 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Imaging AI Competitions Lack Fairness
Dec 19, 2025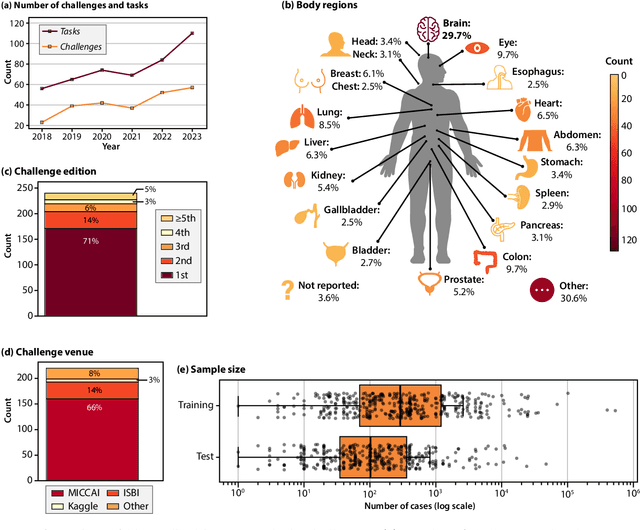
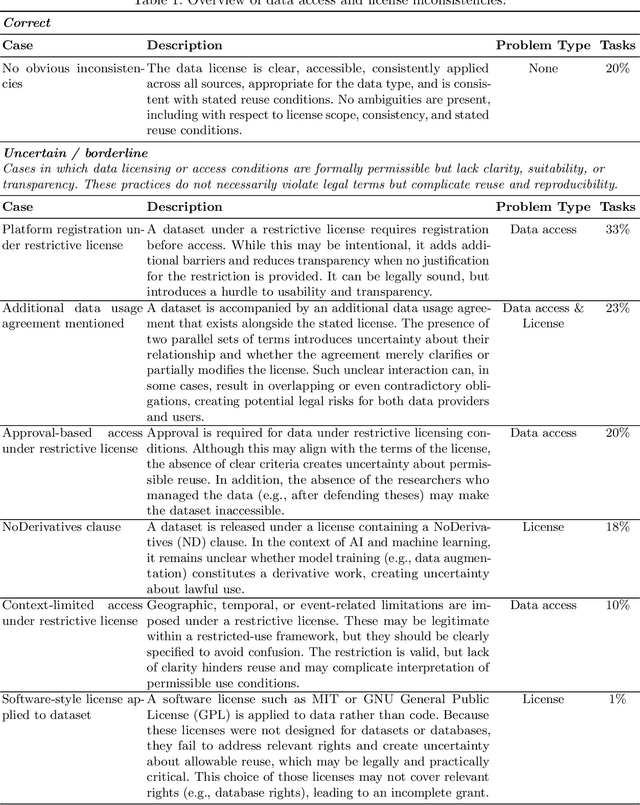
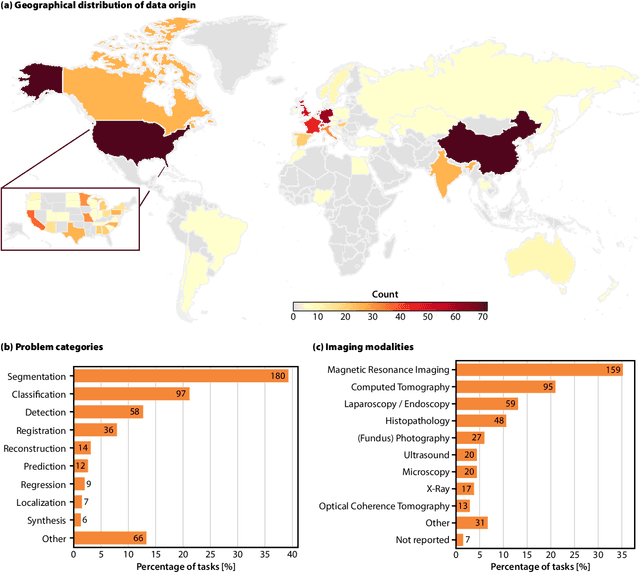
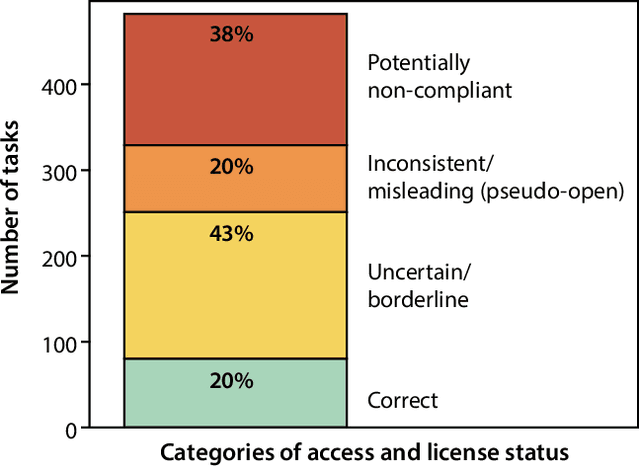
Benchmarking competitions are central to the development of artificial intelligence (AI) in medical imaging, defining performance standards and shaping methodological progress. However, it remains unclear whether these benchmarks provide data that are sufficiently representative, accessible, and reusable to support clinically meaningful AI. In this work, we assess fairness along two complementary dimensions: (1) whether challenge datasets are representative of real-world clinical diversity, and (2) whether they are accessible and legally reusable in line with the FAIR principles. To address this question, we conducted a large-scale systematic study of 241 biomedical image analysis challenges comprising 458 tasks across 19 imaging modalities. Our findings show substantial biases in dataset composition, including geographic location, modality-, and problem type-related biases, indicating that current benchmarks do not adequately reflect real-world clinical diversity. Despite their widespread influence, challenge datasets were frequently constrained by restrictive or ambiguous access conditions, inconsistent or non-compliant licensing practices, and incomplete documentation, limiting reproducibility and long-term reuse. Together, these shortcomings expose foundational fairness limitations in our benchmarking ecosystem and highlight a disconnect between leaderboard success and clinical relevance.
