 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Explicit-Input Assistance for Teleoperation in Clutter
Feb 04, 2024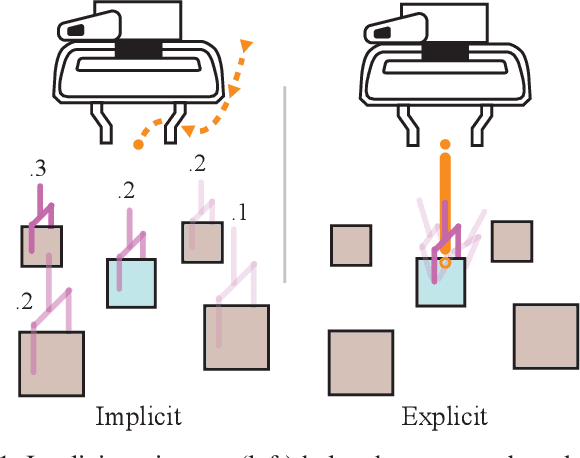
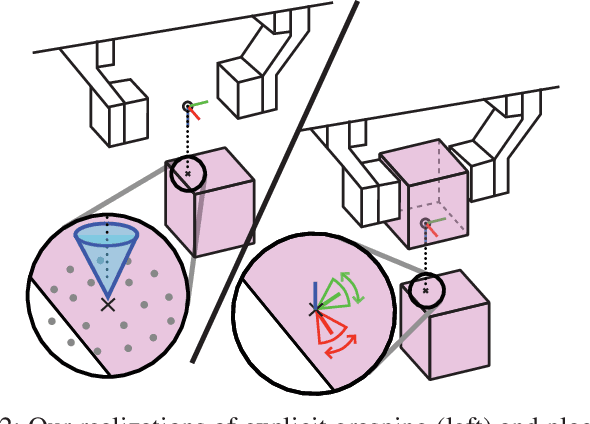

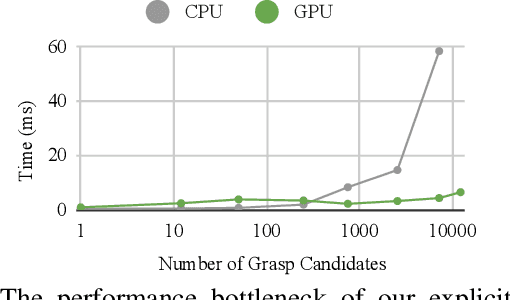
The performance of prediction-based assistance for robot teleoperation degrades in unseen or goal-rich environments due to incorrect or quickly-changing intent inferences. Poor predictions can confuse operators or cause them to change their control input to implicitly signal their goal, resulting in unnatural movement. We present a new assistance algorithm and interface for robotic manipulation where an operator can explicitly communicate a manipulation goal by pointing the end-effector. Rapid optimization and parallel collision checking in a local region around the pointing target enable direct, interactive control over grasp and place pose candidates. We compare the explicit pointing interface to an implicit inference-based assistance scheme in a within-subjects user study (N=20) where participants teleoperate a simulated robot to complete a multi-step singulation and stacking task in cluttered environments. We find that operators prefer the explicit interface, which improved completion time, pick and place success rates, and NASA TLX scores. Our code is available at https://github.com/NVlabs/fast-explicit-teleop
Learning Human-to-Robot Handovers from Point Clouds
Mar 30, 2023We propose the first framework to learn control policies for vision-based human-to-robot handovers, a critical task for human-robot interaction. While research in Embodied AI has made significant progress in training robot agents in simulated environments, interacting with humans remains challenging due to the difficulties of simulating humans. Fortunately, recent research has developed realistic simulated environments for human-to-robot handovers. Leveraging this result, we introduce a method that is trained with a human-in-the-loop via a two-stage teacher-student framework that uses motion and grasp planning, reinforcement learning, and self-supervision. We show significant performance gains over baselines on a simulation benchmark, sim-to-sim transfer and sim-to-real transfer.
