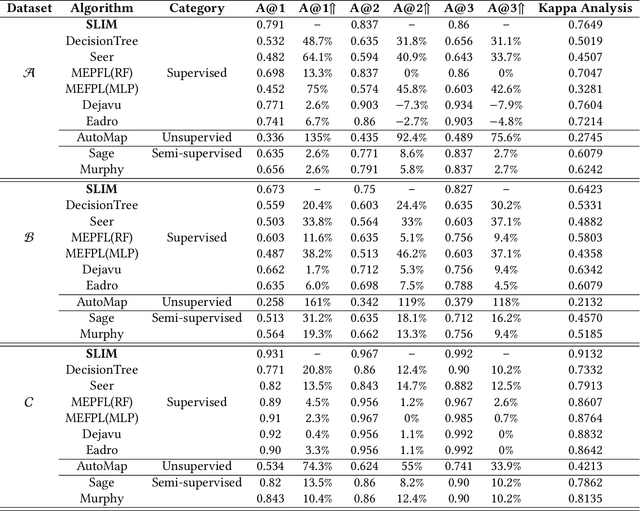
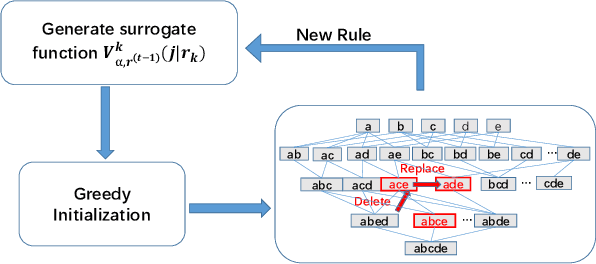
The newly deployed service -- one kind of change service, could lead to a new type of minority fault. Existing state-of-the-art methods for fault localization rarely consider the imbalanced fault classification in change service. This paper proposes a novel method that utilizes decision rule sets to deal with highly imbalanced data by optimizing the F1 score subject to cardinality constraints. The proposed method greedily generates the rule with maximal marginal gain and uses an efficient minorize-maximization (MM) approach to select rules iteratively, maximizing a non-monotone submodular lower bound. Compared with existing fault localization algorithms, our algorithm can adapt to the imbalanced fault scenario of change service, and provide interpretable fault causes which are easy to understand and verify. Our method can also be deployed in the online training setting, with only about 15% training overhead compared to the current SOTA methods. Empirical studies showcase that our algorithm outperforms existing fault localization algorithms in both accuracy and model interpretability.
Interactive Generalized Additive Model and Its Applications in Electric Load Forecasting
Oct 24, 2023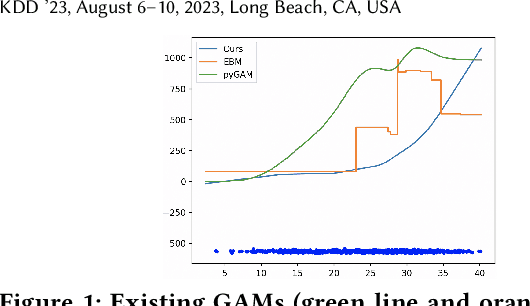