Deformable MRI Sequence Registration for AI-based Prostate Cancer Diagnosis
Apr 15, 2024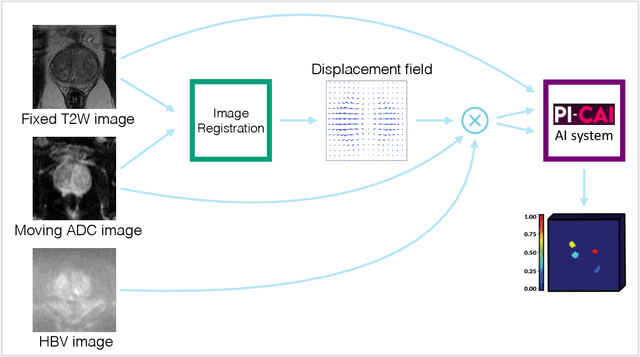
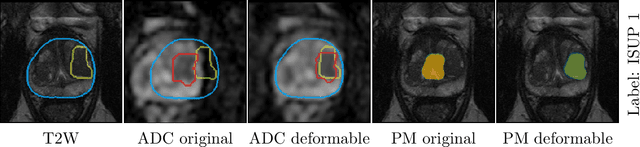
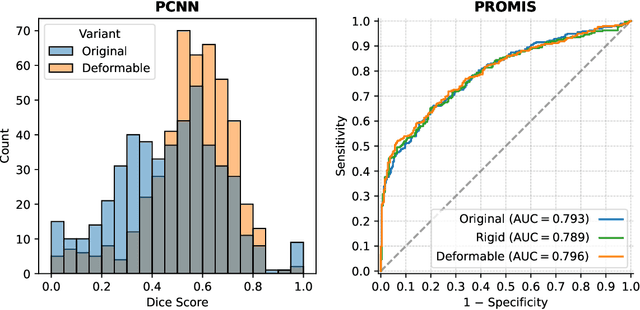
The PI-CAI (Prostate Imaging: Cancer AI) challenge led to expert-level diagnostic algorithms for clinically significant prostate cancer detection. The algorithms receive biparametric MRI scans as input, which consist of T2-weighted and diffusion-weighted scans. These scans can be misaligned due to multiple factors in the scanning process. Image registration can alleviate this issue by predicting the deformation between the sequences. We investigate the effect of image registration on the diagnostic performance of AI-based prostate cancer diagnosis. First, the image registration algorithm, developed in MeVisLab, is analyzed using a dataset with paired lesion annotations. Second, the effect on diagnosis is evaluated by comparing case-level cancer diagnosis performance between using the original dataset, rigidly aligned diffusion-weighted scans, or deformably aligned diffusion-weighted scans. Rigid registration showed no improvement. Deformable registration demonstrated a substantial improvement in lesion overlap (+10% median Dice score) and a positive yet non-significant improvement in diagnostic performance (+0.3% AUROC, p=0.18). Our investigation shows that a substantial improvement in lesion alignment does not directly lead to a significant improvement in diagnostic performance. Qualitative analysis indicated that jointly developing image registration methods and diagnostic AI algorithms could enhance diagnostic accuracy and patient outcomes.
