 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelcnn
PixelCNN is a generative model that generates images pixel by pixel using a convolutional neural network.
Papers and Code
Synthetic dual image generation for reduction of labeling efforts in semantic segmentation of micrographs with a customized metric function
Aug 01, 2024Training of semantic segmentation models for material analysis requires micrographs and their corresponding masks. It is quite unlikely that perfect masks will be drawn, especially at the edges of objects, and sometimes the amount of data that can be obtained is small, since only a few samples are available. These aspects make it very problematic to train a robust model. We demonstrate a workflow for the improvement of semantic segmentation models of micrographs through the generation of synthetic microstructural images in conjunction with masks. The workflow only requires joining a few micrographs with their respective masks to create the input for a Vector Quantised-Variational AutoEncoder model that includes an embedding space, which is trained such that a generative model (PixelCNN) learns the distribution of each input, transformed into discrete codes, and can be used to sample new codes. The latter will eventually be decoded by VQ-VAE to generate images alongside corresponding masks for semantic segmentation. To evaluate the synthetic data, we have trained U-Net models with different amounts of these synthetic data in conjunction with real data. These models were then evaluated using non-synthetic images only. Additionally, we introduce a customized metric derived from the mean Intersection over Union (mIoU). The proposed metric prevents a few falsely predicted pixels from greatly reducing the value of the mIoU. We have achieved a reduction in sample preparation and acquisition times, as well as the efforts, needed for image processing and labeling tasks, are less when it comes to training semantic segmentation model. The approach could be generalized to various types of image data such that it serves as a user-friendly solution for training models with a small number of real images.
Understanding Likelihood of Normalizing Flow and Image Complexity through the Lens of Out-of-Distribution Detection
Feb 16, 2024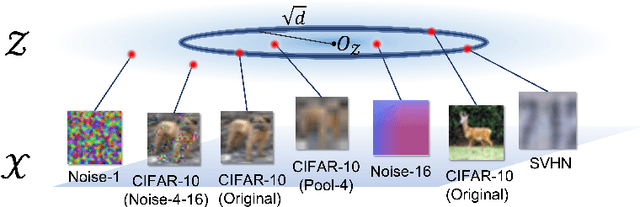
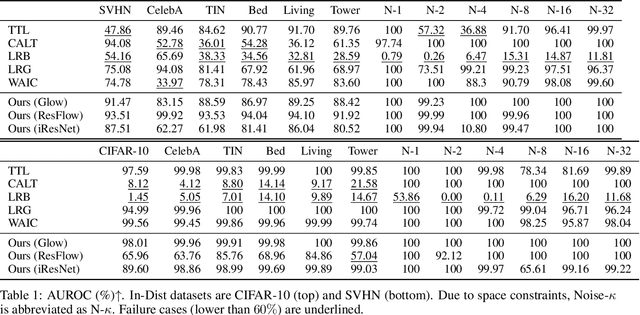

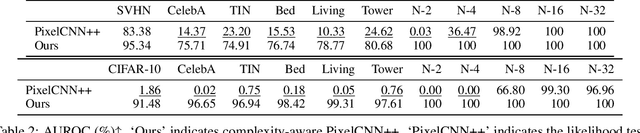
Out-of-distribution (OOD) detection is crucial to safety-critical machine learning applications and has been extensively studied. While recent studies have predominantly focused on classifier-based methods, research on deep generative model (DGM)-based methods have lagged relatively. This disparity may be attributed to a perplexing phenomenon: DGMs often assign higher likelihoods to unknown OOD inputs than to their known training data. This paper focuses on explaining the underlying mechanism of this phenomenon. We propose a hypothesis that less complex images concentrate in high-density regions in the latent space, resulting in a higher likelihood assignment in the Normalizing Flow (NF). We experimentally demonstrate its validity for five NF architectures, concluding that their likelihood is untrustworthy. Additionally, we show that this problem can be alleviated by treating image complexity as an independent variable. Finally, we provide evidence of the potential applicability of our hypothesis in another DGM, PixelCNN++.