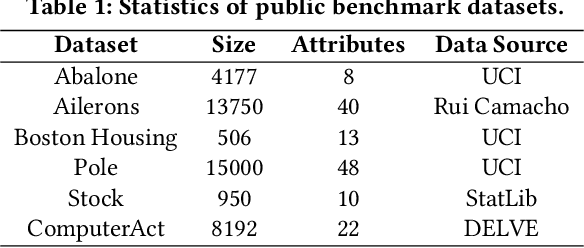
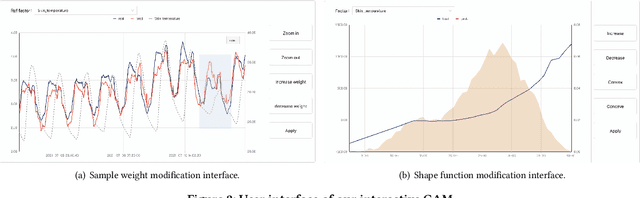
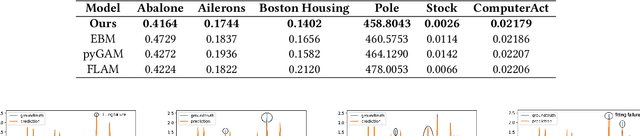
Electric load forecasting is an indispensable component of electric power system planning and management. Inaccurate load forecasting may lead to the threat of outages or a waste of energy. Accurate electric load forecasting is challenging when there is limited data or even no data, such as load forecasting in holiday, or under extreme weather conditions. As high-stakes decision-making usually follows after load forecasting, model interpretability is crucial for the adoption of forecasting models. In this paper, we propose an interactive GAM which is not only interpretable but also can incorporate specific domain knowledge in electric power industry for improved performance. This boosting-based GAM leverages piecewise linear functions and can be learned through our efficient algorithm. In both public benchmark and electricity datasets, our interactive GAM outperforms current state-of-the-art methods and demonstrates good generalization ability in the cases of extreme weather events. We launched a user-friendly web-based tool based on interactive GAM and already incorporated it into our eForecaster product, a unified AI platform for electricity forecasting.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