Uncertainty-Aware Semi-Supervised Learning for Prostate MRI Zonal Segmentation
May 10, 2023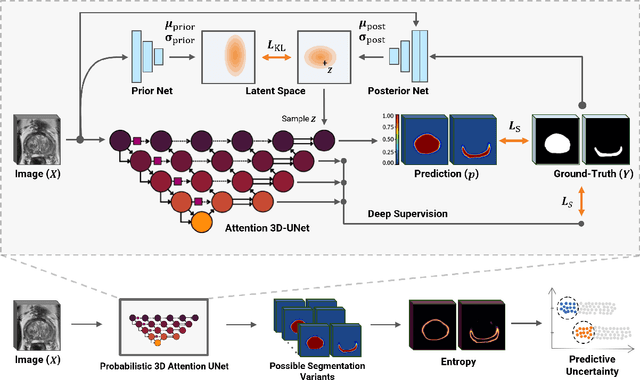
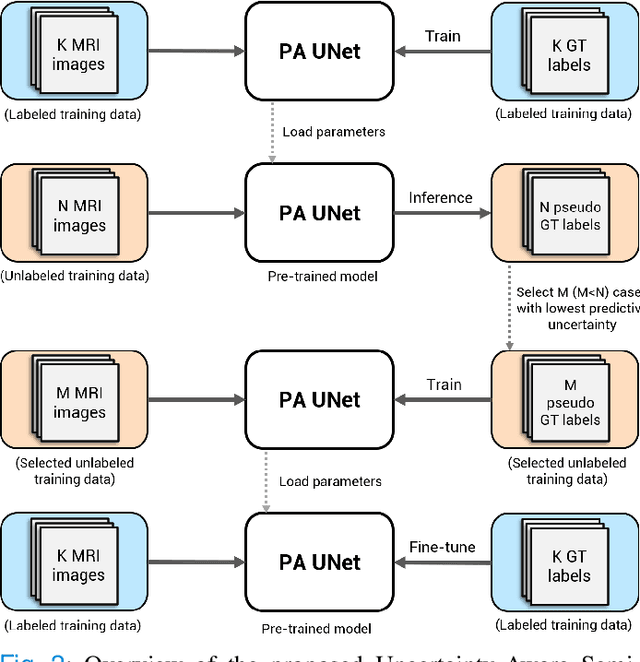
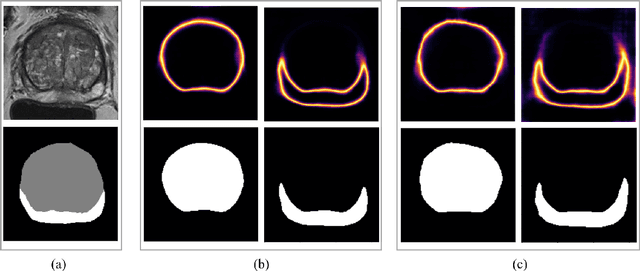
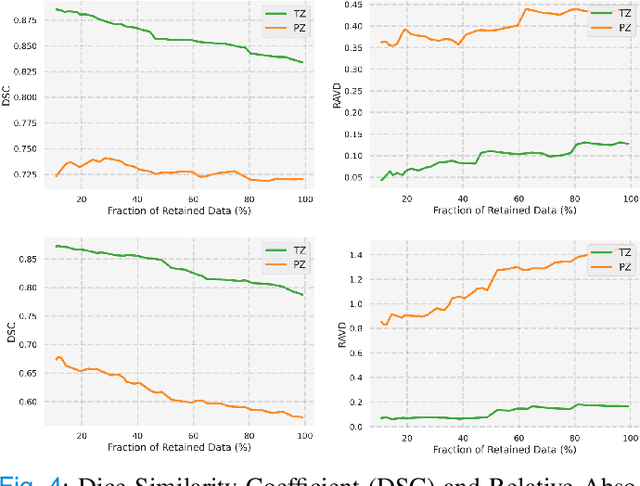
Quality of deep convolutional neural network predictions strongly depends on the size of the training dataset and the quality of the annotations. Creating annotations, especially for 3D medical image segmentation, is time-consuming and requires expert knowledge. We propose a novel semi-supervised learning (SSL) approach that requires only a relatively small number of annotations while being able to use the remaining unlabeled data to improve model performance. Our method uses a pseudo-labeling technique that employs recent deep learning uncertainty estimation models. By using the estimated uncertainty, we were able to rank pseudo-labels and automatically select the best pseudo-annotations generated by the supervised model. We applied this to prostate zonal segmentation in T2-weighted MRI scans. Our proposed model outperformed the semi-supervised model in experiments with the ProstateX dataset and an external test set, by leveraging only a subset of unlabeled data rather than the full collection of 4953 cases, our proposed model demonstrated improved performance. The segmentation dice similarity coefficient in the transition zone and peripheral zone increased from 0.835 and 0.727 to 0.852 and 0.751, respectively, for fully supervised model and the uncertainty-aware semi-supervised learning model (USSL). Our USSL model demonstrates the potential to allow deep learning models to be trained on large datasets without requiring full annotation. Our code is available at https://github.com/DIAGNijmegen/prostateMR-USSL.
Medical diffusion on a budget: textual inversion for medical image generation
Mar 23, 2023