Co-GAIL: Learning Diverse Strategies for Human-Robot Collaboration
Aug 13, 2021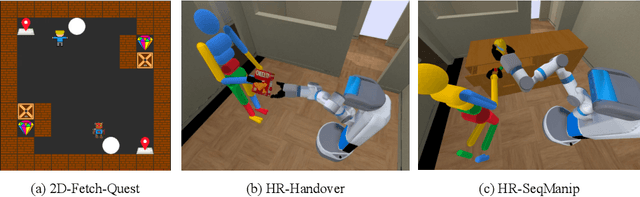
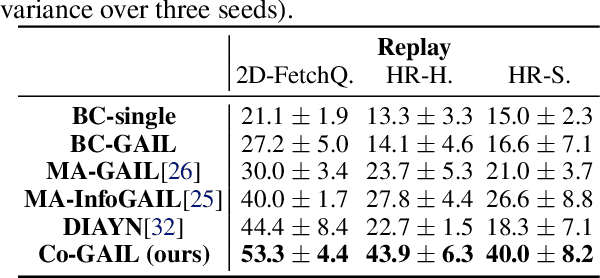
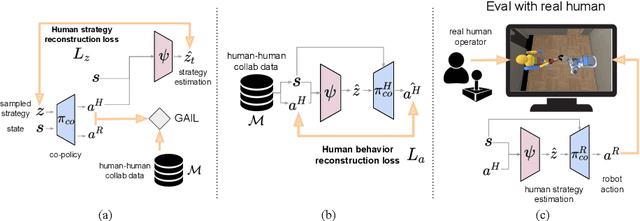
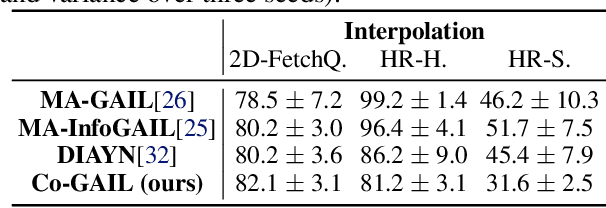
We present a method for learning a human-robot collaboration policy from human-human collaboration demonstrations. An effective robot assistant must learn to handle diverse human behaviors shown in the demonstrations and be robust when the humans adjust their strategies during online task execution. Our method co-optimizes a human policy and a robot policy in an interactive learning process: the human policy learns to generate diverse and plausible collaborative behaviors from demonstrations while the robot policy learns to assist by estimating the unobserved latent strategy of its human collaborator. Across a 2D strategy game, a human-robot handover task, and a multi-step collaborative manipulation task, our method outperforms the alternatives in both simulated evaluations and when executing the tasks with a real human operator in-the-loop. Supplementary materials and videos at https://sites.google.com/view/co-gail-web/home
Experimental Assessment of Human-Robot Teaming for Multi-Step Remote Manipulation with Expert Operators
Nov 22, 2020
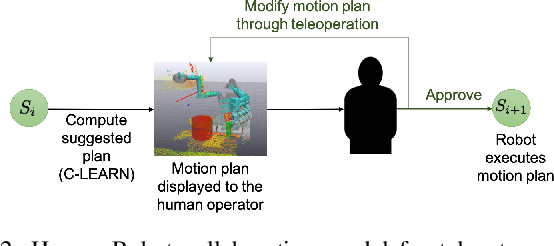
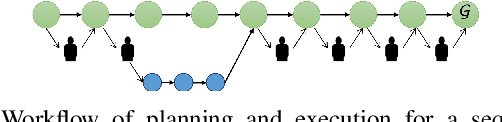

Remote robot manipulation with human control enables applications where safety and environmental constraints are adverse to humans (e.g. underwater, space robotics and disaster response) or the complexity of the task demands human-level cognition and dexterity (e.g. robotic surgery and manufacturing). These systems typically use direct teleoperation at the motion level, and are usually limited to low-DOF arms and 2D perception. Improving dexterity and situational awareness demands new interaction and planning workflows. We explore the use of human-robot teaming through teleautonomy with assisted planning for remote control of a dual-arm dexterous robot for multi-step manipulation tasks, and conduct a within-subjects experimental assessment (n=12 expert users) to compare it with other methods, resulting in the following four conditions: (A) Direct teleoperation with imitation controller + 2D perception, (B) Condition A + 3D perception, (C) Teleautonomy interface teleoperation + 2D & 3D perception, (D) Condition C + assisted planning. The results indicate that this approach (D) achieves task times comparable with direct teleoperation (A,B) while improving a number of other objective and subjective metrics, including re-grasps, collisions, and TLX workload metrics. When compared to a similar interface but removing the assisted planning (C), D reduces the task time and removes a significant interaction with the level of expertise of the operator, resulting in a performance equalizer across users.