An attempt to generate new bridge types from latent space of PixelCNN
Jan 11, 2024Try to generate new bridge types using generative artificial intelligence technology. Using symmetric structured image dataset of three-span beam bridge, arch bridge, cable-stayed bridge and suspension bridge , based on Python programming language, TensorFlow and Keras deep learning platform framework , PixelCNN is constructed and trained. The model can capture the statistical structure of the images and calculate the probability distribution of the next pixel when the previous pixels are given. From the obtained latent space sampling, new bridge types different from the training dataset can be generated. PixelCNN can organically combine different structural components on the basis of human original bridge types, creating new bridge types that have a certain degree of human original ability. Autoregressive models cannot understand the meaning of the sequence, while multimodal models combine regression and autoregressive models to understand the sequence. Multimodal models should be the way to achieve artificial general intelligence in the future.
Deep autoregressive modeling for land use land cover
Jan 02, 2024Land use / land cover (LULC) modeling is a challenging task due to long-range dependencies between geographic features and distinct spatial patterns related to topography, ecology, and human development. We identify a close connection between modeling of spatial patterns of land use and the task of image inpainting from computer vision and conduct a study of a modified PixelCNN architecture with approximately 19 million parameters for modeling LULC. In comparison with a benchmark spatial statistical model, we find that the former is capable of capturing much richer spatial correlation patterns such as roads and water bodies but does not produce a calibrated predictive distribution, suggesting the need for additional tuning. We find evidence of predictive underdispersion with regard to important ecologically-relevant land use statistics such as patch count and adjacency which can be ameliorated to some extent by manipulating sampling variability.
S-HR-VQVAE: Sequential Hierarchical Residual Learning Vector Quantized Variational Autoencoder for Video Prediction
Jul 13, 2023



We address the video prediction task by putting forth a novel model that combines (i) our recently proposed hierarchical residual vector quantized variational autoencoder (HR-VQVAE), and (ii) a novel spatiotemporal PixelCNN (ST-PixelCNN). We refer to this approach as a sequential hierarchical residual learning vector quantized variational autoencoder (S-HR-VQVAE). By leveraging the intrinsic capabilities of HR-VQVAE at modeling still images with a parsimonious representation, combined with the ST-PixelCNN's ability at handling spatiotemporal information, S-HR-VQVAE can better deal with chief challenges in video prediction. These include learning spatiotemporal information, handling high dimensional data, combating blurry prediction, and implicit modeling of physical characteristics. Extensive experimental results on the KTH Human Action and Moving-MNIST tasks demonstrate that our model compares favorably against top video prediction techniques both in quantitative and qualitative evaluations despite a much smaller model size. Finally, we boost S-HR-VQVAE by proposing a novel training method to jointly estimate the HR-VQVAE and ST-PixelCNN parameters.
Phased data augmentation for training PixelCNNs with VQ-VAE-2 and limited data
May 22, 2023With development of deep learning, researchers have developed generative models in generating realistic images. One of such generative models, a PixelCNNs model with Vector Quantized Variational AutoEncoder 2 (VQ-VAE-2), can generate more various images than other models. However, a PixelCNNs model with VQ-VAE-2, I call it PC-VQ2, requires sufficiently much training data like other deep learning models. Its practical applications are often limited in domains where collecting sufficient data is not difficult. To solve the problem, researchers have recently proposed more data-efficient methods for training generative models with limited unlabeled data from scratch. However, no such methods in PC-VQ2s have been researched. This study provides the first step in this direction, considering generation of images using PC-VQ2s and limited unlabeled data. In this study, I propose a training strategy for training a PC-VQ2 with limited data from scratch, phased data augmentation. In the strategy, ranges of parameters of data augmentation is narrowed in phases through learning. Quantitative evaluation shows that the phased data augmentation enables the model with limited data to generate images competitive with the one with sufficient data in diversity and outperforming it in fidelity. The evaluation suggests that the proposed method should be useful for training a PC-VQ2 with limited data efficiently to generate various and natural images.