Diffusion-based models for text-to-image generation have gained immense popularity due to recent advancements in efficiency, accessibility, and quality. Although it is becoming increasingly feasible to perform inference with these systems using consumer-grade GPUs, training them from scratch still requires access to large datasets and significant computational resources. In the case of medical image generation, the availability of large, publicly accessible datasets that include text reports is limited due to legal and ethical concerns. While training a diffusion model on a private dataset may address this issue, it is not always feasible for institutions lacking the necessary computational resources. This work demonstrates that pre-trained Stable Diffusion models, originally trained on natural images, can be adapted to various medical imaging modalities by training text embeddings with textual inversion. In this study, we conducted experiments using medical datasets comprising only 100 samples from three medical modalities. Embeddings were trained in a matter of hours, while still retaining diagnostic relevance in image generation. Experiments were designed to achieve several objectives. Firstly, we fine-tuned the training and inference processes of textual inversion, revealing that larger embeddings and more examples are required. Secondly, we validated our approach by demonstrating a 2\% increase in the diagnostic accuracy (AUC) for detecting prostate cancer on MRI, which is a challenging multi-modal imaging modality, from 0.78 to 0.80. Thirdly, we performed simulations by interpolating between healthy and diseased states, combining multiple pathologies, and inpainting to show embedding flexibility and control of disease appearance. Finally, the embeddings trained in this study are small (less than 1 MB), which facilitates easy sharing of medical data with reduced privacy concerns.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Report-Guided Automatic Lesion Annotation for Deep Learning-Based Prostate Cancer Detection in bpMRI
Dec 09, 2021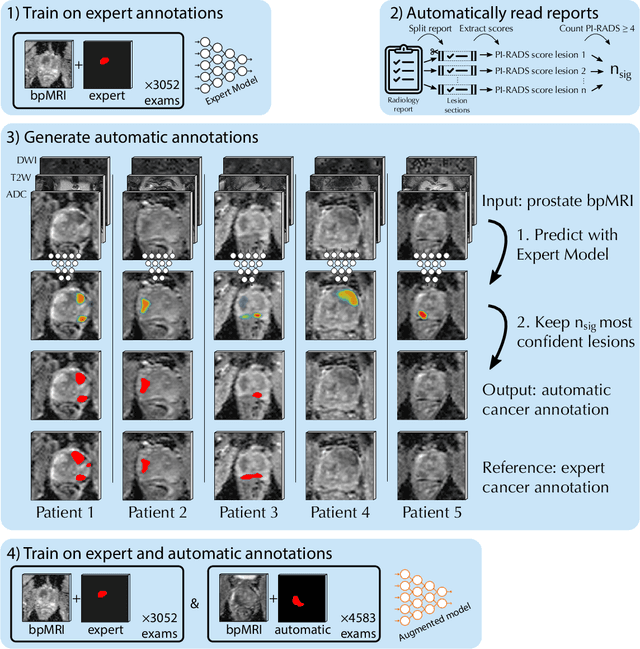

