 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024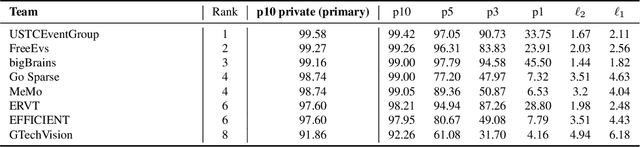
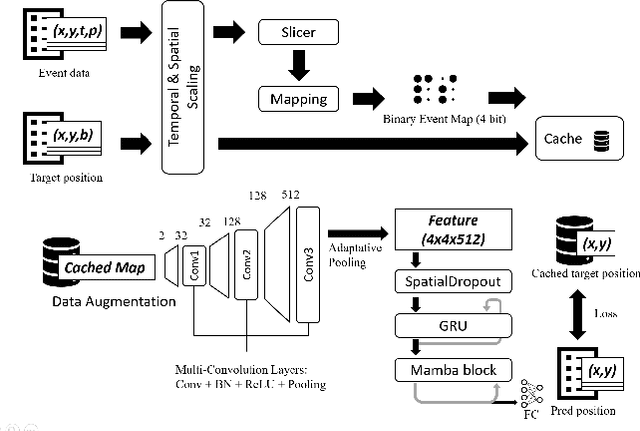
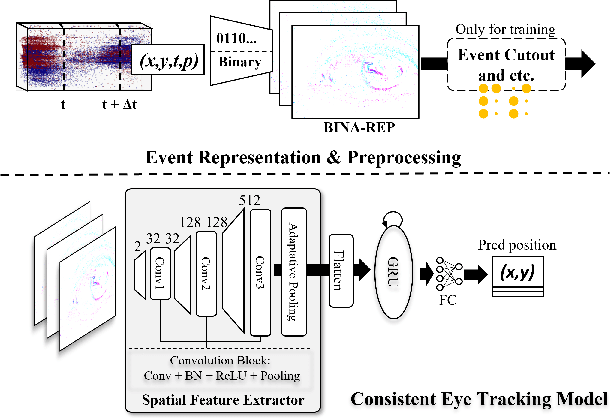

This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
Event-based Asynchronous HDR Imaging by Temporal Incident Light Modulation
Mar 14, 2024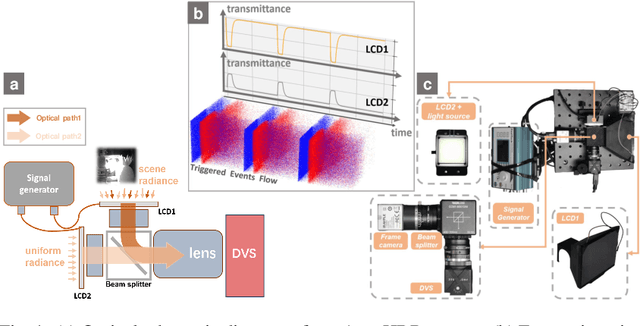
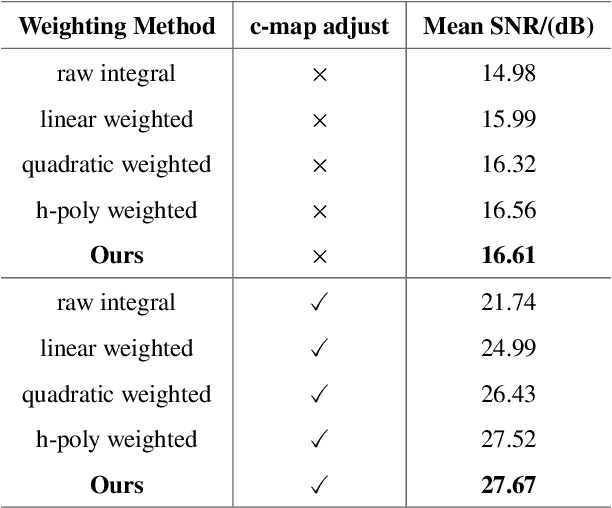


