 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-supervised and adversarial approach to hyperspectral demosaicking and RGB reconstruction in surgical imaging
Jul 27, 2024



Hyperspectral imaging holds promises in surgical imaging by offering biological tissue differentiation capabilities with detailed information that is invisible to the naked eye. For intra-operative guidance, real-time spectral data capture and display is mandated. Snapshot mosaic hyperspectral cameras are currently seen as the most suitable technology given this requirement. However, snapshot mosaic imaging requires a demosaicking algorithm to fully restore the spatial and spectral details in the images. Modern demosaicking approaches typically rely on synthetic datasets to develop supervised learning methods, as it is practically impossible to simultaneously capture both snapshot and high-resolution spectral images of the exact same surgical scene. In this work, we present a self-supervised demosaicking and RGB reconstruction method that does not depend on paired high-resolution data as ground truth. We leverage unpaired standard high-resolution surgical microscopy images, which only provide RGB data but can be collected during routine surgeries. Adversarial learning complemented by self-supervised approaches are used to drive our hyperspectral-based RGB reconstruction into resembling surgical microscopy images and increasing the spatial resolution of our demosaicking. The spatial and spectral fidelity of the reconstructed hyperspectral images have been evaluated quantitatively. Moreover, a user study was conducted to evaluate the RGB visualisation generated from these spectral images. Both spatial detail and colour accuracy were assessed by neurosurgical experts. Our proposed self-supervised demosaicking method demonstrates improved results compared to existing methods, demonstrating its potential for seamless integration into intra-operative workflows.
Spatial gradient consistency for unsupervised learning of hyperspectral demosaicking: Application to surgical imaging
Feb 21, 2023Hyperspectral imaging has the potential to improve intraoperative decision making if tissue characterisation is performed in real-time and with high-resolution. Hyperspectral snapshot mosaic sensors offer a promising approach due to their fast acquisition speed and compact size. However, a demosaicking algorithm is required to fully recover the spatial and spectral information of the snapshot images. Most state-of-the-art demosaicking algorithms require ground-truth training data with paired snapshot and high-resolution hyperspectral images, but such imagery pairs with the exact same scene are physically impossible to acquire in intraoperative settings. In this work, we present a fully unsupervised hyperspectral image demosaicking algorithm which only requires exemplar snapshot images for training purposes. We regard hyperspectral demosaicking as an ill-posed linear inverse problem which we solve using a deep neural network. We take advantage of the spectral correlation occurring in natural scenes to design a novel inter spectral band regularisation term based on spatial gradient consistency. By combining our proposed term with standard regularisation techniques and exploiting a standard data fidelity term, we obtain an unsupervised loss function for training deep neural networks, which allows us to achieve real-time hyperspectral image demosaicking. Quantitative results on hyperspetral image datasets show that our unsupervised demosaicking approach can achieve similar performance to its supervised counter-part, and significantly outperform linear demosaicking. A qualitative user study on real snapshot hyperspectral surgical images confirms the results from the quantitative analysis. Our results suggest that the proposed unsupervised algorithm can achieve promising hyperspectral demosaicking in real-time thus advancing the suitability of the modality for intraoperative use.