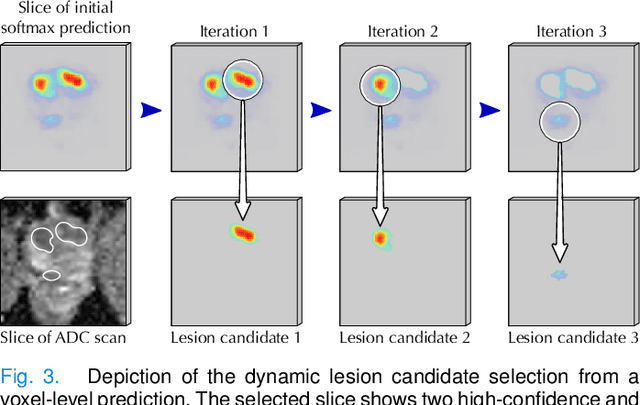
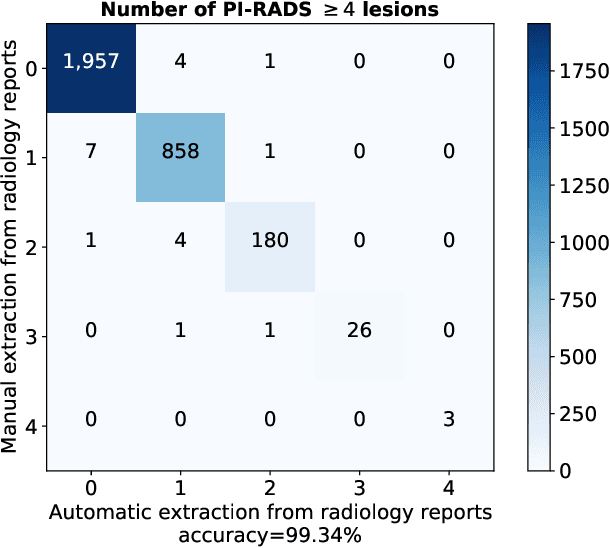
Deep learning-based diagnostic performance increases with more annotated data, but manual annotation is a bottleneck in most fields. Experts evaluate diagnostic images during clinical routine, and write their findings in reports. Automatic annotation based on clinical reports could overcome the manual labelling bottleneck. We hypothesise that dense annotations for detection tasks can be generated using model predictions, guided by sparse information from these reports. To demonstrate efficacy, we generated clinically significant prostate cancer (csPCa) annotations, guided by the number of clinically significant findings in the radiology reports. We included 7,756 prostate MRI examinations, of which 3,050 were manually annotated and 4,706 were automatically annotated. We evaluated the automatic annotation quality on the manually annotated subset: our score extraction correctly identified the number of csPCa lesions for $99.3\%$ of the reports and our csPCa segmentation model correctly localised $83.8 \pm 1.1\%$ of the lesions. We evaluated prostate cancer detection performance on 300 exams from an external centre with histopathology-confirmed ground truth. Augmenting the training set with automatically labelled exams improved patient-based diagnostic area under the receiver operating characteristic curve from $88.1\pm 1.1\%$ to $89.8\pm 1.0\%$ ($P = 1.2 \cdot 10^{-4}$) and improved lesion-based sensitivity at one false positive per case from $79.2 \pm 2.8\%$ to $85.4 \pm 1.9\%$ ($P<10^{-4}$), with $mean \pm std.$ over 15 independent runs. This improved performance demonstrates the feasibility of our report-guided automatic annotations. Source code is made publicly available at https://github.com/DIAGNijmegen/Report-Guided-Annotation. Best csPCa detection algorithm is made available at https://grand-challenge.org/algorithms/bpmri-cspca-detection-report-guided-annotations/.