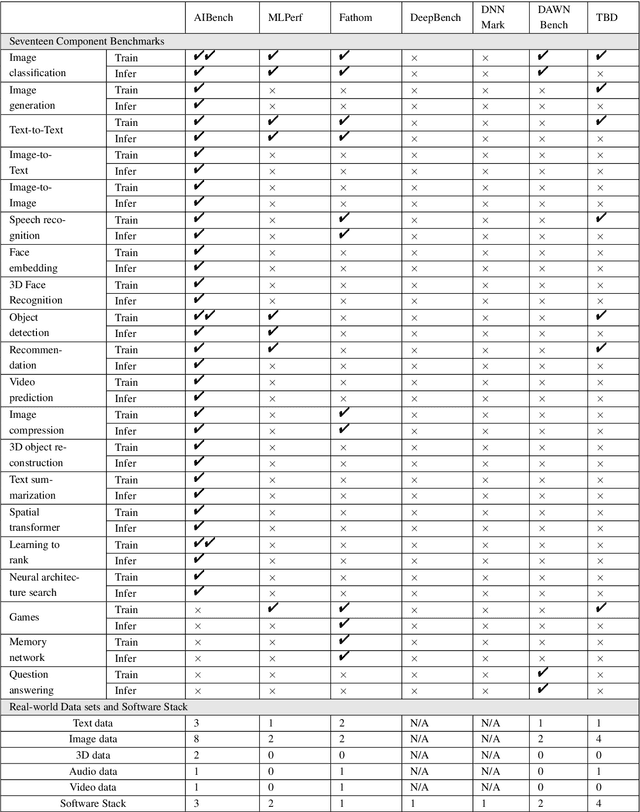
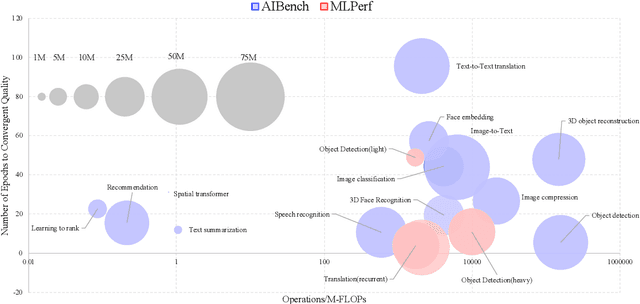
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020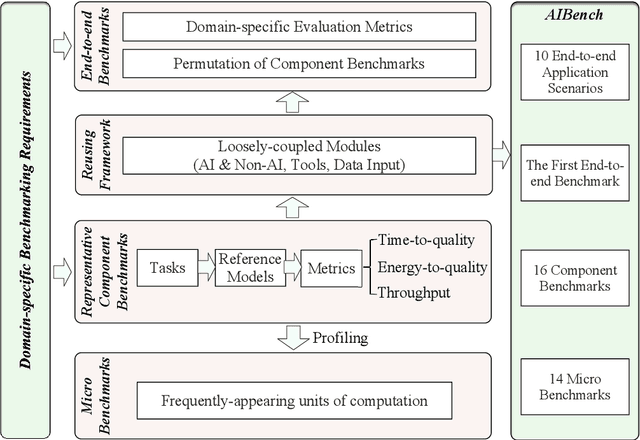
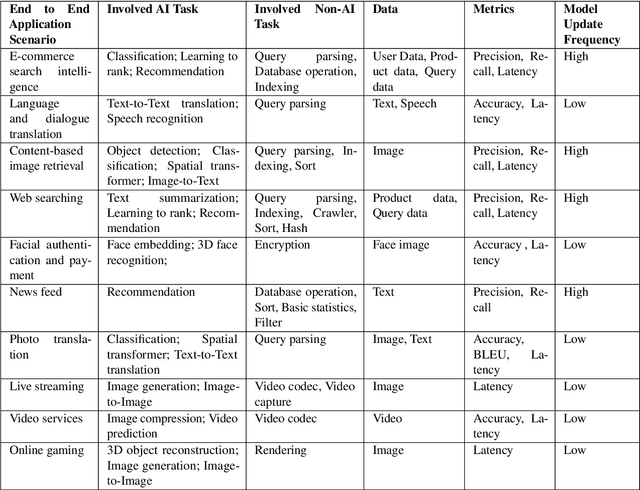

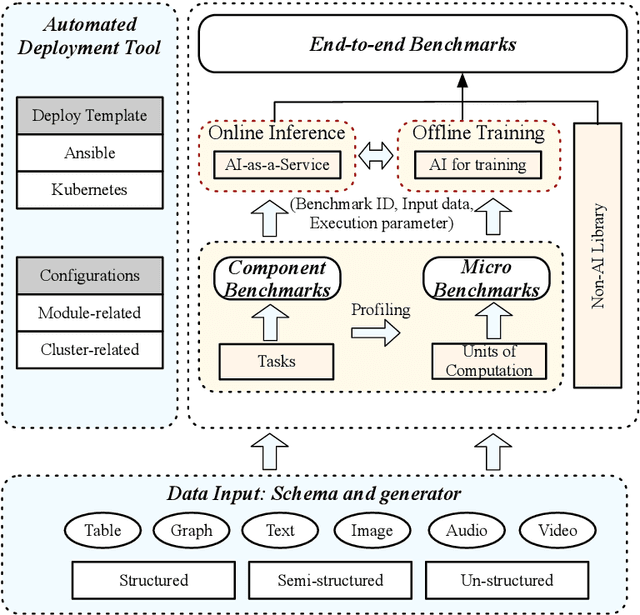
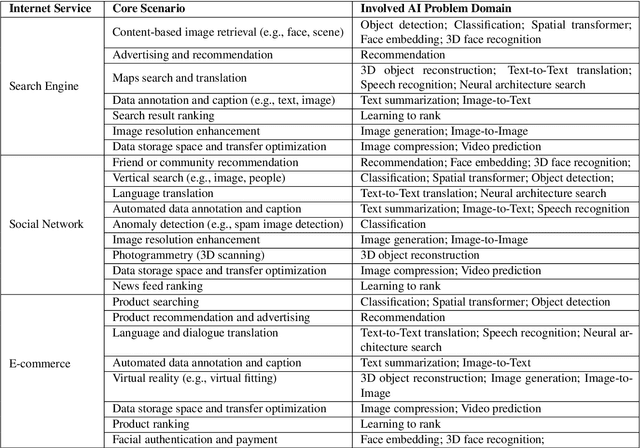
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
BenchCouncil's View on Benchmarking AI and Other Emerging Workloads
Dec 03, 2019This paper outlines BenchCouncil's view on the challenges, rules, and vision of benchmarking modern workloads like Big Data, AI or machine learning, and Internet Services. We conclude the challenges of benchmarking modern workloads as FIDSS (Fragmented, Isolated, Dynamic, Service-based, and Stochastic), and propose the PRDAERS benchmarking rules that the benchmarks should be specified in a paper-and-pencil manner, relevant, diverse, containing different levels of abstractions, specifying the evaluation metrics and methodology, repeatable, and scaleable. We believe proposing simple but elegant abstractions that help achieve both efficiency and general-purpose is the final target of benchmarking in future, which may be not pressing. In the light of this vision, we shortly discuss BenchCouncil's related projects.
