 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemosaicking
Demosaicking is the process of reconstructing a full-color image from a single-sensor digital camera that captures color information using a color filter array.
Papers and Code
Frequency Enhancement for Image Demosaicking
Mar 20, 2025Recovering high-frequency textures in image demosaicking remains a challenging issue. While existing methods introduced elaborate spatial learning methods, they still exhibit limited performance. To address this issue, a frequency enhancement approach is proposed. Based on the frequency analysis of color filter array (CFA)/demosaicked/ground truth images, we propose Dual-path Frequency Enhancement Network (DFENet), which reconstructs RGB images in a divide-and-conquer manner through fourier-domain frequency selection. In DFENet, two frequency selectors are employed, each selecting a set of frequency components for processing along separate paths. One path focuses on generating missing information through detail refinement in spatial domain, while the other aims at suppressing undesirable frequencies with the guidance of CFA images in frequency domain. Multi-level frequency supervision with a stagewise training strategy is employed to further improve the reconstruction performance. With these designs, the proposed DFENet outperforms other state-of-the-art algorithms on different datasets and demonstrates significant advantages on hard cases. Moreover, to better assess algorithms' ability to reconstruct high-frequency textures, a new dataset, LineSet37, is contributed, which consists of 37 artificially designed and generated images. These images feature complex line patterns and are prone to severe visual artifacts like color moir\'e after demosaicking. Experiments on LineSet37 offer a more targeted evaluation of performance on challenging cases. The code and dataset are available at https://github.com/VelvetReverie/DFENet-demosaicking.
Combining Pre- and Post-Demosaicking Noise Removal for RAW Video
Oct 03, 2024
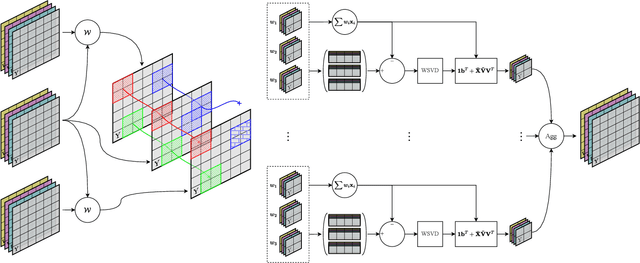


Denoising is one of the fundamental steps of the processing pipeline that converts data captured by a camera sensor into a display-ready image or video. It is generally performed early in the pipeline, usually before demosaicking, although studies swapping their order or even conducting them jointly have been proposed. With the advent of deep learning, the quality of denoising algorithms has steadily increased. Even so, modern neural networks still have a hard time adapting to new noise levels and scenes, which is indispensable for real-world applications. With those in mind, we propose a self-similarity-based denoising scheme that weights both a pre- and a post-demosaicking denoiser for Bayer-patterned CFA video data. We show that a balance between the two leads to better image quality, and we empirically find that higher noise levels benefit from a higher influence pre-demosaicking. We also integrate temporal trajectory prefiltering steps before each denoiser, which further improve texture reconstruction. The proposed method only requires an estimation of the noise model at the sensor, accurately adapts to any noise level, and is competitive with the state of the art, making it suitable for real-world videography.
Efficient Polarization Demosaicking via Low-cost Edge-aware and Inter-channel Correlation
Aug 30, 2024



Efficient and high-fidelity polarization demosaicking is critical for industrial applications of the division of focal plane (DoFP) polarization imaging systems. However, existing methods have an unsatisfactory balance of speed, accuracy, and complexity. This study introduces a novel polarization demosaicking algorithm that interpolates within a three-stage basic demosaicking framework to obtain DoFP images. Our method incorporates a DoFP low-cost edge-aware technique (DLE) to guide the interpolation process. Furthermore, the inter-channel correlation is used to calibrate the initial estimate in the polarization difference domain. The proposed algorithm is available in both a lightweight and a full version, tailored to different application requirements. Experiments on simulated and real DoFP images demonstrate that our two methods have the highest interpolation accuracy and speed, respectively, and significantly enhance the visuals. Both versions efficiently process a 1024*1024 image on an AMD Ryzen 5600X CPU in 0.1402s and 0.2693s, respectively. Additionally, since our methods only involve computational processes within a 5*5 window, the potential for parallel acceleration on GPUs or FPGAs is highly feasible.
A self-supervised and adversarial approach to hyperspectral demosaicking and RGB reconstruction in surgical imaging
Jul 27, 2024