Anatomical and Diagnostic Bayesian Segmentation in Prostate MRI $-$Should Different Clinical Objectives Mandate Different Loss Functions?
Oct 25, 2021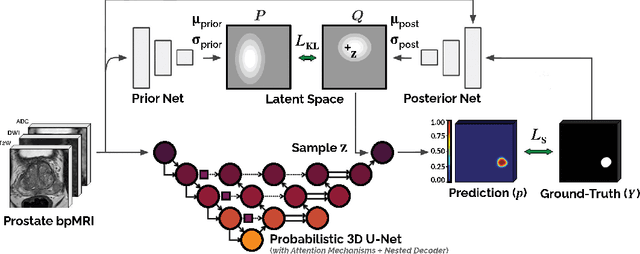
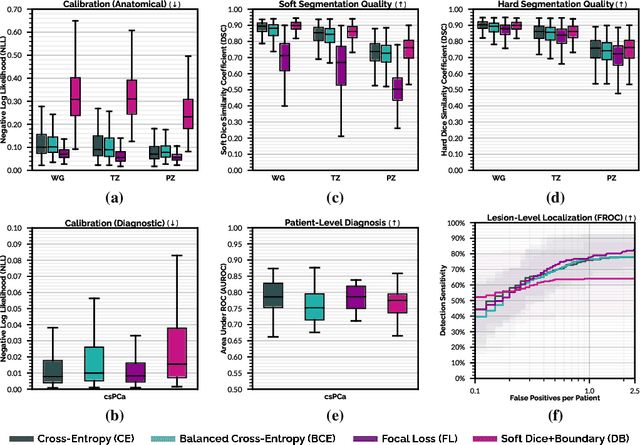
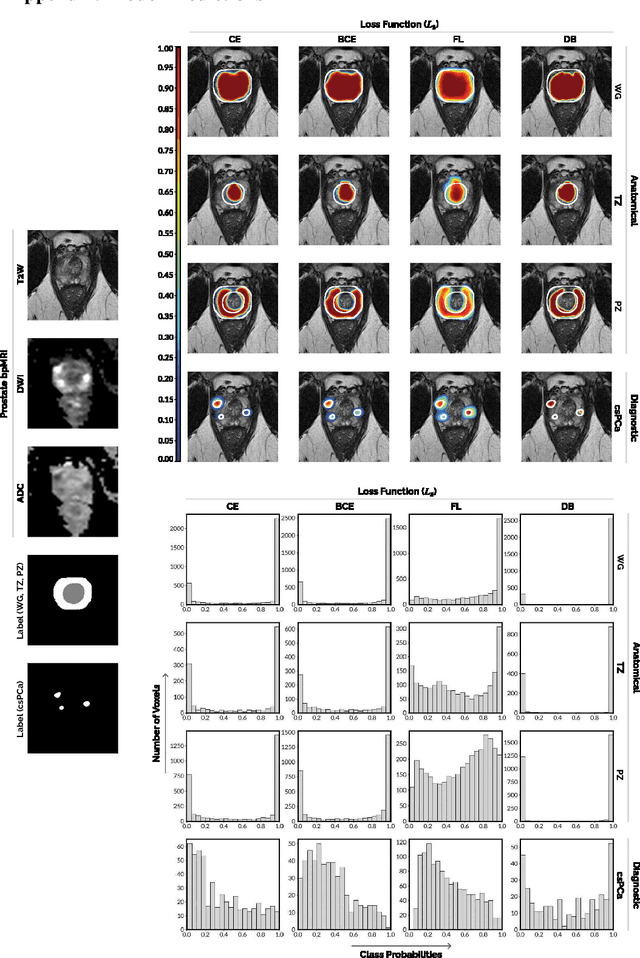
We hypothesize that probabilistic voxel-level classification of anatomy and malignancy in prostate MRI, although typically posed as near-identical segmentation tasks via U-Nets, require different loss functions for optimal performance due to inherent differences in their clinical objectives. We investigate distribution, region and boundary-based loss functions for both tasks across 200 patient exams from the publicly-available ProstateX dataset. For evaluation, we conduct a thorough comparative analysis of model predictions and calibration, measured with respect to multi-class volume segmentation of the prostate anatomy (whole-gland, transitional zone, peripheral zone), as well as, patient-level diagnosis and lesion-level detection of clinically significant prostate cancer. Notably, we find that distribution-based loss functions (in particular, focal loss) are well-suited for diagnostic or panoptic segmentation tasks such as lesion detection, primarily due to their implicit property of inducing better calibration. Meanwhile, (with the exception of focal loss) both distribution and region/boundary-based loss functions perform equally well for anatomical or semantic segmentation tasks, such as quantification of organ shape, size and boundaries.