Learning with MISELBO: The Mixture Cookbook
Sep 30, 2022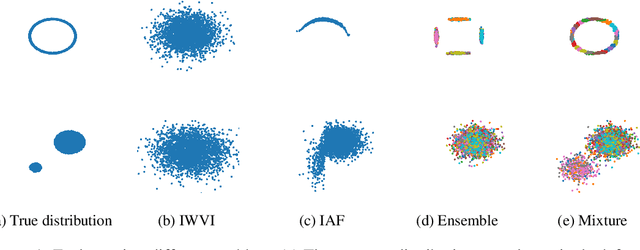
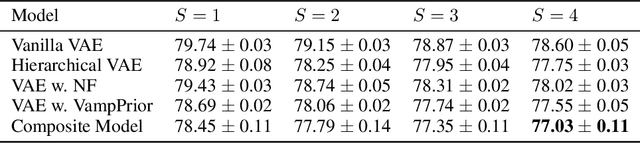

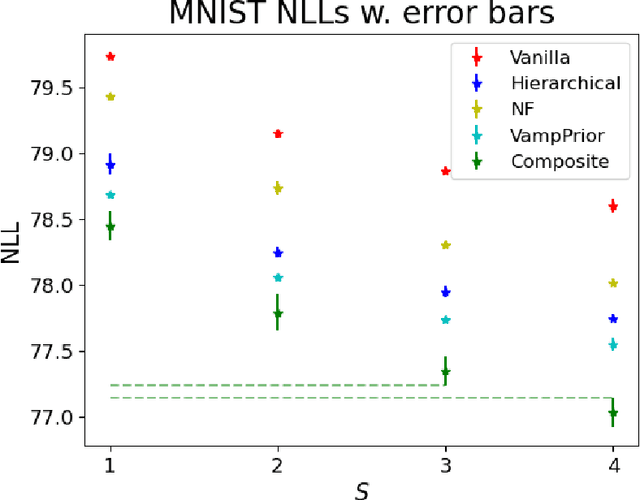
Mixture models in variational inference (VI) is an active field of research. Recent works have established their connection to multiple importance sampling (MIS) through the MISELBO and advanced the use of ensemble approximations for large-scale problems. However, as we show here, an independent learning of the ensemble components can lead to suboptimal diversity. Hence, we study the effect of instead using MISELBO as an objective function for learning mixtures, and we propose the first ever mixture of variational approximations for a normalizing flow-based hierarchical variational autoencoder (VAE) with VampPrior and a PixelCNN decoder network. Two major insights led to the construction of this novel composite model. First, mixture models have potential to be off-the-shelf tools for practitioners to obtain more flexible posterior approximations in VAEs. Therefore, we make them more accessible by demonstrating how to apply them to four popular architectures. Second, the mixture components cooperate in order to cover the target distribution while trying to maximize their diversity when MISELBO is the objective function. We explain this cooperative behavior by drawing a novel connection between VI and adaptive importance sampling. Finally, we demonstrate the superiority of the Mixture VAEs' learned feature representations on both image and single-cell transcriptome data, and obtain state-of-the-art results among VAE architectures in terms of negative log-likelihood on the MNIST and FashionMNIST datasets. Code available here: \url{https://github.com/Lagergren-Lab/MixtureVAEs}.