Hyperspectral imaging holds promises in surgical imaging by offering biological tissue differentiation capabilities with detailed information that is invisible to the naked eye. For intra-operative guidance, real-time spectral data capture and display is mandated. Snapshot mosaic hyperspectral cameras are currently seen as the most suitable technology given this requirement. However, snapshot mosaic imaging requires a demosaicking algorithm to fully restore the spatial and spectral details in the images. Modern demosaicking approaches typically rely on synthetic datasets to develop supervised learning methods, as it is practically impossible to simultaneously capture both snapshot and high-resolution spectral images of the exact same surgical scene. In this work, we present a self-supervised demosaicking and RGB reconstruction method that does not depend on paired high-resolution data as ground truth. We leverage unpaired standard high-resolution surgical microscopy images, which only provide RGB data but can be collected during routine surgeries. Adversarial learning complemented by self-supervised approaches are used to drive our hyperspectral-based RGB reconstruction into resembling surgical microscopy images and increasing the spatial resolution of our demosaicking. The spatial and spectral fidelity of the reconstructed hyperspectral images have been evaluated quantitatively. Moreover, a user study was conducted to evaluate the RGB visualisation generated from these spectral images. Both spatial detail and colour accuracy were assessed by neurosurgical experts. Our proposed self-supervised demosaicking method demonstrates improved results compared to existing methods, demonstrating its potential for seamless integration into intra-operative workflows.
Deep convolutional demosaicking network for multispectral polarization filter array
Jun 08, 2024To address the demosaicking problem in multispectral polarization filter array (MSPFA) imaging, we propose a multispectral polarization demosaicking network (MSPDNet) that improves image reconstruction accuracy. Imaging with a multispectral polarization filter array acquires multispectral polarization information in a snapshot. The full-resolution multispectral polarization image must be reconstructed from a mosaic image. In the proposed method, a sparse image in which pixel values of the same channel are extracted from a mosaic image is used as input to MSPDNet. Missing pixels are interpolated by learning spatial and wavelength correlations from the observed pixels in the mosaic image. Moreover, by using 3D convolution, features are extracted at each convolution layer, and by deepening the network, even detailed features of the multispectral polarization image can be learned. Experimental results show that MSPDNet can reconstruct multi-wavelength and multi-polarization angle information with high accuracy in terms of peak signal-to-noise ratio (PSNR) evaluation and visual quality, indicating the effectiveness of the proposed method compared to other methods.
Toward Accurate and Temporally Consistent Video Restoration from Raw Data
Dec 25, 2023Denoising and demosaicking are two fundamental steps in reconstructing a clean full-color video from raw data, while performing video denoising and demosaicking jointly, namely VJDD, could lead to better video restoration performance than performing them separately. In addition to restoration accuracy, another key challenge to VJDD lies in the temporal consistency of consecutive frames. This issue exacerbates when perceptual regularization terms are introduced to enhance video perceptual quality. To address these challenges, we present a new VJDD framework by consistent and accurate latent space propagation, which leverages the estimation of previous frames as prior knowledge to ensure consistent recovery of the current frame. A data temporal consistency (DTC) loss and a relational perception consistency (RPC) loss are accordingly designed. Compared with the commonly used flow-based losses, the proposed losses can circumvent the error accumulation problem caused by inaccurate flow estimation and effectively handle intensity changes in videos, improving much the temporal consistency of output videos while preserving texture details. Extensive experiments demonstrate the leading VJDD performance of our method in term of restoration accuracy, perceptual quality and temporal consistency. Codes and dataset are available at \url{https://github.com/GuoShi28/VJDD}.
Iterative Reweighted Least Squares Networks With Convergence Guarantees for Solving Inverse Imaging Problems
Aug 10, 2023