End-to-end Prostate Cancer Detection in bpMRI via 3D CNNs: Effect of Attention Mechanisms, Clinical Priori and Decoupled False Positive Reduction
Jan 28, 2021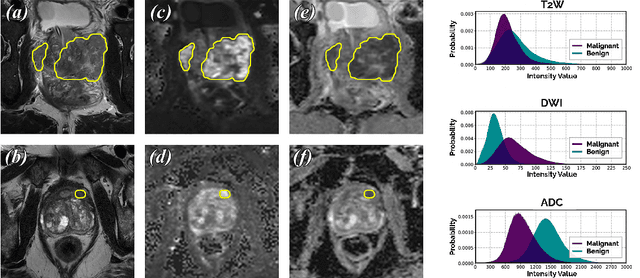

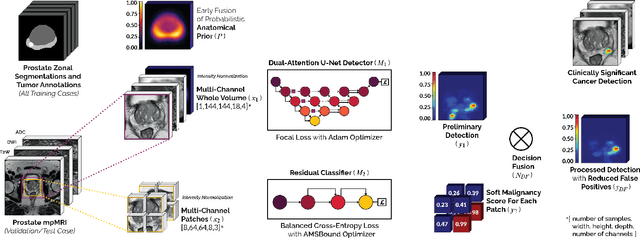
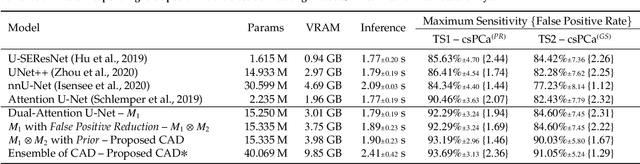
We present a novel multi-stage 3D computer-aided detection and diagnosis (CAD) model for automated localization of clinically significant prostate cancer (csPCa) in bi-parametric MR imaging (bpMRI). Deep attention mechanisms drive its detection network, targeting multi-resolution, salient structures and highly discriminative feature dimensions, in order to accurately identify csPCa lesions from indolent cancer and the wide range of benign pathology that can afflict the prostate gland. In parallel, a decoupled residual classifier is used to achieve consistent false positive reduction, without sacrificing high sensitivity or computational efficiency. Furthermore, a probabilistic anatomical prior, which captures the spatial prevalence of csPCa as well as its zonal distinction, is computed and encoded into the CNN architecture to guide model generalization with domain-specific clinical knowledge. For 486 institutional testing scans, the 3D CAD system achieves $83.69\pm5.22\%$ and $93.19\pm2.96\%$ detection sensitivity at 0.50 and 1.46 false positive(s) per patient, respectively, along with $0.882$ AUROC in patient-based diagnosis $-$significantly outperforming four state-of-the-art baseline architectures (U-SEResNet, UNet++, nnU-Net, Attention U-Net) from recent literature. For 296 external testing scans, the ensembled CAD system shares moderate agreement with a consensus of expert radiologists ($76.69\%$; $kappa=0.511$) and independent pathologists ($81.08\%$; $kappa=0.559$); demonstrating strong generalization to histologically-confirmed malignancies, despite using 1950 training-validation cases with radiologically-estimated annotations only.
