 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigDataBench: A Dwarf-based Big Data and AI Benchmark Suite
Paper and Code
Feb 23, 2018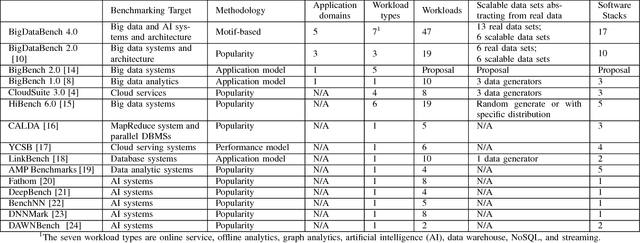
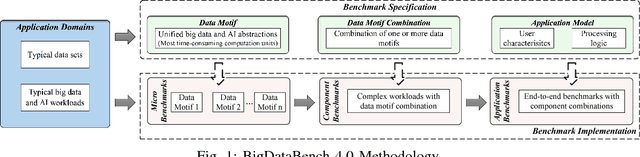
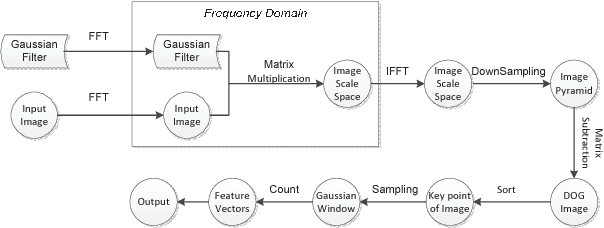
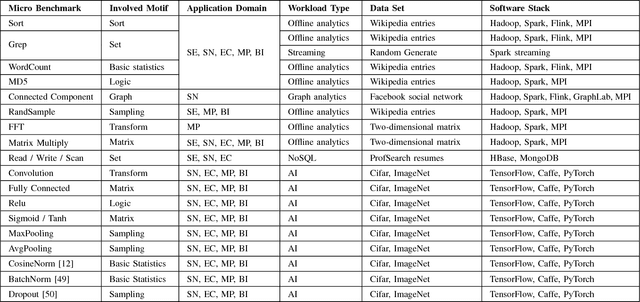
As architecture, system, data management, and machine learning communities pay greater attention to innovative big data and data-driven artificial intelligence (in short, AI) algorithms, architecture, and systems, the pressure of benchmarking rises. However, complexity, diversity, frequently changed workloads, and rapid evolution of big data, especially AI systems raise great challenges in benchmarking. First, for the sake of conciseness, benchmarking scalability, portability cost, reproducibility, and better interpretation of performance data, we need understand what are the abstractions of frequently-appearing units of computation, which we call dwarfs, among big data and AI workloads. Second, for the sake of fairness, the benchmarks must include diversity of data and workloads. Third, for co-design of software and hardware, the benchmarks should be consistent across different communities. Other than creating a new benchmark or proxy for every possible workload, we propose using dwarf-based benchmarks--the combination of eight dwarfs--to represent diversity of big data and AI workloads. The current version--BigDataBench 4.0 provides 13 representative real-world data sets and 47 big data and AI benchmarks, including seven workload types: online service, offline analytics, graph analytics, AI, data warehouse, NoSQL, and streaming. BigDataBench 4.0 is publicly available from http://prof.ict.ac.cn/BigDataBench. Also, for the first time, we comprehensively characterize the benchmarks of seven workload types in BigDataBench 4.0 in addition to traditional benchmarks like SPECCPU, PARSEC and HPCC in a hierarchical manner and drill down on five levels, using the Top-Down analysis from an architecture perspective.