In this work we present a novel optimization strategy for image reconstruction tasks under analysis-based image regularization, which promotes sparse and/or low-rank solutions in some learned transform domain. We parameterize such regularizers using potential functions that correspond to weighted extensions of the $\ell_p^p$-vector and $\mathcal{S}_p^p$ Schatten-matrix quasi-norms with $0 < p \le 1$. Our proposed minimization strategy extends the Iteratively Reweighted Least Squares (IRLS) method, typically used for synthesis-based $\ell_p$ and $\mathcal{S}_p$ norm and analysis-based $\ell_1$ and nuclear norm regularization. We prove that under mild conditions our minimization algorithm converges linearly to a stationary point, and we provide an upper bound for its convergence rate. Further, to select the parameters of the regularizers that deliver the best results for the problem at hand, we propose to learn them from training data by formulating the supervised learning process as a stochastic bilevel optimization problem. We show that thanks to the convergence guarantees of our proposed minimization strategy, such optimization can be successfully performed with a memory-efficient implicit back-propagation scheme. We implement our learned IRLS variants as recurrent networks and assess their performance on the challenging image reconstruction tasks of non-blind deblurring, super-resolution and demosaicking. The comparisons against other existing learned reconstruction approaches demonstrate that our overall method is very competitive and in many cases outperforms existing unrolled networks, whose number of parameters is orders of magnitude higher than in our case.
Twice Binnable Color Filter Arrays
Jun 29, 2023Pixel binning enables high speed, low power readout in low resolution modes, and more importantly, a reduction of read noise via floating diffusion binning. New, high resolution CMOS image sensors for mobile phones have moved beyond the once-binnable Quad Bayer and RGBW-Kodak patterns to the twice binnable Hexadeca Bayer pattern featuring 4x4 tiles of like colored pixels.Pixel binning enables high speed, low power readout in low resolution modes, and more importantly, a reduction of read noise via floating diffusion binning. New, high resolution CMOS image sensors for mobile phones have moved beyond the once-binnable Quad Bayer and RGBW-Kodak patterns to the twice binnable Hexadeca Bayer pattern featuring 4x4 tiles of like colored pixels. In this paper we present the non-intuitive result that Nona and Hexadeca Bayer can be superior to Quad Bayer in demosaicking quality due to degeneracies in the latter's spectrum. Hexadeca Bayer, nevertheless, suffers from the weakness of generating Quad Bayer after one round of binning. We present a novel twice binnable RGBW CFA, composed of 2x2 tiles capable of 4:1 floating diffusion binning, that is free from spectral degeneracies and thus demosaick well in full resolution and both binned modes. It also has a 4 dB low light SNR advantage over Quad and Hexadeca Bayer in the full resolution mode, and 6 dB SNR advantage in both the binned modes.
Model-based demosaicking for acquisitions by a RGBW color filter array
Jun 02, 2023Microsatellites and drones are often equipped with digital cameras whose sensing system is based on color filter arrays (CFAs), which define a pattern of color filter overlaid over the focal plane. Recent commercial cameras have started implementing RGBW patterns, which include some filters with a wideband spectral response together with the more classical RGB ones. This allows for additional light energy to be captured by the relevant pixels and increases the overall SNR of the acquisition. Demosaicking defines reconstructing a multi-spectral image from the raw image and recovering the full color components for all pixels. However, this operation is often tailored for the most widespread patterns, such as the Bayer pattern. Consequently, less common patterns that are still employed in commercial cameras are often neglected. In this work, we present a generalized framework to represent the image formation model of such cameras. This model is then exploited by our proposed demosaicking algorithm to reconstruct the datacube of interest with a Bayesian approach, using a total variation regularizer as prior. Some preliminary experimental results are also presented, which apply to the reconstruction of acquisitions of various RGBW cameras.
Toward Moiré-Free and Detail-Preserving Demosaicking
May 15, 2023
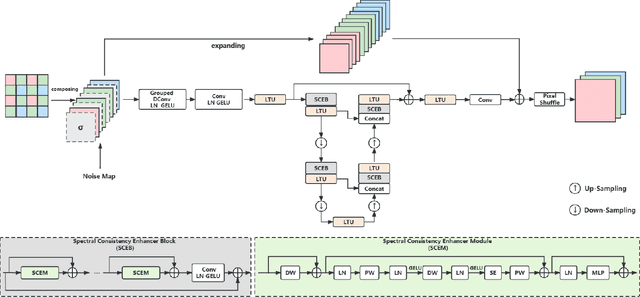


3D convolutions are commonly employed by demosaicking neural models, in the same way as solving other image restoration problems. Counter-intuitively, we show that 3D convolutions implicitly impede the RGB color spectra from exchanging complementary information, resulting in spectral-inconsistent inference of the local spatial high frequency components. As a consequence, shallow 3D convolution networks suffer the Moir\'e artifacts, but deep 3D convolutions cause over-smoothness. We analyze the fundamental difference between demosaicking and other problems that predict lost pixels between available ones (e.g., super-resolution reconstruction), and present the underlying reasons for the confliction between Moir\'e-free and detail-preserving. From the new perspective, our work decouples the common standard convolution procedure to spectral and spatial feature aggregations, which allow strengthening global communication in the spectral dimension while respecting local contrast in the spatial dimension. We apply our demosaicking model to two tasks: Joint Demosaicking-Denoising and Independently Demosaicking. In both applications, our model substantially alleviates artifacts such as Moir\'e and over-smoothness at similar or lower computational cost to currently top-performing models, as validated by diverse evaluations. Source code will be released along with paper publication.