Robot Navigation in Constrained Pedestrian Environments using Reinforcement Learning
Oct 16, 2020
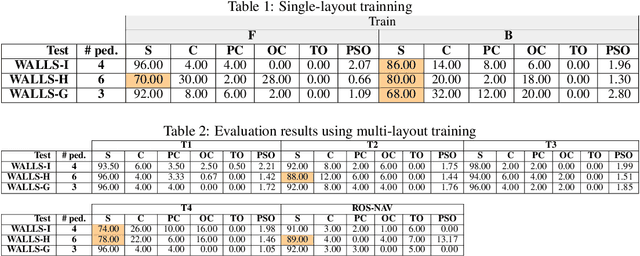
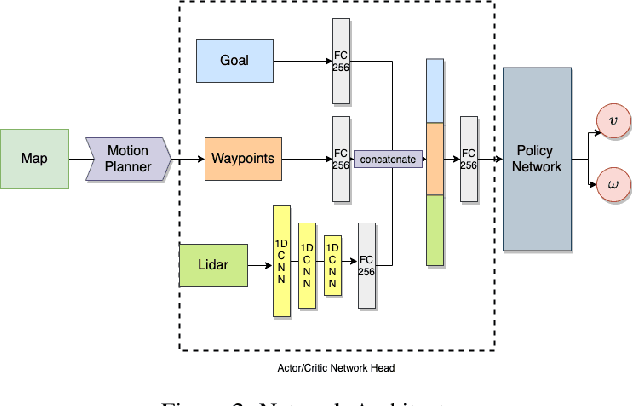
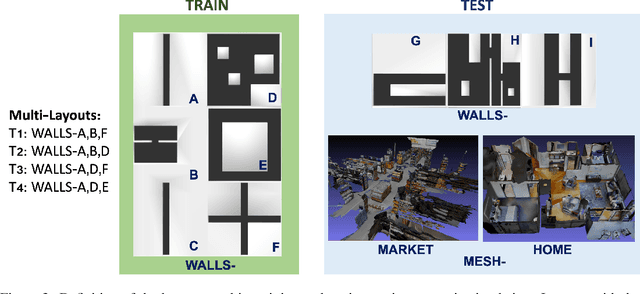
Navigating fluently around pedestrians is a necessary capability for mobile robots deployed in human environments, such as office buildings and homes. While related literature has addressed the co-navigation problem focused on the scalability with the number of pedestrians in open spaces, typical indoor environments present the additional challenge of constrained spaces such as corridors, doorways and crosswalks that limit maneuverability and influence patterns of pedestrian interaction. We present an approach based on reinforcement learning to learn policies capable of dynamic adaptation to the presence of moving pedestrians while navigating between desired locations in constrained environments. The policy network receives guidance from a motion planner that provides waypoints to follow a globally planned trajectory, whereas the reinforcement component handles the local interactions. We explore a compositional principle for multi-layout training and find that policies trained in a small set of geometrically simple layouts successfully generalize to unseen and more complex layouts that exhibit composition of the simple structural elements available during training. Going beyond wall-world like domains, we show transfer of the learned policy to unseen 3D reconstructions of two real environments (market, home). These results support the applicability of the compositional principle to real-world environments and indicate promising usage of agent simulation within reconstructed environments for tasks that involve interaction.