Deep Learning Approach for Hyperspectral Image Demosaicking, Spectral Correction and High-resolution RGB Reconstruction
Sep 03, 2021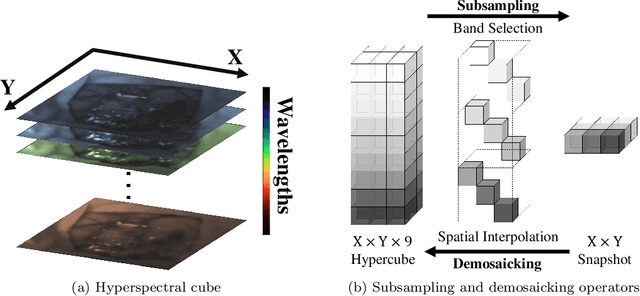

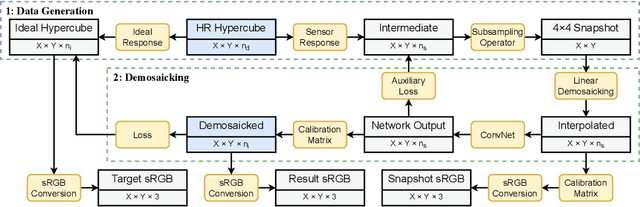
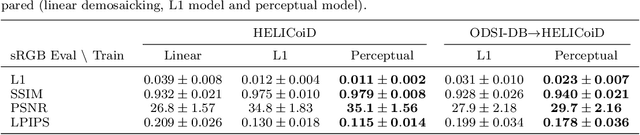
Hyperspectral imaging is one of the most promising techniques for intraoperative tissue characterisation. Snapshot mosaic cameras, which can capture hyperspectral data in a single exposure, have the potential to make a real-time hyperspectral imaging system for surgical decision-making possible. However, optimal exploitation of the captured data requires solving an ill-posed demosaicking problem and applying additional spectral corrections to recover spatial and spectral information of the image. In this work, we propose a deep learning-based image demosaicking algorithm for snapshot hyperspectral images using supervised learning methods. Due to the lack of publicly available medical images acquired with snapshot mosaic cameras, a synthetic image generation approach is proposed to simulate snapshot images from existing medical image datasets captured by high-resolution, but slow, hyperspectral imaging devices. Image reconstruction is achieved using convolutional neural networks for hyperspectral image super-resolution, followed by cross-talk and leakage correction using a sensor-specific calibration matrix. The resulting demosaicked images are evaluated both quantitatively and qualitatively, showing clear improvements in image quality compared to a baseline demosaicking method using linear interpolation. Moreover, the fast processing time of~45\,ms of our algorithm to obtain super-resolved RGB or oxygenation saturation maps per image frame for a state-of-the-art snapshot mosaic camera demonstrates the potential for its seamless integration into real-time surgical hyperspectral imaging applications.
Instantiation-Net: 3D Mesh Reconstruction from Single 2D Image for Right Ventricle
Sep 16, 2019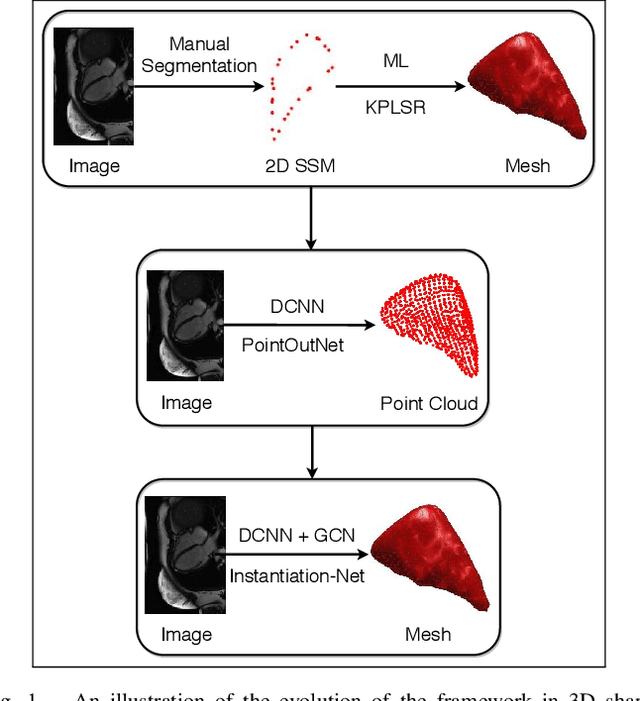



3D shape instantiation which reconstructs the 3D shape of a target from limited 2D images or projections is an emerging technique for surgical intervention. It improves the currently less-informative and insufficient 2D navigation schemes for robot-assisted Minimally Invasive Surgery (MIS) to 3D navigation. Previously, a general and registration-free framework was proposed for 3D shape instantiation based on Kernel Partial Least Square Regression (KPLSR), requiring manually segmented anatomical structures as the pre-requisite. Two hyper-parameters including the Gaussian width and component number also need to be carefully adjusted. Deep Convolutional Neural Network (DCNN) based framework has also been proposed to reconstruct a 3D point cloud from a single 2D image, with end-to-end and fully automatic learning. In this paper, an Instantiation-Net is proposed to reconstruct the 3D mesh of a target from its a single 2D image, by using DCNN to extract features from the 2D image and Graph Convolutional Network (GCN) to reconstruct the 3D mesh, and using Fully Connected (FC) layers to connect the DCNN to GCN. Detailed validation was performed to demonstrate the practical strength of the method and its potential clinical use.