BigDataBench: A Dwarf-based Big Data and AI Benchmark Suite
Feb 23, 2018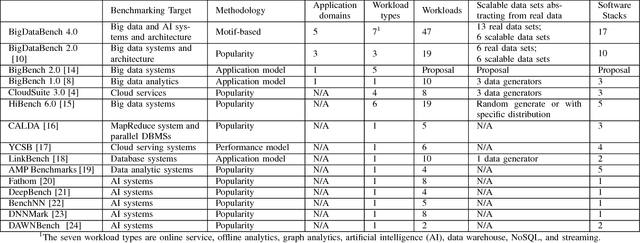
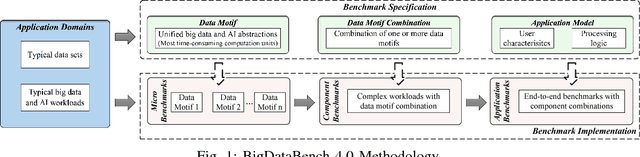
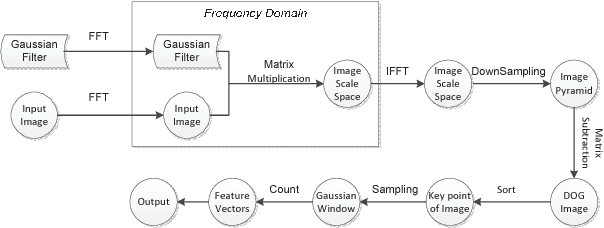
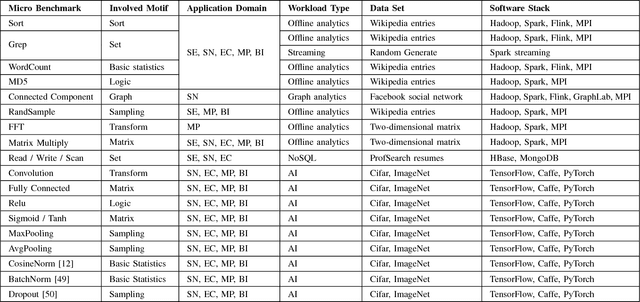
As architecture, system, data management, and machine learning communities pay greater attention to innovative big data and data-driven artificial intelligence (in short, AI) algorithms, architecture, and systems, the pressure of benchmarking rises. However, complexity, diversity, frequently changed workloads, and rapid evolution of big data, especially AI systems raise great challenges in benchmarking. First, for the sake of conciseness, benchmarking scalability, portability cost, reproducibility, and better interpretation of performance data, we need understand what are the abstractions of frequently-appearing units of computation, which we call dwarfs, among big data and AI workloads. Second, for the sake of fairness, the benchmarks must include diversity of data and workloads. Third, for co-design of software and hardware, the benchmarks should be consistent across different communities. Other than creating a new benchmark or proxy for every possible workload, we propose using dwarf-based benchmarks--the combination of eight dwarfs--to represent diversity of big data and AI workloads. The current version--BigDataBench 4.0 provides 13 representative real-world data sets and 47 big data and AI benchmarks, including seven workload types: online service, offline analytics, graph analytics, AI, data warehouse, NoSQL, and streaming. BigDataBench 4.0 is publicly available from http://prof.ict.ac.cn/BigDataBench. Also, for the first time, we comprehensively characterize the benchmarks of seven workload types in BigDataBench 4.0 in addition to traditional benchmarks like SPECCPU, PARSEC and HPCC in a hierarchical manner and drill down on five levels, using the Top-Down analysis from an architecture perspective.