Shaken, and Stirred: Long-Range Dependencies Enable Robust Outlier Detection with PixelCNN++
Aug 29, 2022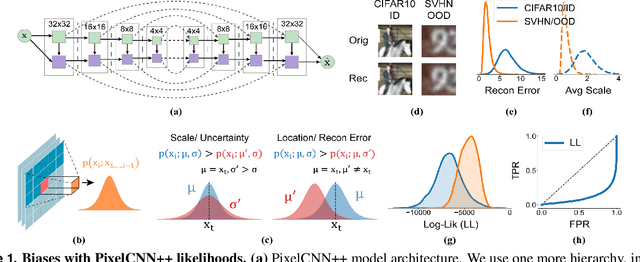
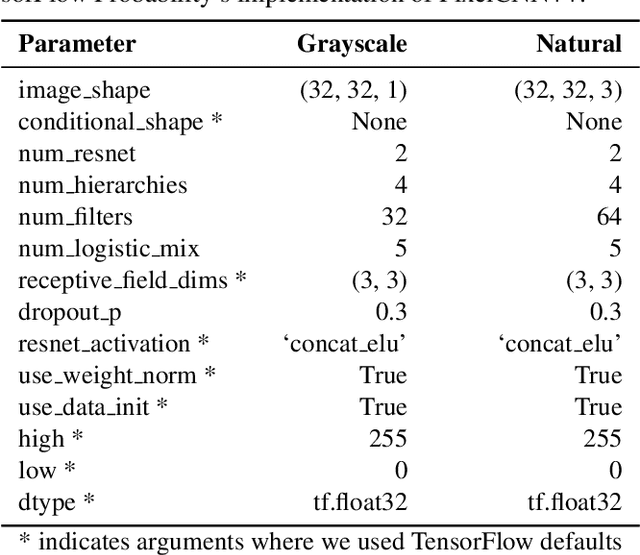
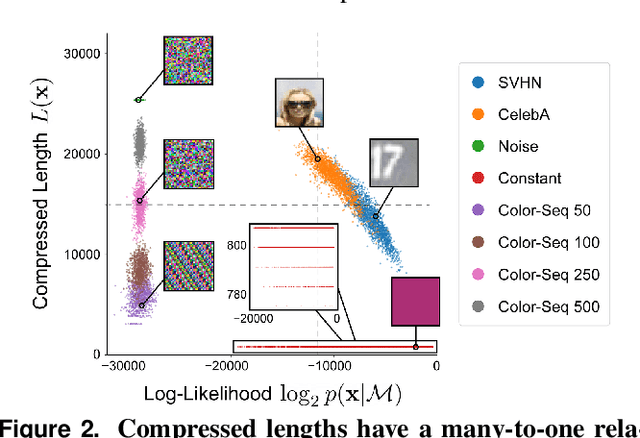
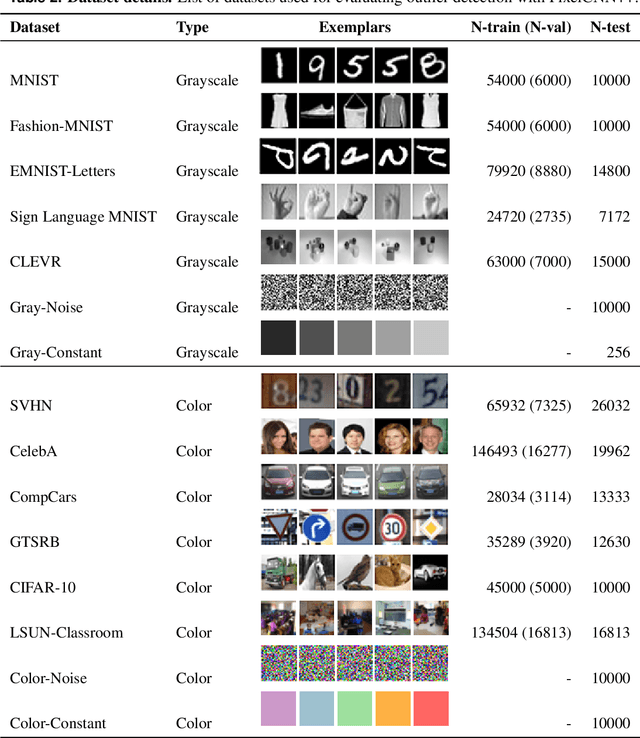
Reliable outlier detection is critical for real-world applications of deep learning models. Likelihoods produced by deep generative models, although extensively studied, have been largely dismissed as being impractical for outlier detection. For one, deep generative model likelihoods are readily biased by low-level input statistics. Second, many recent solutions for correcting these biases are computationally expensive or do not generalize well to complex, natural datasets. Here, we explore outlier detection with a state-of-the-art deep autoregressive model: PixelCNN++. We show that biases in PixelCNN++ likelihoods arise primarily from predictions based on local dependencies. We propose two families of bijective transformations that we term "shaking" and "stirring", which ameliorate low-level biases and isolate the contribution of long-range dependencies to the PixelCNN++ likelihood. These transformations are computationally inexpensive and readily applied at evaluation time. We evaluate our approaches extensively with five grayscale and six natural image datasets and show that they achieve or exceed state-of-the-art outlier detection performance. In sum, lightweight remedies suffice to achieve robust outlier detection on images with deep generative models.