Dynamic Range (DR) is a pivotal characteristic of imaging systems. Current frame-based cameras struggle to achieve high dynamic range imaging due to the conflict between globally uniform exposure and spatially variant scene illumination. In this paper, we propose AsynHDR, a Pixel-Asynchronous HDR imaging system, based on key insights into the challenges in HDR imaging and the unique event-generating mechanism of Dynamic Vision Sensors (DVS). Our proposed AsynHDR system integrates the DVS with a set of LCD panels. The LCD panels modulate the irradiance incident upon the DVS by altering their transparency, thereby triggering the pixel-independent event streams. The HDR image is subsequently decoded from the event streams through our temporal-weighted algorithm. Experiments under standard test platform and several challenging scenes have verified the feasibility of the system in HDR imaging task.
DeeperForensics Challenge 2020 on Real-World Face Forgery Detection: Methods and Results
Feb 18, 2021
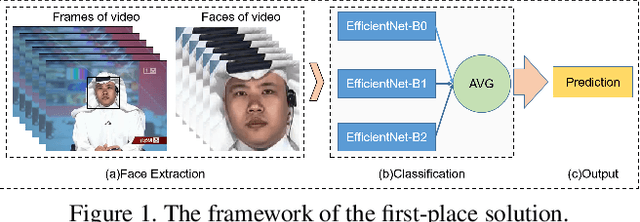
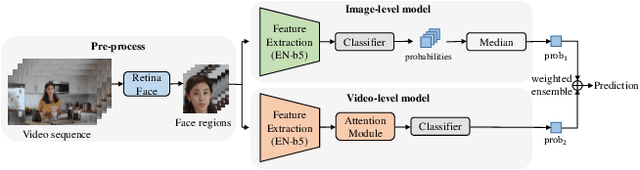
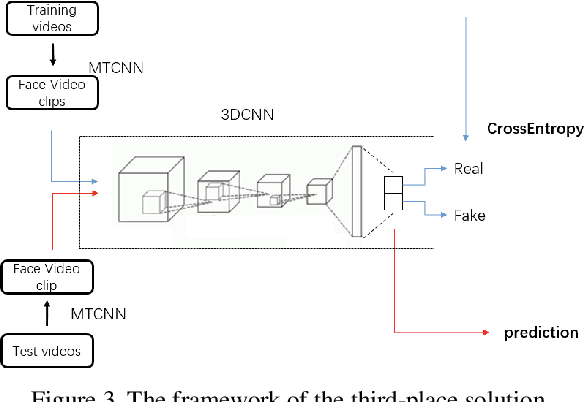
This paper reports methods and results in the DeeperForensics Challenge 2020 on real-world face forgery detection. The challenge employs the DeeperForensics-1.0 dataset, one of the most extensive publicly available real-world face forgery detection datasets, with 60,000 videos constituted by a total of 17.6 million frames. The model evaluation is conducted online on a high-quality hidden test set with multiple sources and diverse distortions. A total of 115 participants registered for the competition, and 25 teams made valid submissions. We will summarize the winning solutions and present some discussions on potential research directions.
Learning to Discretely Compose Reasoning Module Networks for Video Captioning
Jul 17, 2020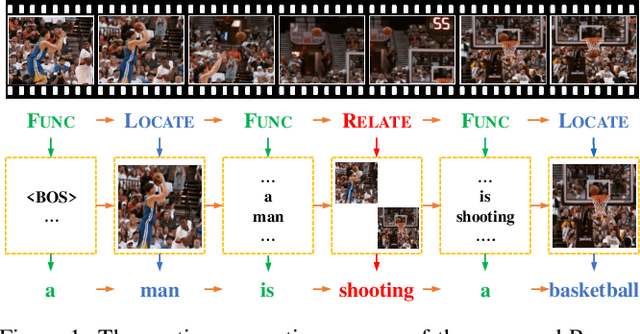

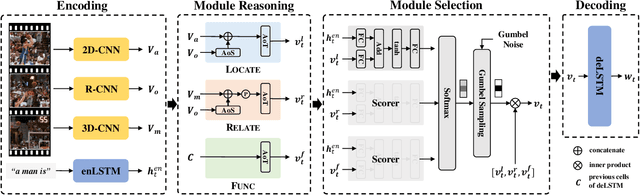
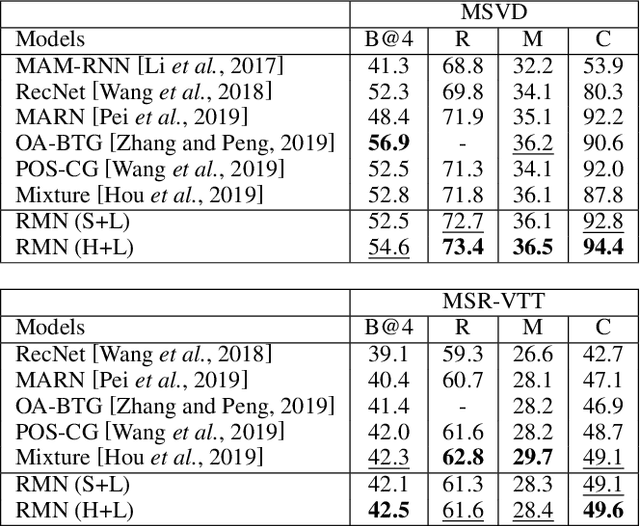
Generating natural language descriptions for videos, i.e., video captioning, essentially requires step-by-step reasoning along the generation process. For example, to generate the sentence "a man is shooting a basketball", we need to first locate and describe the subject "man", next reason out the man is "shooting", then describe the object "basketball" of shooting. However, existing visual reasoning methods designed for visual question answering are not appropriate to video captioning, for it requires more complex visual reasoning on videos over both space and time, and dynamic module composition along the generation process. In this paper, we propose a novel visual reasoning approach for video captioning, named Reasoning Module Networks (RMN), to equip the existing encoder-decoder framework with the above reasoning capacity. Specifically, our RMN employs 1) three sophisticated spatio-temporal reasoning modules, and 2) a dynamic and discrete module selector trained by a linguistic loss with a Gumbel approximation. Extensive experiments on MSVD and MSR-VTT datasets demonstrate the proposed RMN outperforms the state-of-the-art methods while providing an explicit and explainable generation process. Our code is available at https://github.com/tgc1997/RMN.
* Accepted at IJCAI 2020 Main Track. Sole copyright holder is IJCAI. Code is available at https://github.com/tgc1997/RMN