Deep Convolutional Neural Networks for Anomaly Event Classification on Distributed Systems
Dec 30, 2017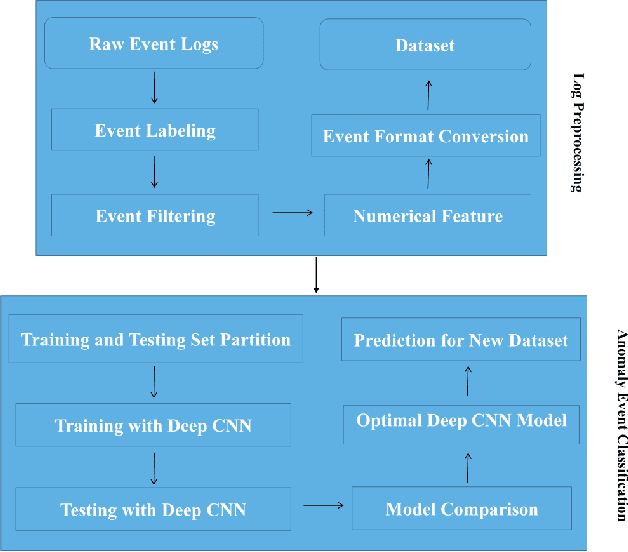
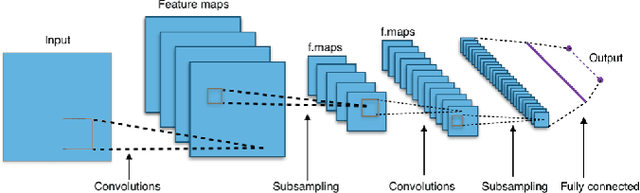
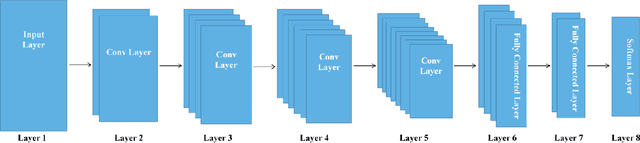
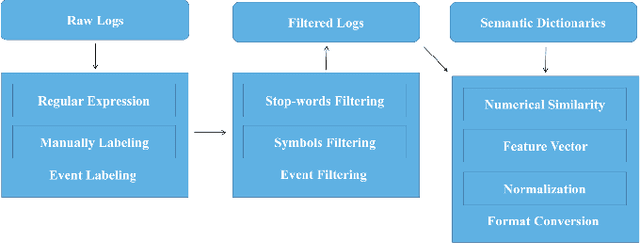
The increasing popularity of server usage has brought a plenty of anomaly log events, which have threatened a vast collection of machines. Recognizing and categorizing the anomalous events thereby is a much salient work for our systems, especially the ones generate the massive amount of data and harness it for technology value creation and business development. To assist in focusing on the classification and the prediction of anomaly events, and gaining critical insights from system event records, we propose a novel log preprocessing method which is very effective to filter abundant information and retain critical characteristics. Additionally, a competitive approach for automated classification of anomalous events detected from the distributed system logs with the state-of-the-art deep (Convolutional Neural Network) architectures is proposed in this paper. We measure a series of deep CNN algorithms with varied hyper-parameter combinations by using standard evaluation metrics, the results of our study reveals the advantages and potential capabilities of the proposed deep CNN models for anomaly event classification tasks on real-world systems. The optimal classification precision of our approach is 98.14%, which surpasses the popular traditional machine learning methods.