Multi-Scale Architectures Matter: On the Adversarial Robustness of Flow-based Lossless Compression
Aug 26, 2022



As a probabilistic modeling technique, the flow-based model has demonstrated remarkable potential in the field of lossless compression \cite{idf,idf++,lbb,ivpf,iflow},. Compared with other deep generative models (eg. Autoregressive, VAEs) \cite{bitswap,hilloc,pixelcnn++,pixelsnail} that explicitly model the data distribution probabilities, flow-based models perform better due to their excellent probability density estimation and satisfactory inference speed. In flow-based models, multi-scale architecture provides a shortcut from the shallow layer to the output layer, which significantly reduces the computational complexity and avoid performance degradation when adding more layers. This is essential for constructing an advanced flow-based learnable bijective mapping. Furthermore, the lightweight requirement of the model design in practical compression tasks suggests that flows with multi-scale architecture achieve the best trade-off between coding complexity and compression efficiency.
Out-of-distribution Detection via Frequency-regularized Generative Models
Aug 18, 2022
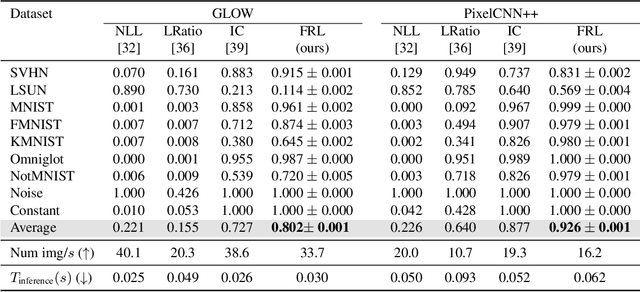

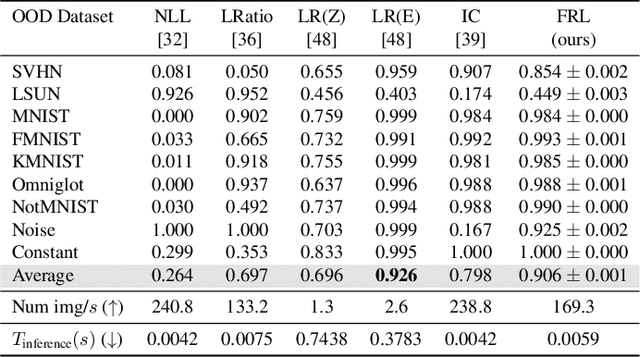
Modern deep generative models can assign high likelihood to inputs drawn from outside the training distribution, posing threats to models in open-world deployments. While much research attention has been placed on defining new test-time measures of OOD uncertainty, these methods do not fundamentally change how deep generative models are regularized and optimized in training. In particular, generative models are shown to overly rely on the background information to estimate the likelihood. To address the issue, we propose a novel frequency-regularized learning FRL framework for OOD detection, which incorporates high-frequency information into training and guides the model to focus on semantically relevant features. FRL effectively improves performance on a wide range of generative architectures, including variational auto-encoder, GLOW, and PixelCNN++. On a new large-scale evaluation task, FRL achieves the state-of-the-art performance, outperforming a strong baseline Likelihood Regret by 10.7% (AUROC) while achieving 147$\times$ faster inference speed. Extensive ablations show that FRL improves the OOD detection performance while preserving the image generation quality. Code is available at https://github.com/mu-cai/FRL.