Encoding Clinical Priori in 3D Convolutional Neural Networks for Prostate Cancer Detection in bpMRI
Nov 03, 2020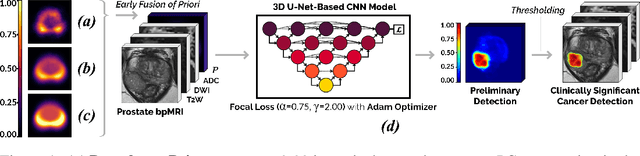
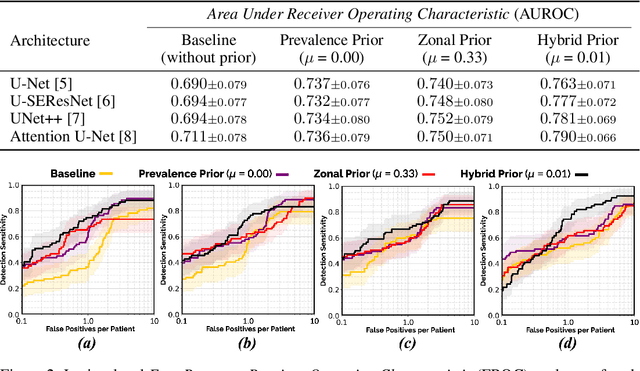
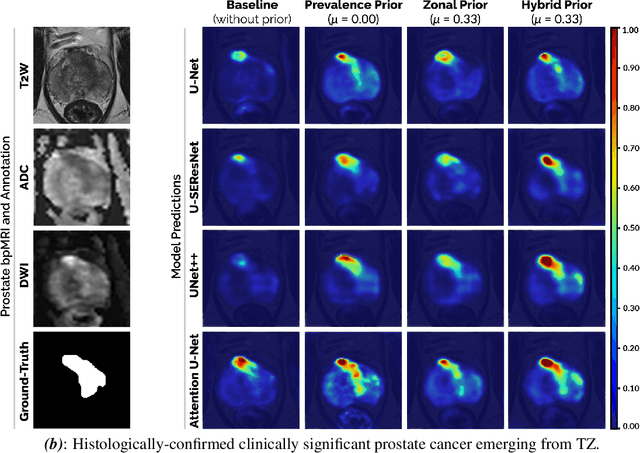
We hypothesize that anatomical priors can be viable mediums to infuse domain-specific clinical knowledge into state-of-the-art convolutional neural networks (CNN) based on the U-Net architecture. We introduce a probabilistic population prior which captures the spatial prevalence and zonal distinction of clinically significant prostate cancer (csPCa), in order to improve its computer-aided detection (CAD) in bi-parametric MR imaging (bpMRI). To evaluate performance, we train 3D adaptations of the U-Net, U-SEResNet, UNet++ and Attention U-Net using 800 institutional training-validation scans, paired with radiologically-estimated annotations and our computed prior. For 200 independent testing bpMRI scans with histologically-confirmed delineations of csPCa, our proposed method of encoding clinical priori demonstrates a strong ability to improve patient-based diagnosis (upto 8.70% increase in AUROC) and lesion-level detection (average increase of 1.08 pAUC between 0.1-1.0 false positive per patient) across all four architectures.
Weakly Supervised 3D Classification of Chest CT using Aggregated Multi-Resolution Deep Segmentation Features
Oct 31, 2020Weakly supervised disease classification of CT imaging suffers from poor localization owing to case-level annotations, where even a positive scan can hold hundreds to thousands of negative slices along multiple planes. Furthermore, although deep learning segmentation and classification models extract distinctly unique combinations of anatomical features from the same target class(es), they are typically seen as two independent processes in a computer-aided diagnosis (CAD) pipeline, with little to no feature reuse. In this research, we propose a medical classifier that leverages the semantic structural concepts learned via multi-resolution segmentation feature maps, to guide weakly supervised 3D classification of chest CT volumes. Additionally, a comparative analysis is drawn across two different types of feature aggregation to explore the vast possibilities surrounding feature fusion. Using a dataset of 1593 scans labeled on a case-level basis via rule-based model, we train a dual-stage convolutional neural network (CNN) to perform organ segmentation and binary classification of four representative diseases (emphysema, pneumonia/atelectasis, mass and nodules) in lungs. The baseline model, with separate stages for segmentation and classification, results in AUC of 0.791. Using identical hyperparameters, the connected architecture using static and dynamic feature aggregation improves performance to AUC of 0.832 and 0.851, respectively. This study advances the field in two key ways. First, case-level report data is used to weakly supervise a 3D CT classifier of multiple, simultaneous diseases for an organ. Second, segmentation and classification models are connected with two different feature aggregation strategies to enhance the classification performance.