Z-Net: an Asymmetric 3D DCNN for Medical CT Volume Segmentation
Sep 16, 2019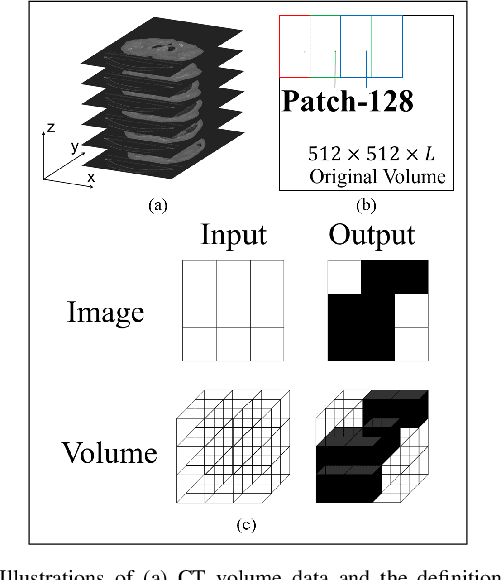
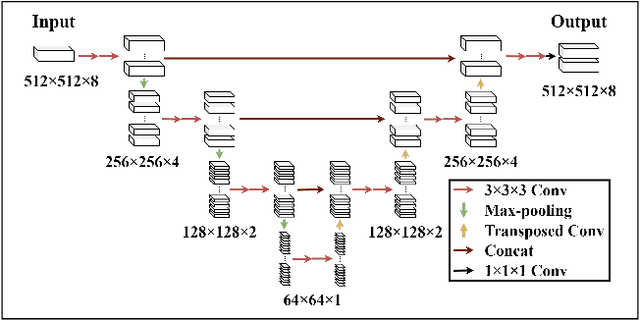
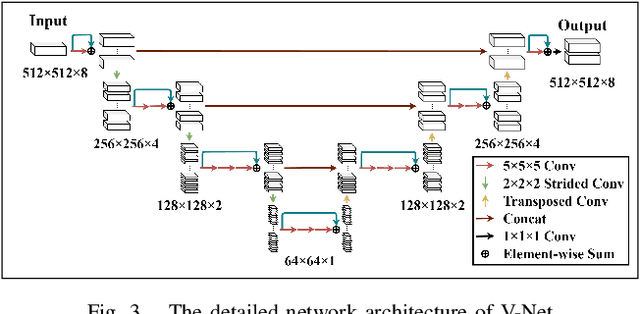
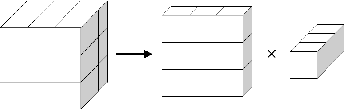
Accurate volume segmentation from the Computed Tomography (CT) scan is a common prerequisite for pre-operative planning, intra-operative guidance and quantitative assessment of therapeutic outcomes in robot-assisted Minimally Invasive Surgery (MIS). The use of 3D Deep Convolutional Neural Network (DCNN) is a viable solution for this task but is memory intensive. The use of patch division can mitigate this issue in practice, but can cause discontinuities between the adjacent patches and severe class-imbalances within individual sub-volumes. This paper presents a new patch division approach - Patch-512 to tackle the class-imbalance issue by preserving a full field-of-view of the objects in the XY planes. To achieve better segmentation results based on these asymmetric patches, a 3D DCNN architecture using asymmetrical separable convolutions is proposed. The proposed network, called Z-Net, can be seamlessly integrated into existing 3D DCNNs such as 3D U-Net and V-Net, for improved volume segmentation. Detailed validation of the method is provided for CT aortic, liver and lung segmentation, demonstrating the effectiveness and practical value of the method for intra-operative 3D navigation in robot-assisted MIS.
U-Net Training with Instance-Layer Normalization
Aug 25, 2019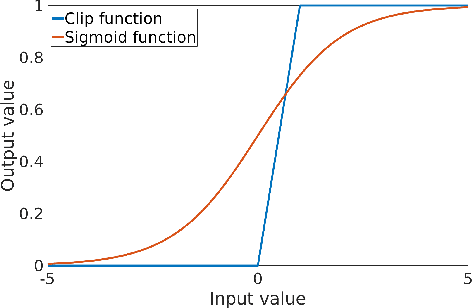


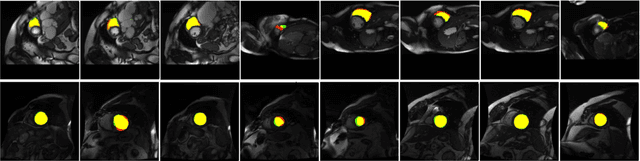
Normalization layers are essential in a Deep Convolutional Neural Network (DCNN). Various normalization methods have been proposed. The statistics used to normalize the feature maps can be computed at batch, channel, or instance level. However, in most of existing methods, the normalization for each layer is fixed. Batch-Instance Normalization (BIN) is one of the first proposed methods that combines two different normalization methods and achieve diverse normalization for different layers. However, two potential issues exist in BIN: first, the Clip function is not differentiable at input values of 0 and 1; second, the combined feature map is not with a normalized distribution which is harmful for signal propagation in DCNN. In this paper, an Instance-Layer Normalization (ILN) layer is proposed by using the Sigmoid function for the feature map combination, and cascading group normalization. The performance of ILN is validated on image segmentation of the Right Ventricle (RV) and Left Ventricle (LV) using U-Net as the network architecture. The results show that the proposed ILN outperforms previous traditional and popular normalization methods with noticeable accuracy improvements for most validations, supporting the effectiveness of the proposed ILN.
One-stage Shape Instantiation from a Single 2D Image to 3D Point Cloud
Jul 24, 2019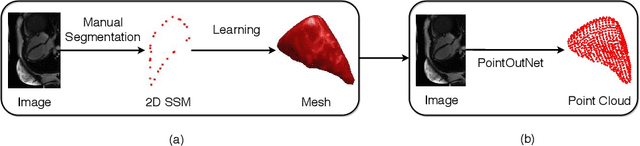
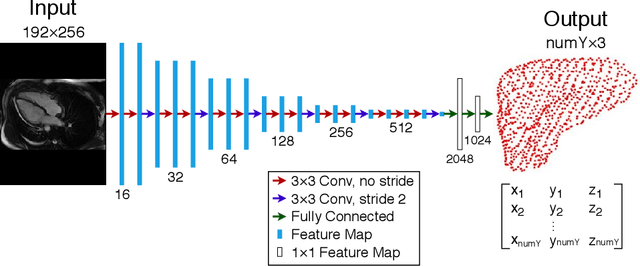
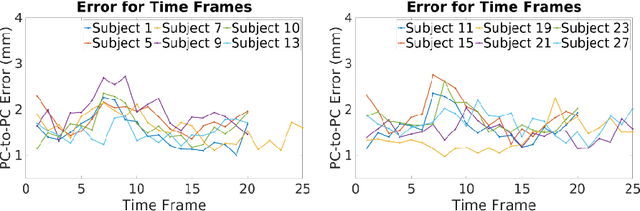
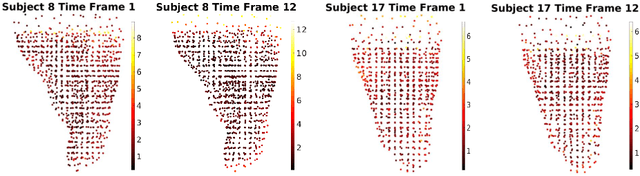
Shape instantiation which predicts the 3D shape of a dynamic target from one or more 2D images is important for real-time intra-operative navigation. Previously, a general shape instantiation framework was proposed with manual image segmentation to generate a 2D Statistical Shape Model (SSM) and with Kernel Partial Least Square Regression (KPLSR) to learn the relationship between the 2D and 3D SSM for 3D shape prediction. In this paper, the two-stage shape instantiation is improved to be one-stage. PointOutNet with 19 convolutional layers and three fully-connected layers is used as the network structure and Chamfer distance is used as the loss function to predict the 3D target point cloud from a single 2D image. With the proposed one-stage shape instantiation algorithm, a spontaneous image-to-point cloud training and inference can be achieved. A dataset from 27 Right Ventricle (RV) subjects, indicating 609 experiments, were used to validate the proposed one-stage shape instantiation algorithm. An average point cloud-to-point cloud (PC-to-PC) error of 1.72mm has been achieved, which is comparable to the PLSR-based (1.42mm) and KPLSR-based (1.31mm) two-stage shape instantiation algorithm.